







作者将图像描述任务看做一个多模态的翻译任务,利用序列到序列的递归神经网络进行学习。和之前工作不同的是,之前图像一般使用卷积神经网络进行表达,而作者提出一种不同的方法,首先检测图像中可能的物体序列,然后作为RNN的输入。通过该种方式,可以将物体序列转化为单词序列。为了更好地利用的利用视觉信息,作者提出了一种序列注意层,通过该层,可以更好的建立物体和生成单词之间的关系,使得在生成单词的过程中,可以有选择的利用物体特征。其中在MS COCO数据集上,在线评测结果为CIDEr 1.029(c5)和1.064(c40).
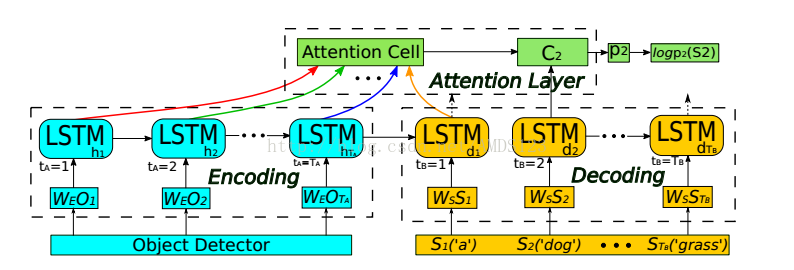
模型总体架构如上图所示,主要包括编码模块,解码模块和注意层。源序列通过物体特征嵌入到隐藏空间进行表达,目标序列是嵌入到相同空间的单词序列。Attention layer用所有编码隐藏单元和解码隐藏单元来计算上下文向量。
源序列表达。作者使用物体检测器来定位物体,然后提取D维的CNN特征。然后通过嵌入矩阵映射到H维的隐藏空间。
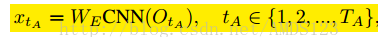
目标序列表达。作者使用句子S的单词序列S1,...,SN来表达。其中每个单词S可以使用one-hot向量来表达,其维度和词典的尺寸相同。
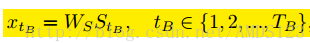
源到目标的递归神经网络转移。作者使用LSTM来进行源序列到目标序列的学习。
序列注意层。由于源序列和目标序列在顺序上的不匹配,很可能会影响学习的效果。所以作者提出了attention layer来加强源序列和目标序列的联系。
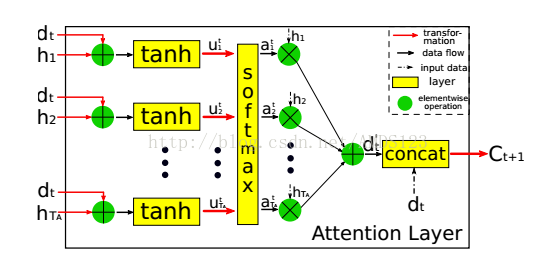
在tB时刻,attention layer从所有的编码状态h1,...,hTa和之前的解码状态dt-1计算attention context vector Ct。
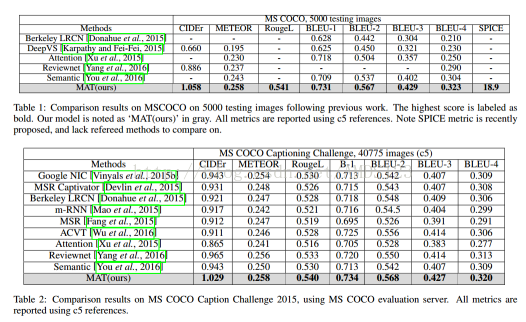
实验结果如下:














 630
630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









