







一、实验目的
掌握Huffman编解码实现的数据结构和实现框架, 进一步熟练使用C编程语言, 并完成压缩效率的分析。
二、实验原理
1. Huffman编码
(1)Huffman Coding (霍夫曼编码)是一种无失真编码的编码方式, Huffman 编码是可变字长编码(VLC)的一种。
(2)Huffman 编码基于信源的概率统计模型,它的基本思路是,出现概率大的信源符号编长码,出现概率小的信源符号编短码,从而使平均码长最小。
(3)在程序实现中常使用一种叫做树的数据结构实现 Huffman 编码,由它编出的码是即时码。
2. Huffman编码的方法
(1) 将文件以ASCII字符流的形式读入, 统计每个符号的发生频率;
(2)将所有文件中出现过的字符按照频率从小到大的顺序排列;
(3) 每一次选出最小的两个值,作为二叉树的两个叶子节点,将和作为它们的根节点,这两个叶子节点不再参与比较,新的根节点参与比较;
(4)重复3, 直到最后得到和为1的根节点;
(5)将形成的二叉树的左节点标0,右节点标1, 把从最上面的根节点到最下面的叶子节点途中遇到的0、 1序列串起来,得到了各个字符的编码表示。
3. Huffman编码的数据结构设计
在程序实现中使用一种叫做二叉树的数据结构实现Huffman编码。
(1)Huffman节点结构
typedef struct huffman_node_tag
{
unsigned char isLeaf; /* 是否为叶结点 */
unsigned long count; /* 信源中出现频数 */
struct huffman_node_tag *parent; /* 父节点指针 */
union /* 如果不是树叶,则此项为该结点左右孩子的指针;否则为某个信源符号 */
{
struct
{
struct huffman_node_tag *zero, *one;
};
unsigned char symbol;
};
} huffman_node;(2)Huffman码字结点
typedef struct huffman_code_tag
{
/* 码字的长度(单位:位) */
unsigned long numbits;
/* 码字, 码字的第 1 位存于 bits[0]的第 1 位,
码字的第 2 位存于 bits[0]的第的第 2 位,
码字的第 8 位存于 bits[0]的第的第 8 位,
码字的第 9 位存于 bits[1]的第的第 1 位 */
unsigned char *bits;
} huffman_code;4. 静态链接库的使用
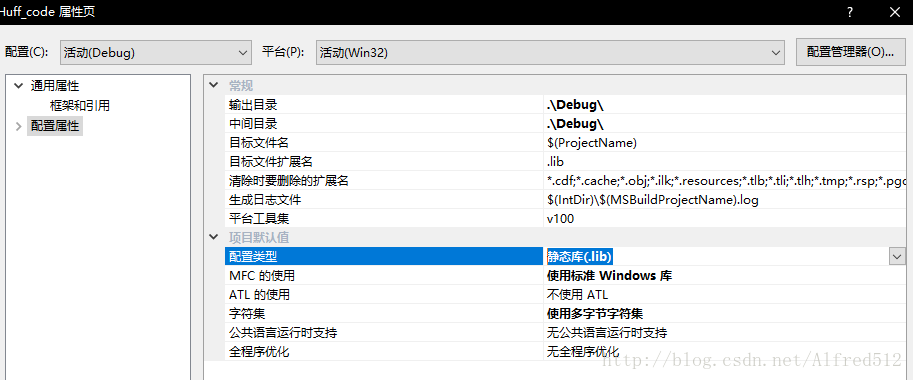
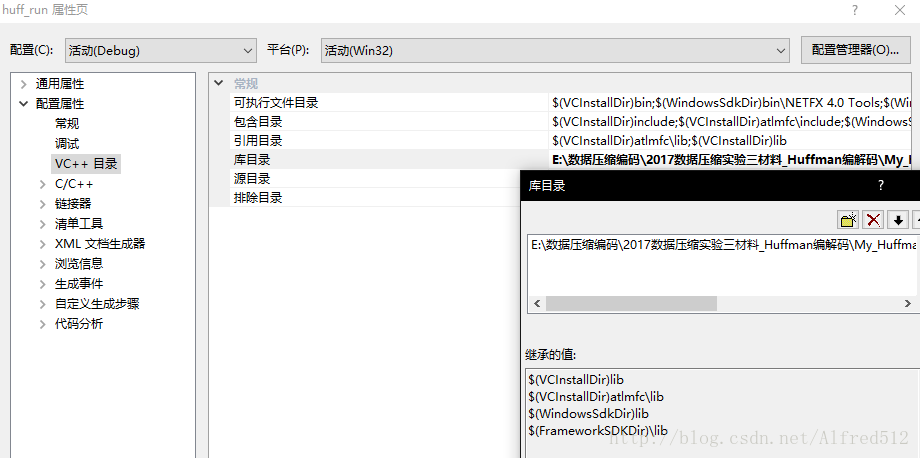
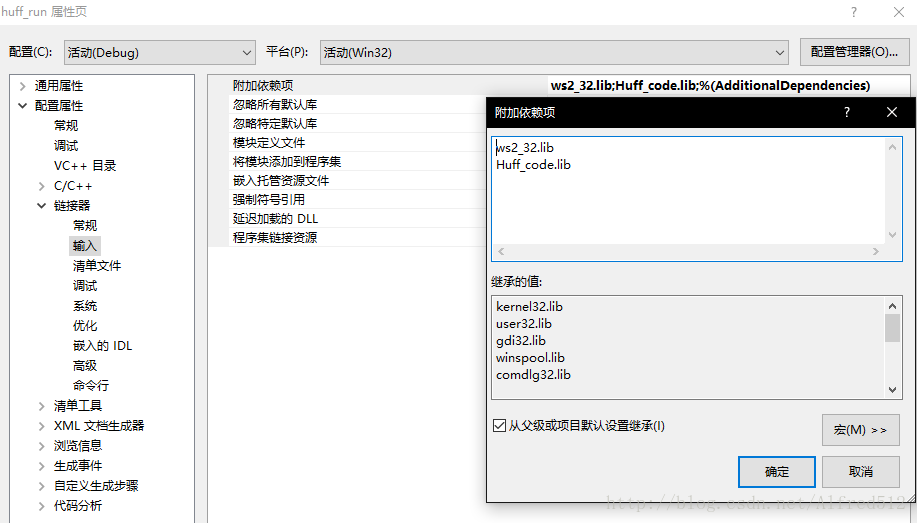
本实验由两个项目组成,第一个项目为 Huffman 编码的具体实现,名为 huff_code,创建项目时选择的是静态库,生成一个 .lib 文件。第二个项目 huff_run 只需要包含这个库即可调用其中的编码函数。项目属性需要配置库目录属性,也就是第一个项目生成文件的路径,和附加依赖性属性,也就是库的名称,如图所示。由于代码中用到了字节序转换的函数 htonl、ntohl,附加依赖项还需包含 ws2_32.lib。
三、实验步骤及代码分析
1.调试
首先调试Huffman的编码程序, 对照编码算法步骤对关键语句加上注释,并说明进行何操作。
Huffman编码流程
(1)读取文件
使用库函数中的getopt解析命令行参数,这个函数的前两个参数为main中的argc和argv,第三个参数为单个字符组成的字符串,每个字符表示不同的选项,单个字符后接一个冒号,表示该选项后必须跟一个参数。
//--------huffcode.c--------
...
static void
usage(FILE* out)//命令行参数格式
{
fputs("Usage: huffcode [-i<input file>] [-o<output file>] [-d|-c]\n"
"-i - input file (default is standard input)\n"
"-o - output file (default is standard output)\n"
"-d - decompress\n"
"-c - compress (default)\n"
"-m - read file into memory, compress, then write to file (not default)\n",
// step1: by yzhang, for huffman statistics
"-t - output huffman statistics\n",
//step1:end by yzhang
out);
}
//————————————————————————————————————————————————————————
int main(int argc, char** argv)
{
char memory = 0; //memory表示是否对内存数据进行操作
char compress = 1; //compress为1表示编码,0表示解码
const char *file_in = NULL, *file_out = NULL;
FILE *in = stdin, *out = stdout;
while((opt = getopt(argc, argv, "i:o:cdhvm")) != -1) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5508
5508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









