







0) 引论
随机是很有用的一个东西,先不去管什么随机化算法,至少随机数是个很好的东西,就像掷骰子,总可以帮组我们决定一些犹豫不决的并且无关紧要的事。在机器学习中,一般我们都是要在整个数据集中随机抽取一定的数据做训练,另外一些做测试,这样结果才能有说服力,这里也将用到了随机数。因此下面我们首先来讲解一下伪随机数发生器。
1) 伪随机数发生器
真正意义上的随机数是很难产生的,大多数的随机数都是伪随机数,伪随机数是可以计算出来的,并且它有一个周期。但是由于伪随机数拥有随机数的大部分统计性质,因此对于一般的应用,伪随机数就可以用于解决问题了,当然密码学除外,这个是要真的随机数的。
伪随机数发生器的原理是:
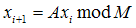
举个例子,如果M=11,A=7,x0=1,那么产生的伪随机数为:7,5,2,3,10,4,6,9,8,1,7,5,.......
这个随机数列的周期为10.
当然如果用上面的数计算随机数列的话,效果相当不好,因为周期太小,得不到几个随机数,因此我们要选择更好的数据,一般来说M要大,这样才能得到更长的周期。同时也要注意A的选取,因为A也会影响周期。
一般来说我们采用M=(2^31)-1 = 2147483647,这个是一个31位的质数,A=48271,这个A能使M得到一个完全周期
- static unsigned long Seed = 1;
- define A 48271L
- define M 2147483647
- double Random(void)
- {
- Seed = (A*Seed)%M;
- return (double) Seed/M;
- }
static unsigned long Seed = 1;
define A 48271L
define M 2147483647
double Random(void)
{
Seed = (A*Seed)%M;
return (double) Seed/M;
}
上面的算法产生的随机数还是有一个问题的,它无法产生重复的随机数。例如5,5,3,7,1这样的数列。
还有很多的随机数的算法利用的是下面的公式:
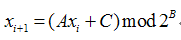
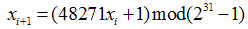
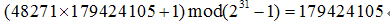
定义
举例
例一
例二
srand48和drand48是Unix库函数,drand48的作用是产生[0,1]之间均匀分布的随机数,采用了线性同余法和48位整数运算来产生伪随机序列
其中
函数用上面的算法产生一个48位的伪随机整数,然后再取出此整数的高32位作为随机数,然后将这个32位的伪随机数规划到[0,1]之间,用函数srand48来初始化drand48(),其只对于48位整数的高32位进行初始化,而其低16位被设定为随机值。
1: #define MNWZ 0x100000000
2: #define ANWZ 0x5DEECE66D
3: #define CNWZ 0xB16
4: #define INFINITY 0xFFFFFFFFF
5:
6: int labelsize;
7: int dim;
8:
9: static unsigned long long seed = 1;
10:
11: double drand48(void)
12: {
13: seed = (ANWZ * seed + CNWZ) & 0xFFFFFFFFFFFFLL;
14: unsigned int x = seed >> 16;
15: return ((double)x / (double)MNWZ);
16: }
17:
18: //static unsigned long long seed = 1;
19:
20: void srand48(unsigned int i)
21: {
22: seed = (((long long int)i) << 16) | rand();
23: }














 2032
2032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









