







以前看到过一个题目,说设计算法,要求在10亿个数的数据流中找出最小的10个数
我想到有两种算法,第一种利用大根堆找出最小的10个数,第二种方法是第一种的改进,利用多线程实现并行计算,将计算任务分为若干个,之后再将结果进行合并。
实验一
思路:需要一个大根堆存储最终的结果,利用Random不断地产生随机数。大根堆初始化为容量为10、所有元素都为Integer.MAX_VALUE。之后,没产生一个随机数,都与大根堆的堆顶做比较,如果小于堆顶元素值,则弹出堆顶元素,讲这个随机数插入大根堆,(自动建堆后)继续。
Java代码
public class Test1 {
static Random random = new Random();
public PriorityQueue<Integer> queue; //大根堆
public Test1() {
//用PriorityQueue实现大根堆
queue = new PriorityQueue<Integer>(10, new Comparator<Integer>() {
@Override
public int compare(Integer num1, Integer num2) {
return -(num1 - num2);
}
});
//初始化大根堆
for (int i = 10; i > 0; i--)
queue.add(Integer.MAX_VALUE);
}
public static void main(String[] args) {
Test1 solution = new Test1();
long st = System.currentTimeMillis();
for (int i = 0; i < 1000000000; i++) {
int num = random.nextInt(Integer.MAX_VALUE);
//随机数与堆顶元素进行比较
if (solution.queue.peek() > num) {
solution.queue.poll();
solution.queue.add(num);
}
}
long et = System.currentTimeMillis();
System.out.println(solution.queue.toString());
System.out.println(et - st + "ms");
}
}实验结果:
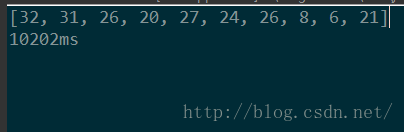
实验二
思路:因为算法属于CPU计算密集型,根据计算机CPU数目来确定需要开启的线程数。在每个线程利用Callable来实现(因为可以进行结果的返回),每个线程需要完成各自均分的计算量(返回10个最小的数)。在线程计算任务完成后,需要对计算结果进行返回。因为返回的结果具有依赖性,需要等待所有线程的计算结果都返回以后才能进行下一步的计算,此时需要一个闭锁,等待所有线程都到达计算完成以后才能进行下一步。下一步中,需要对每个线程返回的结果进行汇总,再找出最终的最小10个数。因为线程的数量和CPU数目有关,每个线程最后返回其计算任务中最小的10个数字,所有此步骤中计算量不会太大,之间讲所有线程的返回结果集合到一起在进行排序选出最小的10个数字即可。
线程类:
public class SortTask implements Callable<PriorityQueue<Integer>> {
private int times = 0;
private Random random = new Random(); //每个线程拥有独立的随机数生成器
private PriorityQueue<Integer> heap = null; //大根堆
private CountDownLatch latch = null; //多个线程受同一个闭锁制约
public SortTask() {
}
public SortTask(int times, CountDownLatch latch) {
this.times = times;
this.latch = latch;
heap = new PriorityQueue<Integer>(10, new Comparator<Integer>() {
@Override
public int compare(Integer num1, Integer num2) {
return -(num1 - num2);
}
});
for (int i = 10; i > 0; i--)
heap.add(Integer.MAX_VALUE);
}
@Override
public PriorityQueue<Integer> call() throws Exception {
for (int i = 0; i < times; i++) {
int num = random.nextInt(Integer.MAX_VALUE);
if (this.heap.peek() > num) {
this.heap.poll();
this.heap.add(num);
}
}
//完成计算任务,闭锁计数减1
this.latch.countDown();
return this.heap;
}
}计算类
public class BigDataTest {
public BigDataTest() {
}
public List<Integer> doSortBigData(int cpuNumber, int times)
throws InterruptedException {
if (cpuNumber < 1)
return null;
//所有的线程都受同一个闭锁的限制,每完成一个线程的计算,闭锁计数减1
CountDownLatch latch = new CountDownLatch(cpuNumber);
//线程任务集
List<SortTask> tasks = new ArrayList<SortTask>();
for (int i = 0; i < cpuNumber; i++) {
tasks.add(new SortTask(times, latch));
}
//在线程交给线程池执行
ExecutorService threadsPool = Executors.newCachedThreadPool();
List<Future<PriorityQueue<Integer>>> results = threadsPool.invokeAll(tasks);
latch.await(); //阻塞直到所有线程都执行完毕
//把所有线程的计算返回结构聚集在ArrayList中
List<Integer> sortResult = new ArrayList<Integer>();
for (int i = 0; i < results.size(); i++) {
try {
sortResult.addAll(results.get(i).get());
} catch (ExecutionException e) {
e.printStackTrace();
}
}
threadsPool.shutdown();
Collections.sort(sortResult); //排序
return sortResult.subList(0, 10);
}
}
public class TestMain {
private static final short CUP_NUMBER = 4; //cpu数目
private static final int NUMBER_COUNT = 1000000000;
public static void main(String[] args) {
List<Integer> result = null;
long starTime = System.currentTimeMillis();
try {
//启动CUP_NUMBER个线程,每个线程计算量为NUMBER_COUNT / CUP_NUMBER
result = new BigDataTest().doSortBigData(TestMain.CUP_NUMBER,
TestMain.NUMBER_COUNT / TestMain.CUP_NUMBER);
} catch (InterruptedException e) {
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println(result.toString());
System.out.println((endTime - starTime) + "ms");
}
}结果:
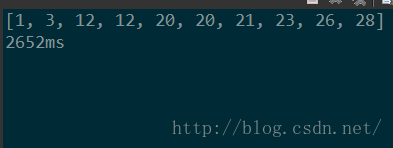
可以看到,利用多线程实现的并行算法,在效率上有了很大的提高,并且cpu数目越多,效率越高。














 1675
1675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









