







Lucene 是基于倒排索引来实现快速的全文检索的,那么倒排索引是什么概念呢?
![]()
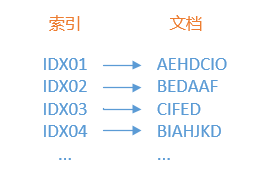
首先来看看普通索引是怎样建立的,请参考下图。
图中,我们为右侧的每一个文档都建立了一个索引编号,当我们知道这个编号时,就可以查询到对应的文档,而如果我们还对这些索引编号进行排序,那检索的速度就会更快。但是,当我们需要检索包含“F”的文档时,普通索引就完全不能发挥作用了,因为我们不得不遍历每一个文档,并试图筛选出那些包含了“F”的文档,而这样的检索性能在大数据量的情况就可想而之了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3139
3139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









