







1. 理解GPU
- 为了提升运算能力,大家更喜欢用 “更多的、简单的计算单元”
- CPU解决的问题是Latency,每个任务最短能在多长时间内完成
- GPU解决的是ThroughPut,每个单位时间能解决多少任务
- GPU擅长高效的并发
- 并行的执行大量的线程
3. 典型的GPU程序
- CPU为GPU分配内存空间 CUDA MALLOC
- CPU拷贝输入数据 CPU->GPU CUDA memcpy
- CPU launches kernel on GPU来计算数据 kernel Launch
- CPU发送拷贝请求,GPU->CPU CUDA memcpy
上述的2、4步骤都是转移数据,这两步骤都是非常的昂贵的。
4. BIG IDEA
Kernels look serial programs.Write your program as if it will run on one thread.The GPU will run that program on many threads
5. 最简单的CUDA程序
这是一个计算一组数字的平方的CUDA程序__global__修饰符表示这是一个CUDA函数,也叫kernel function。
整个程序简单易懂,注释清晰,不做过多的解释了
#include <stdio.h>
__global__ void square(float * d_out, float * d_in)
{
int idx = threadIdx.x;
float f = d_in[idx];
d_out[idx] = f * f;
}
int main(int argc, char ** argv)
{
const int ARRAY_SIZE = 64;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
// generate the input array on the host
float h_in[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; i++)
{
h_in[i] = float(i);
}
float h_out[ARRAY_SIZE];
// declare GPU memory pointers
float *d_in;
float *d_out;
// allocate GPU memory
cudaMalloc((void**) &d_in, ARRAY_BYTES);
cudaMalloc((void**) &d_out, ARRAY_BYTES);
// transfer the array to the GPU
cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice);
// launch the kernel
square<<<1, ARRAY_SIZE>>>(d_out, d_in);
// copy back the result array to the CPU
cudaMemcpy(h_out, d_out, ARRAY_BYTES, cudaMemcpyDeviceToHost);
// print out the resulting array
for (int i =0; i < ARRAY_SIZE; i++) {
printf("%f", h_out[i]);
printf(((i % 4) != 3) ? "\t" : "\n");
}
cudaFree(d_in);
cudaFree(d_out);
return 0;
} 6. BLOCK和GRID
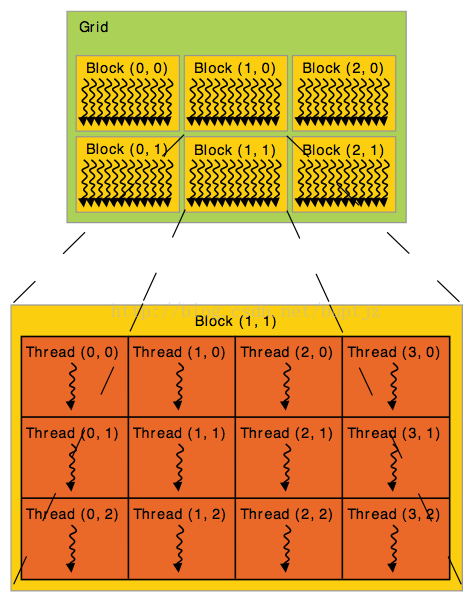
- 许多的线程组织在一个BLOCK里,threadIdx变量指示该线程是哪一个线程。而BLOCK有一个限制:一个BLOCK最多能含有1024个线程。怎么办呢,我们可以使用多个BLOCK,多个BLOCK怎么组织呢?使用GRID!
- GRID和BLOCK的关系就和BLOCK和THREAD的关系类似。
- BLOCK和GRID可以是int类型,也可以是dim3类型
- <<<...>>> 符号指定使用多少BLOCK和GRID
- BLOCK可以是1维、2维、3维
- kernel通过blockIdx变量来获取当前是那个BLOCK
- BLOCK的维数则可以通过blockDim这个变量获取
- 组织结构如图所示
Memory
1)Local memory:一个线程内部变量占据的内存
2)shared memory:一个BLOCK内部所有线程共享的内存【注:__shared__修饰符表示这个BLOCK共享内存】
3)global memory:全部线程共有的内存
速度 1)大于 2)远大于 3)
这里有一道练习题:下面的这段代码,1,2,3,4行中,每一行的运算最快,哪一行最慢,分别给每一行打分,分数1~4
__global__ void foo(float *x,float *y,float *z)
{
__shared__ float a,b,c;
float s,t,u;
s = *x;//1
t = s;//2
a = b;//3
*y = *z;//4
}
__global__ void foo(float *x,float *y,float *z){
__shared__ float a,b,c;
float s,t,u;
s = *x;//1
t = s;//2
a = b;//3
*y = *z;//4
}同步(Synchronise)
就像给代码设置一个障碍一样
现在我们要做这样一件事,有一个数组,我们想将这个数组每一项向前移动一位(忽略第一项),也就是array[x] = array[x+1]
一个简略的函数框架可能是这样的:
__global__ void shift(){
int idx = threadIdx.x;
__shared__ int array[128];
array[idx] = threadIdx.x;
if (idx < 127) {
array[idx] = array[idx + 1];
}
} __global__ void shift(){
int idx = threadIdx.x;
__shared__ int array[128];
array[idx] = threadIdx.x;
if (idx < 127) {
array[idx] = array[idx + 1];
}
}array[20] = 20;可以执行
array[20] = array[20+1];如果线程21在线程20之后执行,显然这句话的赋值是错误的
那么正确的运行上述程序,需要给代码设置几个“障碍”,如下
__global__ void shift(){
int idx = threadIdx.x;
__shared__ int array[128];
array[idx] = threadIdx.x;
__syncthreads();//执行至此,数组中的每一个元素都被正确的赋值
if (idx < 127) {
int temp = array[idx + 1];
__syncthreads();//将一行代码拆分成两行来设置一个barrier,这种技巧非常实用,执行至此,每一个线程都正确的取值
array[idx] = temp;
__syncthreads();//确保后续使用array的正确性
}
}__global__ void shift(){
int idx = threadIdx.x;
__shared__ int array[128];
array[idx] = threadIdx.x;
__syncthreads();//执行至此,数组中的每一个元素都被正确的赋值
if (idx < 127) {
int temp = array[idx + 1];
__syncthreads();//将一行代码拆分成两行来设置一个barrier,这种技巧非常实用,执行至此,每一个线程都正确的取值
array[idx] = temp;
__syncthreads();//确保后续使用array的正确性
}
} 













 3994
3994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









