







版本号: 1.0.0
声明: 为简洁起见,本文示例未包含详细代码即注释,敬请谅解。
提示:为保证文章质量,文章采用的术语均来自于参考文献,详细解释请参考相应文献。
-
说明:
- 楷体:专有名词
- 标红:重要提示
- 加粗:重点内容
All good things which exist are the fruits of originality.——John Stuart Mill
异常(Exception)
基本概念
异常定义
“An exceptional condition is a problem that prevents the continuation of the current method or scope. It’s important to distinguish an exceptional condition from a normal problem, in which you have enough information in the current context to somehow cope with the difficulty. With an exceptional condition, you cannot continue processing because you don’t have the information necessary to deal with the problem in the current context. All you can do is jump out of the current context and relegate that problem to a higher context. This is what happens when you throw an exception.”(《Think in Java (Fourth Edition)》)
异常与普通问题最根本的区别在于当前环境是否有足够的信息对该错误进行有效地处理,能够进行处理的均为普通问题,而必须把问题传递到上级进行处理的为异常。
适用场景
Joshua Bloch在《Effective Java》一书中指出
“Use exceptions only for exceptional conditions”
因此对于异常的使用必须谨慎,他同时指出现代JVM中基于异常的模式比标准模式要慢的多。
“Exceptions are, as their name implies, to be used only for exceptional conditions; they should never be used for ordinary control flow.”
“设计良好的API不应该强迫客户端为了正常的控制流而使用异常。”(A well-designed API must not force its clients to use exceptions for ordinary control flow.)
根据以上理念,在处理依赖状态相关的方法(只有在不可预知的特定条件下才可以被调用)有两种形式(《Effective Java》):
A. 在类中提供单独的“状态测试方法”用来指示是否可以调用相应方法。例如Iterator接口的hasNext方法:
for(Iterator<Object> i = Collection.iterator();i.hasNext();){
//
} B. 在调用状态相关的方法时,该对象如果处于一个不适当的状态,返回一个可识别的值,如null。但对于可识别值的确定依赖于API端和客户端之间的约定,而且这与《Effective Java》中第43条
“返回零长度的数组或集合,而不是null。”
存在一定的冲突。在日常编程中,对大多数方法传入null的参数是没有意义的。
前置条件
Google的Java框架Guava提供了Preconditions工具类对参数检验提供相应静态方法,下面以三个方法为例作简要简介:
1. checkNotNull
public static <T> T checkNotNull(T reference, @Nullable Object errorMessage) {
if (reference == null) {
throw new NullPointerException(String.valueOf(errorMessage));
}
return reference;
}2. checkArgument
public static void checkArgument(boolean expression, @Nullable Object errorMessage) {
if (!(expression))
throw new IllegalArgumentException(String.valueOf(errorMessage));
}
}3. checkState
public static void checkState(boolean expression, @Nullable Object errorMessage) {
if (!(expression))
throw new IllegalStateException(String.valueOf(errorMessage));
}由于以上静态方法对于参数异常的处理方式为抛出标准的未受检异常,因此并不会给客户端程序员带来额外的异常处理工作,其优势在于能够通过抛出异常迅速准确定位出错位置。
当然采用第三方API lombok注解@NonNull的方式对参数进行限制则更为方便,同时在方法声明的时候表明了合法参数需满足的条件。
异常类型
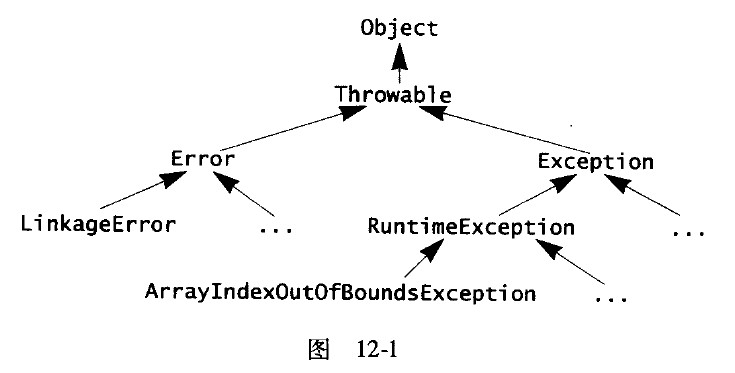
由以上结构图可以看出,所有异常均继承自Throwable类,在下一层分解为Error和Exception两大类。
Error
Error类层次结构描述了Java运行时的内部错误和资源耗尽错误,应用程序不应该抛出这种类型的对象。
在Effective Java第4条
“通过私有构造器强化不可实例化的能力”
给出的示例代码中:
public UtilityClass{
private UtilityClass(){
throw new AssertionError();
}
}在构造器中抛出AssertionError的理由是防止类内部对构造器的调用,并防止通过反射机制来创建实例。
对于只具有静态工具方法的UtilityClass来说避免其实例化是正确的选择。在此基础之上将其设置为final类,则避免了该类被继承的可能。同时采用IllegalAccessException代替AssertionError则相对更为合适。
public final UtilityClass{
private UtilityClass(){
throw new IllegalAccessException ();
}
}Exception
Exception根据是否为程序错误导致的异常可以分为两类:运行时异常RuntimeException(与Error组成未受检异常)和受检的异常(Checked Exception)。
根据Effective Java中第58条,可以总结出两类异常的使用基本原则:
“对于可以恢复的情况使用受检的异常,而对于程序错误则使用运行时异常。”
自定义异常
根据《Effective Java》中第60条中所指出的:代码的高度重用是一直值得提倡的行为,而jdk已经提供了数量庞大的标准异常类。重用现有的标准异常能够降低学习成本并提高代码可读性,此外异常类越少,其堆栈轨迹就越少,装载这些类的时间开销就越小。
因此,应优先使用标准异常。
通过自定义异常表明程序中的特定问题也为Java所支持。针对自定义异常大多数为RunTimeException的情况,下面对该异常子类进行分类介绍:
未包含原因(Cause)的运行时异常
public class NullPointerException extends RuntimeException {
private static final long serialVersionUID = 5162710183389028792L;
public NullPointerException() {
super();
}
public NullPointerException(String message) {
super(message);
}
}包含原因(Cause)的运行时异常
public class IllegalArgumentException extends RuntimeException {
private static final long serialVersionUID = -5365630128856068164L;
public IllegalArgumentException() {
super();
}
public IllegalArgumentException(String message) {
super(message);
}
public IllegalArgumentException(String message, Throwable cause) {
super(message, cause);
}
public IllegalArgumentException(Throwable cause) {
super(cause);
}
}以上分别为未包含Cause的NullPointerException和包含Cause的IllegalArgumentException的程序,两者的区别主要是前者并未给出包含原因的构造器,其在打印堆栈轨迹时将成为终点。而后者则可以通过调用包含Throwable参数的构造器或者调用initCause方法指出异常的上一级来源。
需要特别说明的一点是:异常最重要的信息来源于异常名称,因此Bruce Eckel在《Think in Java》一书中认为
“As you’ll see, the most important thing about an exception is the class name, so most of the time an exception like the one shown here is satisfactory.”
但是message的存在提供了构建更详细异常信息的条件,尤其在复杂逻辑场景下,构造包含详细参数的异常能有效地提高程序维护的效率,这一点也是不言自明的。
异常声明
一个方法必须声明所有可能抛出的已检查异常,而不应该声明任何未检查异常。
public void functionName() throws FileNotFoundException, EOFException;普通情况下的异常声明
-
《Effective Java》中第62条对异常声明提出了几条建议,现归纳如下:
- 1、使用单独的声明受检异常,并利用Javadoc的@throws标记,准确记录下抛出每个异常的条件;
- 2、尽可能将抛出的异常具体化,永远不要声明一个方法“throws Exception”,这种声明方式掩盖了方法中抛出的具体异常信息,妨碍了方法的使用。
- 3、使用@throws标签记录方法中抛出的每一个未受检异常。
继承和实现关系下的异常声明
-
单一继承/实现下的异常声明:
-
覆盖方法时,只能抛出在基类方法的异常声明中存在的那些异常及其子类或者不抛出任何异常。如果超类没有抛出任何已检查异常,则子类也不能抛出任何已检查异常。
多重继承的异常声明:
-
派生类在实现接口同时继承基类的情况下,如果接口和基类有相同的方法,且同时声明了不同的已检验异常,则子类的方法不能兼容两类异常。只能采用不声明异常的形式处理。但若以上两者声明的异常相同,则子类的方法需要声明该异常或者其派生类异常。
需要特别说明的是,异常声明对于构造器并没有限制作用。
派生类构造可以不理会基类构造器抛出的异常。但是由于派生类构造器必须以一种方式调用基类构造器,因此派生类构造器也必须包含基类构造器的异常声明。
同时由于检验型异常必须在throws子句中声明,静态初始化器和静态初始化块也不能抛出检验型异常。
抛出与捕捉异常
抛出异常
throw new ExceptionType(…);抛出异常时建议抛出较为具体的异常类,而不是RumtimeException和IOException这些抽象的异常, 强烈反对抛出异常基类Exception,无论是从性能角度来看还是从可读性角度来看,这种行为都没有任何好处。
try块为可能产生异常的监控区域:
try{
//Code that might generate exceptions
}对于try块监控区域范围的选择,大多数观点偏向于尽量缩小范围来锁定异常抛出的代码,然而范围大小对程序性能的影响却依赖于JVM的异常处理机制,本文不再深入展开。
详细信息可以参考:
How the Java virtual machine handles exceptions
Tips:经测试,在更精确的范围设定监控区域比在更广的范围内具有性能上明显的优势,然而这并不意味着try{}块越小越好,在一个方法中不宜使用过多的try{}块,一是因为异常捕捉程序并非正常的程序流程,过分细化的异常处理影响正常代码的可读性;二是过多的细分异常监控会导致代码膨胀,影响实用性和美观。
捕捉异常
通常的捕获异常的代码为:
try{
//code
}
catch(ExceptionType e){
//handle for this type
}-
通常的代码执行顺序是这样的(《Java 核心技术 卷一:基础知识》):
- A、try块中抛出了在catch子句中声明的异常类:程序跳过try块后续代码,执行对应catch子句中的代码,再执行catch子句以后的代码;
- B、try块中没有抛出任何异常,程序跳过catch子句;
- C、try块中抛出catch子句中没有声明的异常类型,则立刻退出当前方法,返回上一级调用方法中。
异常匹配:异常处理程序会按照代码顺序寻找最近的匹配异常,catch子句将会匹配其声明的异常类及其子类的所有异常,因此在编写catch子句的顺序时要把派生类的异常要写在基类异常的前面。
Java SE 7增加了捕捉多个异常的功能:
try{
//code
}catch(ExceptionTypeOne|ExceptionTypeTwo e){
// handle for this type
}捕捉多个异常时,异常变量隐含为final属性。这种情况只有在捕获的异常彼此之间不存在子类关系时使用,但这种处理方式回事代码更简洁和高效。
详细资料请参考:
Catching Multiple Exception Types and Rethrowing Exceptions with Improved Type Checking
异常转译
《Effective Java》中61条指出:
“更高层的实现应该捕获底层的异常,同时抛出可以按照高层抽象进行解释的异常,这种做法被称为异常转译(Exception Tranlation)”。
try{
//code
}catch(LowerLevelException e){
throw new HighLevelException();
}异常链
异常链(Exception Chaining)为底层的异常(原因)被传递到高层的异常,高层异常提供访问方法(Throable.getCause)来获得底层的异常。
try{
//code
}catch(LowerLevelException e){
throw new HighLevelException(cause);
}显然,除了调用含有Throwable对象参数的构造器进行异常转译外,也可以通过Throwable.initCause方法将底层异常设置为高层异常的原因。
需要注意的是:不采用异常链的普通异常转译方法(捕获异常并抛出新的异常)与在catch块中调用fillInStackTrace方法一样会丢失原来异常发生点的信息,抛出的是与新的抛出点有关的信息。因此使用这些方式进行异常处理需要确保底层异常信息对高层代码无关紧要。否则会影响异常的准确定位。
不对抛出的异常进行捕获,异常将会继续向更高层的调用程序抛出,但堆栈轨迹仍然会包含调用链上的每一个方法。或者可以通过采用捕获异常打印异常信息(包含本级具体信息)再重新抛出异常的方式处理不需要异常转译的底层异常。
避免不必要的异常捕捉
强烈反对以下只是简单的捕捉异常再抛出的处理方式:
try{
//code
}catch(ExceptionType e){
throw e;
}
以上方式与不对异常进行捕获相比并没有提供任何额外的信息,但捕获异常重新抛出的过程却耗用了更多的时间,是没有任何意义的。
更有甚者,有些程序直接对异常进行吞没而不进行任何处理:
try{
//code
}catch(ExceptionType e){
}《Effective Java》中第65条:
“不要忽略异常”
对以上处理方式进行了批判,这种处理异常的方式明显违背了异常处理的基本原则:“只有在你知道如何处理的情况下才捕获异常“。这种处理方式掩盖了原来的异常信息,更重要的是在抛出异常时让调用方根本无从知道问题的根源所在,希望读者引以为鉴。
finally子句
众所周知,finally子句对于没有垃圾回收和析构函数自动调用机制的语言来说非常重要,所以它重要的功能之一就是用于程序的内存释放。在具有垃圾回收机制的Java中,finally子句最常用的场景是用来关闭一个外围连接(文件或者数据库等)。
常规情况
对于常规finally子句执行的理解请参考《Java核心技术-基础知识(第九版)》11.2.3节。
《Think in Java》、《Core Java》和《Effective Java》都未对finally子句中的语句块执行情况进行深入分析,本文将借助《The Java Tutorials》和《The Java™ Language Specification》对finally子句一探究竟。
深入分析
首先需要明确的是:
如果程序在执行try{}代码块之前就抛出异常或者返回了,与相应try{}块对应的finally子句是不会执行的。除此之外,如果try块中调用了JVM终止程序System.exit(),finally子句也是不会被执行的。当一个线程在执行 try 语句块或者 catch 语句块时被打断(interrupted)或者被终止(killed),与其相对应的 finally 语句块可能不会执行。
《The Java™ Programming Language, Fourth Edition》对finally子句执行描述摘录如下:
“A finally clause is always entered with a reason. That reason may be that the try code finished normally, that it executed a control flow statement such as return, or that an exception was thrown in code executed in the Try block. The reason is remembered when the finally clause exits by falling out the bottom. However, if the finally block creates its own reason to leave by executing a control flow statement (such as break or return) or by throwing an exception, that reason supersedes the original one, and the original reason is forgotten. For example, consider the following code:
try {
// … do something …
return 1;
} finally {
return 2;
}When the Try block executes its return, the finally block is entered with the “reason” of returning the value 1. However, inside the finally block the value 2 is returned, so the initial intention is forgotten. In fact, if any of the other code in the try block had thrown an exception, the result would still be to return 2. If the finally block did not return a value but simply fell out the bottom, the “return the value 1 ″ reason would be remembered and carried out.”
总结以上可以发现,无论是在try块还是在catch块中的控制转移语句 return 和 throw (把程序控制权转交给它们的调用方)都不会影响finally子句中程序的执行,也就是说在return和throw之前finally子句都会被执行,问题的关键在于当return和throw语句出现在finally中时,其程序运行将存在非正常预期的结果。
finally子句中存在return语句时:
public class FinallyTest {
public static void throwNullPointerException(){
throw new NullPointerException("null pointer.");
}
@SuppressWarnings("finally")
public static int finallyTest() {
try {
//throwNullPointerException();
return 1;
} catch (NullPointerException e) {
return 2;
} finally {
return 3;
}
}
public static void main(String[] args) {
System.out.print(finallyTest());
}
//Expected Result:3
}如例,由于finally中子句会在try块和catch块中的控制转移语句之前执行,因此finally中的return语句会将结果返回给调用方而导致try块和catch块中的返回语句不被执行,因此应该尽量避免在finally子句中使用return语句,而将该职责交给try块或者catch块。
在《Java核心技术》一书中,作者推荐嵌套使用try & finally和try & catch两种结构来代替传统的try&catch&finally结构,即:
嵌套结构:
InputStream in = ...;
try{
try{
//code
}finally{
in.close();
}
}
catch(IOException e){
//code to process exception
} 这种嵌套结构主要有两大好处,一是确保每一个try块都有单一的职责。内部try块负责处理输入流,而外部try块负责捕获异常。二是能够捕获finally子句中抛出的异常,对finally块进行异常监控
finally子句中抛出异常时:
《Java编程思想》和《Java核心技术》均提到了在Java SE 7之前存在的异常缺陷,即:当try、catch块和finally子句中同时抛出异常时,finally中抛出的异常会把try、catch块中抛出的异常掩盖,引起异常信息的丢失。
如上文所述,finally语句在Java中的主要作用在于关闭资源链接,因此Java SE 7 引入了带资源的try子句:
try(ResourceOne,ResourceTwo){
//code
}此时无论程序是正常退出或者抛出异常,资源链接都能被关闭。这在SE 7之前的版本中只能通过嵌套try块来完成。
除了以上两种情况之外,还应该尽量避免的一种情况是在finally语句中包含正常业务流程的处理,如下例:
@SuppressWarnings("finally")
public static int finallyTest() {
int i = 0;
try{
i = 2;
return i;
}catch(NullPointerException e){
i = 3;
return i;
}finally{
i++;
System.out.println(String.format("finally block:%d",i));
}
}
public static void main(String[] args) {
System.out.print(finallyTest());
}
//Expected Result:
//finally block:3
//2以上示例中函数finallyTest()的返回结果并非是执行了i++语句的3,而是2。其原因在于在执行finally中语句之前, try 或者 catch 语句块会保留其返回值到本地变量表(Local Variable Table)中。待finally中语句执行完毕之后,再恢复保留的返回值到操作数栈中,然后通过 return 或者 throw 语句将其返回给该方法的调用者(invoker)。
因此应该尽量避免在finally子句中对返回值进行处理。
《The Java® Virtual Machine Specification》中3.13. Compiling finally对finally语句的编译原理进行了详细解释,有兴趣的读者可以参考阅读。除此之外,以下这篇文章对finally子句进行了详尽分析,请大家参考:
关于 Java 中 finally 语句块的深度辨析
分析堆栈跟踪元素
“当程序由于未被捕捉的异常而失败的时候,系统会自动地打印出该异常的堆栈轨迹。在堆栈轨迹中包含该异常的字符串表示法(string representation),即它的toString方法的调用结果。它通常包含该异常的类名,紧随其后的是细节消息(detail message)。”
“To capture the failure, the detail message of an exception should contain the values of all parameters and fields that “contributed to the exception.”(《Effective Java- Item 63: Include failure-capture information in detail messages》)
异常消息的目的是为了通过更清晰的打印日志来更快速准确地定位程序的错误之处。这就要求在抛出异常时提供充分有效的细节信息。
打印出堆栈跟踪的文本信息:
Throwable.printStackTrace()返回堆栈跟踪元素StackTraceElement的数组:
Throwable.getStackTrace():返回所有活动线程的堆栈跟踪的一个映射。映射键是线程,而每个映射值都是一个 StackTraceElement 数组,该数组表示相应 Thread 的堆栈转储:
Thread.getAllStackTraces():一些补充
关于文章
本文并非一次写就便再不改动的文章,如文章开头所示,文章目前版本号为1.0.0,以后会随时纠正错误的内容并增加新的内容。
关于Java
世界上不存在一种完美的编程语言。任何语言都需要技术的进步不断革新。Java也不例外。Java任何一次版本更新都是对之前存在问题的一次修复,成功的升级也意味着对Java程序员的更大解放。就像本文所提到Java SE 7增加的捕捉多个异常和带资源的try语句便是对之前异常处理缺陷的弥补。最新版本的Java SE 8增加的lambda表达式和stream API新特性不也正是函数化编程和并行计算为趋势的今天所作出的必然选择吗?而Guava采用匿名内部类的方式为SE 8之前的用户提供类函数化编程的功能便可以看做Java 函数化编程的新声。可以预见的是,未来会有更多的开源代码的设计理念引入Java之中,Java以后是否还会流行更多地取决于Oracle的态度是否开放,因为唯有开放的才是发展的。
但是,目前国内的情况是什么呢?抛去之前的旧项目不谈,即便在开发新项目的时候依然以高昂的学习成本和兼容性为由拒绝采用新技术、新手段。这种现象在国内企业是普遍存在的,这种抱残守缺、固步自封的心态怎么可能将产品做到极致?迁移成本和学习成本真的无法承担吗?恐怕这些不过是另外一些不足为外人道原因的幌子吧。更不用说大量的程序员无视各种性能优良的API,毅然决然地重复造轮子的荒唐现象。某些大公司的一些部门为了KPI重新设计投入和产出不成比例的各种平台和中间件的情况更是屡见不鲜。
以上种种奇怪的现象皆非罕见,在这种气氛下国内的编程水平到底如何才能满足市场的需要,我想应该无从谈起吧。
Tips:尽可能阅读英文原版和翻译质量较高的相关书籍,包括官方Specification和Tutorial,最好可以中英双版对照阅读。
参考文献:
1、《Think in Java, Fourth Edition》
2、《Java编程思想(第四版)》
3、《Core Java, Ninth Edition》
4、《Java核心技术(第九版)》
5、《Effective Java, Second Edition》
6、《Effective Java 中文版(第二版)》
7、《Java程序设计语言(第四版)》
8、《The Java™ Programming Language, Fourth Edition》
9、《The Java® Virtual Machine Specification(Java SE 8 Edition)》
10、《Getting Started with Google Guava》














 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









