







表现与数据分离:
也可以说是界面与数据分离,要体现在代码上,操作数据的代码和操作界面的代码,要分开写。
优势:当页面需求发生改变,只需要改写界面的代码,并且修改的代码不能影响到操作数据访问的代码。
例如:
<script>
$(function () {
var Countries = function () { } //1、匿名函数 一个函数对象
Countries.prototype = { //2、*函数对象* 的原型
_items: [],
_getData:function(success){
var items = [
{ id: 0, name: '中国' },
{ id: 1, name: '日本' },
{ id: 2, name: '美国' }
];
$.extend(this._items, items);//将items对象 合并到jquery的全局对象中。
success(items);
},
on_selected: $.Callbacks(),
on_inserted: $.Callbacks(),
select: function () {
var self = this;
this._getData(function (items) {
self.on_selected.fire({
sender:self,
items:items
});
});
},
insert: function (item) {
var self = this;
this._items.push(item);
self.on_inserted.fire({ sender: self, item: item });
}
}
//==============================================================================================
//以下为界面代码,当要调整界面,改这里就行了~~
var countries = new Countries();
countries.on_selected.add(function (args) {
$('#countries').append($('<option selected = "selected">').attr('value',args.item.id).text(args.item.name));
});
var id = 10;
$("#btnAdd").click(function () {
countries.insert({id:++id,name:$('#countryName').val()});
});
countries.select();
});
//上面的代码真正做到了结构和内容分离:
//1、在数据访问的代码中,没有一行是涉及UI,不能对UI有依赖
//当界面需求发生变化,只要修改界面的代码就可以了。
</script>
Web 语义化
学术界将web语义化称为Web3.0的核心。
目标是:提高计算机和人对于web代码的可读性。
核心思想是:标注网页对象*使其对应本体中的实体,并通过逻辑等手段进行自动推理。
作用在于更好整合网络上的资源,使计算机能够处理分布于不同位置的信息,自动产生问题的解决方案
可以分为三个阶段理解:
1、原始的一些有实际含义的标签定义。浏览器和W3C组织推出的如h1~h6、thead、ul、ol的HTML标签,用于在Web页面中组织对应的内容,以达到更方便的协作及传播互联网内容。搜索引擎很好的利用了这些语义化标签抓取内容,又鉴于搜索引擎的巨大流量推荐,Web前端不得不考虑SEO,从而两者实现有益的循环,共同推进语义化标签的使用。
2、前端开发人员自定义的标签。但Web的发展超乎想象,起初定义的HTML语义标签,不足以实现对web页面各个部分的功能或位置的描述,所以web前端人员利用HTML标签的id和class属性,进一步对HTML标签进行描述,如对页脚HTML标签添加如 id=“footer” 或者 class = “footer”的属性(值),以“无声”的方式在不同的前端程序员或者前后端程序员间实现交流。
3、在第二步的推动下结合新技术出现的一些标签。W3C组织意识到了之前HTML版本的不足,推出的HTML5进一步推进了Web语义化发展,采用了诸如footer、section等语义化标签,弥补了采用id = “footer” 或者class=“footer”形式的不足。
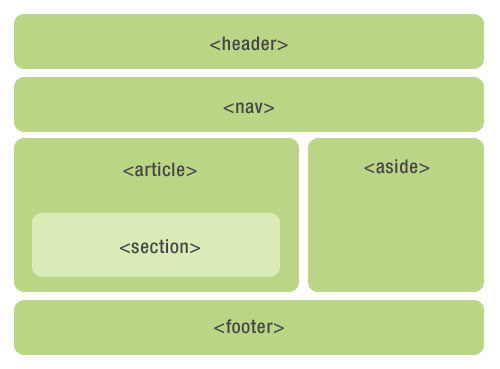
一些常用的html5语义化标签:节元素标签、文本元素标签、分组元素标签
<title></title>:简短、描述性、唯一(提升搜索引擎排名)。
搜索引擎 会将title作为判断页面主要内容的指标,有效的title应该包含几个页面内容密切相关的关键字,建议将title核心内容放在前60个字符中。
<hn></hn>:h1~h6分级标题,用于创建页面信息的层级关系。
对于搜索引擎而言,如果标题与搜索词匹配,这些标题就会被赋予很高的权重,尤其是h1.
<header></header>:元素代表“网页”或“section”的页眉。
通常包含h1~h6元素或hgroup,作为整个页面或者一个内容块的标题。
也可以包裹一节的目录部分,一个搜索框,一个nav,或者任何相关logo。
整个也买你没有限制header元素的个数,可以拥有多个,可以为每个内容块增加一个header元素。
<header>
<hgroup>
<h1>网站标题</h1>
<h1>网站副标题</h1>
</hgroup>
</header>
footer元素
footer元素代表“网页”或“section”的页脚,通常含有该节的一些基本信息,譬如:作者,相关文档链接,版权资料。
如果footer元素包含了整个节,那么它们就代表附录,索引,提拔,许可协议,标签,类别等一些其他类似信息。
<footer>
COPYRIGHT@小贝
</footer>
hgroup元素
代表“网页”或“section”的标题,当元素有多个层级时,该元素可以将h1到h6元素放在其内,譬如文章的主标题和副标题的组合。
<hgroup>
<h1>这是一篇介绍HTML5语义化标签和更简洁的结构</h1>
<h2>html5</h2>
</hgroup>
说明:如果有连续多个标题和其他文章数据,h1~h6标签就用hgroup包住,和其他文章元数据一起放入<header>标签。
nav元素:
nav元素代表页面的导航链接区域。规范上说,用于定义页面的*主要导航部分*。
但是有些地方也会有使用到,例如侧边栏上目录,面包屑导航,搜索样式,或者下一篇上一篇文章。
<nav>
<ul>
<li>HTML 5</li>
<li>CSS35</li>
<li>JavaScript</li>
</ul>
</nav>
section元素:章节
section元素代表文档中的“节”或“段”,“段”可以是指一篇文章里按照*主题的分段*;“节”可以是指一个页面里的分组。
section通常还带标题,虽然html5中section会自动给标题h1~h6降级,但是最好手动降级。如下:
<section>
<h1>section是啥</h1>
<article>
<h2>关于section</h2>
<p>section的介绍</p>
<section>
<h2>关于section</h2>
<p>section的介绍</p>
</section>
</article>
</section>
注:section使用时,一张页面可以用section划分为简介、文章条目和联系信息。
不过在文章内页,最好用article。section一般是容器元素,如果想作为样式展示和脚本便利,可以用div。
article元素:是个特殊的section
article元素最容易跟section和div混淆,其实article代表一个在文档,页面或者网站中自成一体的内容,其目的是为了让开发者独立开发或重用。
主要用于譬如:论坛的帖子,博客上的文章,一篇用户的评论,一个互动的widget小工具。
<article>
<h1>一篇文章</h1>
<p>文章内容……</p>
<footer>
<p><small>版权:htmljscss网所属,作者:小贝</small></p>
</footer>
</article>
说明:如果在article内部再嵌套article,那就代表内嵌的article是与外部的内容有关联,例如博客下面的评论,与博客内容是有关联的。
<article> <header> <h1>一篇文章</h1> <p><time pubdate datetime="2012-10-03">2012/10/03</time></p> </header> <p>文章内容..</p> <article> <h2>评论</h2> <article> <header> <h3>评论者: XXX</h3> <p><time pubdate datetime="2012-10-03T19:10-08:00">~1 hour ago</time></p> </header> <p>哈哈哈</p> </article> <article> <header> <h3>评论者: XXX</h3> <p><time pubdate datetime="2012-10-03T19:10-08:00">~1 hour ago</time></p> </header> <p>哈?哈?哈?</p> </article> </article> </article>
因为文章内section 部分虽然也是独立的部分,但是它们只能算是组成整体的一部分,从属关系,article是大主体,section是构成这个大主体的一部分。本网站的全部文章都是article嵌套一个个section章节,这样能让浏览器更容易区分各个章节所包括的内容。
section还可以嵌套article,如下:
<section>
<h1>介绍: 网站制作成员配备</h1> <article> <h2>设计师</h2> <p>设计网页的...</p> </article> <article> <h2>程序员</h2> <p>后台写程序的..</p> </article> <article> <h2>前端工程师</h2> <p>给楼上两位打杂的..</p> </article> </section>
总结:如果是自身独立,用article
是相关内容,用section
没有语义,用div
aside元素:
aside 元素被包含在article元素中作为主要内容的附属信息部分,其中的内容可以是与当前文章有关的相关资料、标签、名次解释等。()也是特殊的section
在article元素之外使用作为页面或站点全局的附属信息部分。
最典型的是:侧边栏 其中的内容可以是日志串连,其他组的导航,甚至是广告,这些内容相关的页面。
<article>
<p>内容</p> <aside> <h1>作者简介</h1> <p>小北,前端一枚</p> </aside> </article>
使用总结:
aside在article内表示主要内容的附属信息,
在article之外则可做侧边栏,没有article与之对应,最好不用。
如果是广告,其他日志链接或者其他分类导航也可以用
html5其他结构元素标签:
html5 节元素标签包括:body article nav aside section header footer hgroup 还有h1~h6 address。
* address 代表区块容器,必须是作为联系信息出现,邮编地址、邮件地址等等,一般出现在footer。
* h1~h6 因为hgroup,section 和 article 的出现,h1~h6定义也发生了变化,允许一张页面出现多个h1.
<main></main>:页面主要内容,一个页面只能使用一次。如果是web应用,则包围其主要功能。
<small></small>:与<strong>相反 通常用于指定*细则*,输入免责声明、注解、署名、版权。(只适用于短语,不要用来标记“使用条款”、“隐私政策”等长的法律声明)
<strong></strong>:加粗 表示内容重要性。
<em></em>:斜体 (强调唯一元素,而strong强调重要程度。)
<figure></figure>:创建图(默认有40px左右的margin)。
<figcaption></figcaption>:figure的标题,必须是figure内嵌的第一个或者最后一个元素。
<cite></cite>:指明引用或者参考,如图书的标题,歌曲、电影、等的名称,演唱会、音乐会、规范、报纸、或法律文件等。
只用于参考源本身,而不是从中引述。
<blockquoto></blockquoto>:引述文本,默认新的一行显示。
<q></q>:短的引述(跨浏览器问题,尽量避免使用)。
可以对blockquoto和q元素使用cite属性(不是cite元素!),对搜索引擎自动化工具有用。cite=“URL”引述来源地址。
<time></time>:标记时间。datetime属性遵循特定格式,如果忽略此属性,文本内容必须是合法的日期或者时间格式。
不再相关的时间用s标签。
<abbr></abbr>:解释缩写词。使用title属性可提供全称,只在第一次出现时使用就ok。
abbr[title]{ border-bottom:1px dotted #000; }
<dfn></dfn>:定义术语元素,与定义必须紧挨着,可以在描述列表dl元素中使用。
<address></address>:作者、相关人士或组织的联系信息(电子邮件地址、指向联系信息页的链接)。
如果提供整个页面的作者联系信息,一般放在页面级footer里。不能包含文档或者文档等其他内容。
<del></del>:移除的内容。
<ins></ins>:添加的内容。
少有的既可以包围块级,又可以包围短语内容的元素。
<code></code>:标记代码。包含示例代码或者文件名 (< < > >)
<pre></pre>:预格式化文本。保留文本固有的换行和空格。
<meter></meter>:表示分数的值或者已知范围的测量结果。如投票结果。
例如:<meter value="0.2" title=”Miles“>20%completed</meter>
<progress></progress>:完成进度。可通过js动态更新value。
参考链接:http://blog.csdn.net/u010543271/article/details/50855363














 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









