






專 欄

项目介绍
所谓探索性数据分析(Exploratory Data Analysis,以下简称EDA),是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。特别是当我们对这些数据中的信息没有足够的经验,不知道该用何种传统统计方法进行分析时,探索性数据分析就会非常有效。探索性数据分析在上世纪六十年代被提出,其方法由美国著名统计学家约翰·图基(John Tukey)命名。
本项目需解决的问题
本项目分析P2P平台Lending Club的贷款数据,探索数据分析过程中,并尝试回答以下3个问题:
1、利率与风险成正比,风险越高,利率越高,违约的可能线性越大,从P2P平台的数据来看,影响风险的因素有哪些?(为后续建模做准备)
2、了解P2P平台的业务特点、产品类型、资产质量、风险定价?
3、有什么建议?
分析思路
我们可以将信贷信息分为信贷硬信息和信贷软信息。
任何可以量化客户的还款能力的信息均可以用作硬信息,可勾勒客户还款意愿的信息则为软信息。
信贷硬信息: 站在企业的角度,硬信息主要包括财务三大报表(资产负债表、利润表和现金流量表)以及信贷记录;站在个人角度硬信息主要包括:个人年收入 、资产状况(借款是否拥有房产、车或理财产品)。
信贷软信息: 过往的信贷记录比较直接了解客户的还款意愿,以往发生违约次数较多的客户再次发生违约的概率相比其他客户大。客户的学历、年龄、目前工作所在单位的级别和性别等信息也可作为软信息。
因此,我们主要围绕着“客户是否具有偿还能力,是否具有偿还意愿”展开探索分析。
项目背景
作为旧金山的一家个人对个人的借贷公司,Lending Club成立于2006年。他们是第一家注册为按照美国证券交易委员会SEC(Securities and Exchange Commission)的安全标准向个人提供个人贷款的借贷公司。与传统借贷机构最大的不同是,Lending Club利用网络技术打造的这个交易平台,直接连接了个人投资者和个人借贷者,通过此种方式,缩短了资金流通的环节,尤其是绕过了传统的大银行等金融机构,使得投资者和借贷者都能得到更多实惠、更快捷。对于投资者来说可以获得更好的回报,而对于借贷者来说,则可以获得相对较低的贷款利率。
Lending Club 介绍:https://www.huxiu.com/article/41472/1.html
数据集
数据集是Lending Club平台发生借贷的业务数据(2017年第二季),具体数据集可以从Lending Club官网下载
本项目报告分析,我将如何运用Python操作数据和探索分析数据的思考过程均记录下来。
前期准备
第一步,导入我们要用的库
注意:不要漏了%matplotlib inline。IPython提供了很多魔法命令,使得在IPython环境中的操作更加得心应手,使用%matplotlib inline在绘图时,将图片内嵌在交互窗口,而不是弹出一个图片窗口。具体请查看Stackoverflow的解释。
获取数据
第二步,使用Pandas解析数据
Pandas是基于NumPy的一个非常好用的库,无论是读取数据、处理数据,用它都非常简单。学习Pandas最好的方法就是查看官方文档 。
数据集的格式是CSV,因此我们用到pandans.read_csv方法,同时也将CSV内容转化成矩阵的格式。

探索分析数据(EDA)
一旦获得了数据,下一步就是检查和探索他们。在这个阶段,主要的目标是合理地检查数据。例如:如果数据有唯一的标记符,是否真的只有一个;数据是什么类型,检查最极端的情况。他们是否有意义,有什么需要删除的吗?数据应该怎么调整才能适用于接下来的分析和挖掘?此外,数据集还有可能存在异常值。同时,我将会通过对数据进行简单的统计测试,并将其可视化。 检查和探索数据的过程非常关键。因为下一步需要清洗和准备处理这些数据,只有进入模型的数据质量是好的,才能构建好的模型。(避免Garbage in, Garbage out)
首先预览基本内容,Pandas为我们提供很多可以方便查看和检查数数据的方法,有df.head(n)、df.tail(n)、df.shape()、http://df.info() 等 。
查看表格的行数和列数
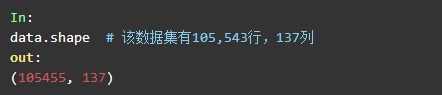

扩大行查看范围

由上图我们发现一些列有很多缺失值,这些缺失值对我们的数据分析没有意义,因此,首先把含有许多缺失值的列删除,同时将已清洗过的数据新建CSV保存。
处理缺失值
统计每列属性缺失值的数量。
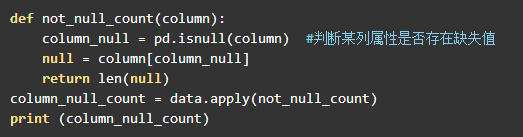

再次用pandas解析预处理过的数据文件并预览基本信息。

数据从137列减少至102列。


Pandas的describe()不能统计数据类型为object的属性,部分数据int_rate和emp_length数据类型都是object,稍后分析数据时需将它们转化为类型为floate的数字类型。
数据集的属性较多,我们初步聚焦几个重要特征展开分析,特别是我们最关心的属性贷款状态。


单变量分析
1.贷款状态分布
处理异常值

由于loan_status异常值为n的数量和贷款金额较小,因此我们直接删异常值所对应的行。

为了更方便分析,我们将贷款状态进行分类变量编码,主要将贷款状态分为正常和违约,贷款状态分类依据主要参考 The 10 loan status variants explained

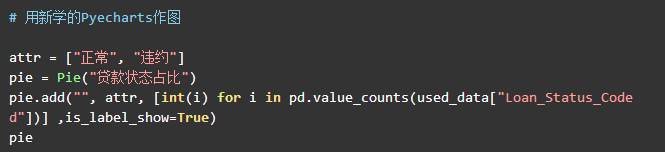
从图中可以看出,平台贷款发生违约的数量占少数。贷款状态为正常的有103,746个,贷款正常状态占比为98.38%。贷款状态将作为我们建模的标签,贷款状态正常和贷款状态违约两者数量不平衡,绝大多数常见的机器学习算法对于不平衡数据集都不能很好地工作,下一篇项目报告中,我们将会解决样本不平衡的问题。
2.贷款金额分布
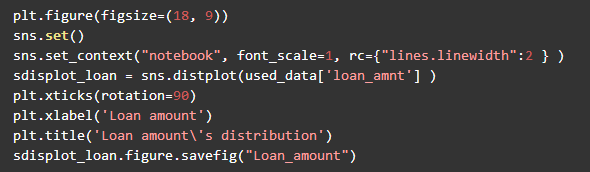
平台贷款呈现右偏正态分布,贷款金额最小值为1,000美元,最大值为40,000美元,贷款金额主要集中在10,000美元左右,中位数为12,000美元,可以看出平台业务主要以小额贷款为主。贷款金额越大风险越大。
3.贷款期限分布

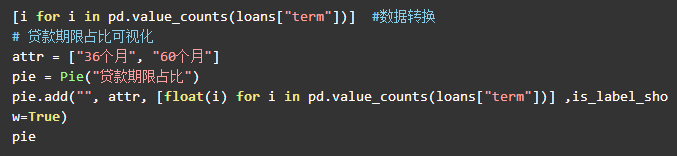
平台贷款产品期限分为36个月和60个月两种,其中贷款期限为60个月的贷款占比为26.88%,贷款期限为36个月的贷款占比为73.12%。一般来说贷款期限越长,不确定性越大,违约的可能性更大,期限较长的贷款产品风险越高 。从期限角度看,平台风险偏小的资产占大部分。
4.贷款产品用途种类比较

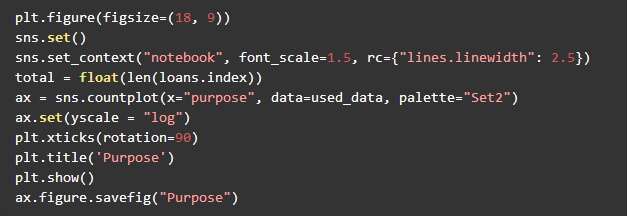
P2P平台贷款用途最多的为债务重组(借新债还旧债),其次是信用卡还款,第三是住房改善。一般来说,贷款用途为债务重组和信用卡还款的客户现金流较为紧张,此类客户也是在传统银行渠道无法贷款才转来P2P平台贷款,这部分客户的偿还贷款能力较弱,发生违约的可能性较高。还有部分贷款用途为Other的贷款,需要通过其他维度来分析其风险。
5.客户信用等级占比


Lending Club平台对客户的信用等级分7类,A~G,信用等级为A的客户信用评分最高,信用等级为G的客户最低,信用等级的客户发生违约的可能性更低。目前,平台客户信用等级占比较多的客户为C类,其次是B类和A类,三者合计占比为81.62%。此外信用等级为E、F、G类的客户占比为6.99%。可以看出Lending Club授信部门对申请人的资信情况把关较严。
6.贷款利率种类分布


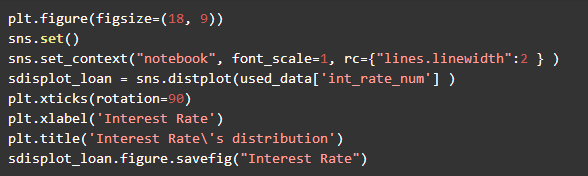
Lending Club平台贷款利率呈现右偏正态分布,利率中位数12.62%,利率最高值为31.00%,利率最小值为5.32%。利率是资金的价格,利率越高,借款人借贷成本越高,借款人违约的可能性越高。

长按扫描关注Python中文社区,
获取更多技术干货!
Python 中 文 社 区
Python中文开发者的精神家园
合作、投稿请联系微信:
pythonpost
1MEwnaxmMz7BPTYzBdj751DPyHWikNoeFS
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









