







树的递归定义
树是n(n>0)个结点的有限集,这个集合满足以下条件:
⑴有且仅有一个结点没有前驱(父亲结点),该结点称为树的根;
⑵除根外,其余的每个结点都有且仅有一个前驱;
⑶除根外,每一个结点都通过唯一的路径连到根上(否则有环)。这条路径由根开始,而未端就在该结点上,且除根以外,路径上的每一个结点都是前一个结点的后继(儿子结点);
由上述定义可知,树结构没有封闭的回路。
节点的分类
结点一般分成三类
⑴根结点:没有父亲的结点。在树中有且仅有一个根结点。如节点r
⑵分支结点:除根结点外,有孩子的结点称为分支结点。如a,b,c,x,t,d,i
⑶叶结点:没有孩子的结点称为树叶。如w,h,e,f,s,m,o,n,j,u
根结点到每一个分支结点或叶结点的路径是唯一的。
从根r到结点i的唯一路径为rcti。
树的度
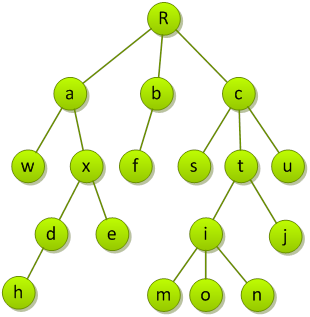
⑴结点的度:一个结点的子树数目称为该结点的度。如结点i的度为3,节点t的度为2,节点b的度为1。显然,所有树叶的度为0。
⑵树的度:所有结点中最大的度称为该树的度(宽度)。 下列树的度为3。如果采用数组存储子节点地址的话,则应根据树的度定义数组大小
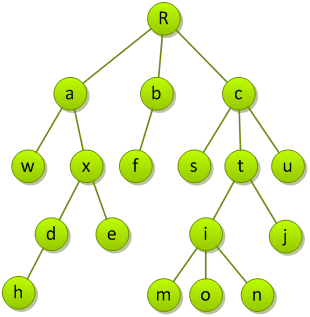
树的深度
树是分层次的。结点所在的层次是从根算起的。根结点在第一层,根的儿子在第二层,其余各层依次类推。即某个节点在第k层,则该节点的后件均在第k+1层。
在树中,父结点在同一层的所有结点构成兄弟关系。
树中最大的层次称为树的深度,亦称高度。图中树的深度为5。
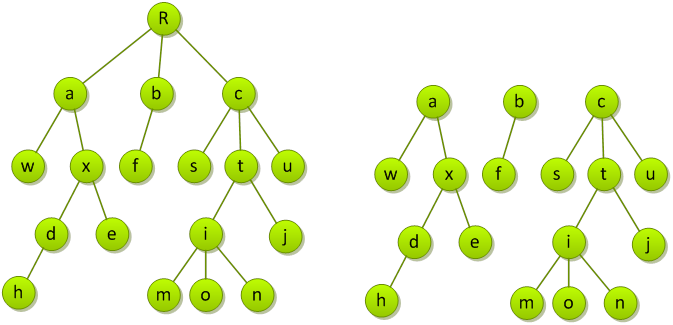
森林
所谓森林,是指若干棵互不相交的树的集合。如图去掉根结点,其原来的三棵子树Ta,Tb,Tc的集合{Ta,Tb,Tc}就为森林,这三棵子树的具体形态如下:
有序树和无序树
按照树中同层结点是否保持有序性,可将树分为有序树和无序树。
(1)如果树中同层结点从左而右排列,其次序不容互换,这样的树称为有序树;
(2)如果同层结点的次序任意,这样的树称为无序树。
树的表示方法
⑴自然界的树形表示法:
用结点和边表示树,例如上图采用的就是自然界的树形表示法。树形表示法一般用于分析问题。
优点:直观,形象;缺点:保存困难。
⑵括号表示法:
先将根结点放入一对圆括号中,然后把它的子树按由左而右的顺序放入括号中,而对子树也采用同样方法处理:同层子树与它的根结点用圆括号括起来,同层子树之间用逗号隔开,最后用闭括号括起来。例如图可写成如下形式
(A(B(E(K,L),F),C(G),D(H(M),I,J)))
优点:易于保存;缺点:不直观
树的遍历规则
所谓树的遍历,是指按照一定的规律不重复地访问(或取出节点中的信息,或对节点做其他的处理)树中的每一个节点,其遍历过程实质上是将树这种非线性结构按一定规律转化为线性结构。
先根次序遍历
后根次序遍历
先根次序遍历树
先根次序遍历的遍历规则为:若树为空,则退出;否则先根访问树的根点,然后先根遍历根的每棵子树。例如,对右图所示树进行先根次序遍历,形成的次序为:
Rawxdhebfcstimonju
算法为:
program preorder(v:integer);
{访问处理节点v;
for i in adj(v) do if i未访问 then preorder(i);
}
后根次序遍历树
后根次序遍历的遍历规则为:若树为空,则退出;否则后根访问每棵子树,然后访问根节点。例如,对右图所示树进行后根次序遍历,形成的次序为:
whdexafbsmonijtucR
算法为:
program postorder(v:integer);
{for i in adj(v) do if i未访问 then postorder(i);
访问处理节点v;
}














 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









