分析的源码是基于Hadoop2.6.0。
官网上面的MapReduce过程
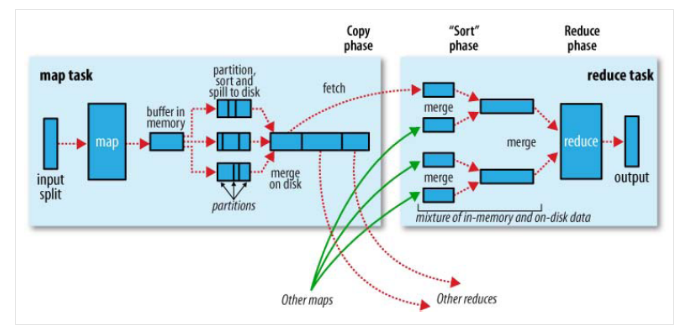
Map端shuffle的过程:
在执行每个map task时,无论map方法中执行什么逻辑,最终都是要把输出写到磁盘上。如果没有reduce阶段,则直接输出到hdfs上,如果有有reduce作业,则每个map方法的输出在写磁盘前线在内存中缓存。每个map task都有一个环状的内存缓冲区,存储着map的输出结果,在每次当缓冲区快满的时候由一个独立的线程将缓冲区的数据以一个溢出文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有溢出文件做合并,被合并成已分区且已排序的输出文件。然后等待reduce task来拉数据。
二、 流程描述
1、 在child进程调用到runNewMapper时,会设置output为NewOutputCollector,来负责map的输出。
2、 在map方法的最后,不管经过什么逻辑的map处理,最终一般都要调用到TaskInputOutputContext的write方法,进而调用到设置的output即NewOutputCollector的write方法。
3、NewOutputCollector其实只是对MapOutputBuffer的一个封装,其write方法调用的是MapOutputBuffer的collect方法。
4、MapOutputBuffer的collect方法中把key和value序列化后存储在一个环形缓存中,如果缓存满了则会调用startspill方法设置信号量,使得一个独立的线程SpillThread可以对缓存中的数据进行处理。
5、SpillThread线程的run方法中调用sortAndSpill方法对缓存中的数据进行排序后写溢出文件。
6、当map输出完成后,会调用output的close方法。
7、在close方法中调用flush方法,对剩余的缓存进行处理,最后调用mergeParts方法,将前面过程的多个溢出文件合并为一个。
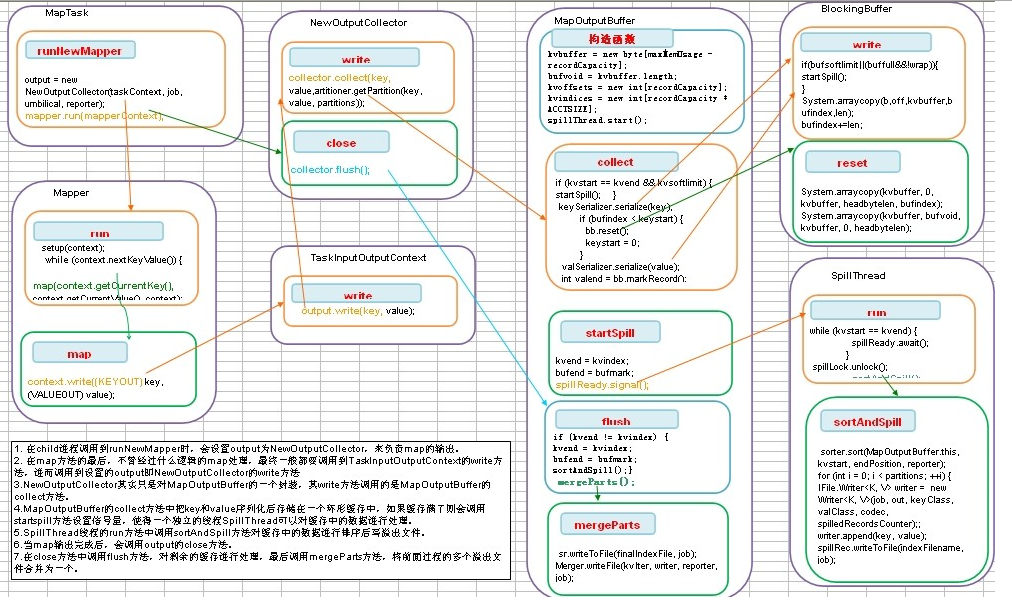
对上面流程进行解释:
1、对第一步介绍:
MapTask中的run方法会根据新旧api选择执行的Mapper函数。
if (useNewApi) {
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {
runOldMapper(job, splitMetaInfo, umbilical, reporter);
}
在runNewMapper方法的执行过程如下:
void runNewMapper( job, splitIndex,umbilical,TaskReporter reporter){
mapper = ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),splitIndex.getStartOffset());
input = new NewTrackingRecordReader(split, inputFormat, reporter, taskContext);
if (job.getNumReduceTasks() == 0) {
output = new NewDirectOutputCollector(taskContext, job, umbilical,
reporter);
} else {
output = new NewOutputCollector(taskContext, job, umbilical,
reporter);
}
mapContext = new MapContextImpl(job, getTaskID(), input, output, committer, reporter, split);
mapperContext = new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>()
.getMapContext(mapContext);
try {
input.initialize(split, mapperContext);
mapper.run(mapperContext);
input.close();
output.close(mapperContext);
} finally {
closeQuietly(input);
closeQuietly(output, mapperContext);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
2、对第二步进行介绍:
Mapper类中的map方法中的Content继承了MapContext,MapContext继承了TaskInputOutputContext。
而在runNewMapper方法中的mapperContext变量,实现了对out的封装。而out是NewOutputCollector类型变量。不管经过什么逻辑的map处理,最终一般都要调用到TaskInputOutputContext的write方法,进而调用到设置的output即NewOutputCollector的write方法
3、对第三步进行介绍:
NewOutputCollector实现了对MapOutputCollector的封装
private class NewOutputCollector<K, V> extendsRecordWriter<K, V> {
private final MapOutputCollector<K, V> collector;
NewOutputCollector(JobContext jobContext,
JobConf job, TaskUmbilicalProtocol umbilical,
TaskReporter reporter) {
collector = createSortingCollector(job, reporter);
}
@Override
public void write(K key, V value) {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}
@Override
public void close(TaskAttemptContext context) throws IOException,
InterruptedException {
try {
collector.flush();
} catch (ClassNotFoundException cnf) {
throw new IOException("can't find class ", cnf);
}
collector.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
其中MapOutputBuffer实现了MapOutputCollector接口。所以NewOutputCollector中的write方法调用的是MapOutputBuffer的collect方法。
什么是MapOutputBuffer
MapOutputBuffer是一个用来暂时存储map输出的缓冲区,它的缓冲区大小是有限的,当写入的数据超过缓冲区的设定的阀值时,需要将缓冲区的数据溢出写入到磁盘,这个过程称之为spill,spill的动作会通过Condition通知给SpillThread,由SpillThread完成具体的处理过程。MR采用了循环缓冲区,做到数据在spill的同时,仍然可以向剩余空间继续写入数据 。
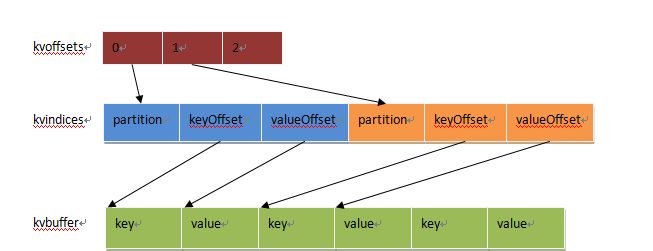
缓冲区之间的关系,从上图即可一目了然。 kvoffsets作为一级索引,是用来表示每个k,v在kvindices中的位置。当对kvbuffer中的某一个分区的KeyValue序列进行排序时,排序结果只需要将kvoffsets中对应的索引项进行交换即可,保证kvoffsets中索引的顺序其实就想记录的KeyValue的真实顺序。换句话说,我们要对一堆对象进行排序,实际上只要记录他们索引的顺序即可,原始记录保持不动,而kvoffsets就是一堆整数的序列,交换起来快得多。 kvindices中的内容为:分区号、Key和Value在kvbuffer中的位置。通过解析这个数组,就可以得到某个分区的所有KV的位置。之所以需要按照分区号提取,是因为Map的输出结果需要分为多份,分别送到不同的Reduce任务,否则还需要对key进行计算才得到分区号。 kvbuffer存储了实际的k,v。k,v的大小不向索引区一样明确的是一对占一个int,可能会出现尾部的一个key被拆分两部分,一步存在尾部,一部分存在头部,但是key为保证有序会交给RawComparator进行比较,而comparator对传入的key是需要有连续的,那么由此可以引出key在尾部剩余空间存不下时,如何处理。处理方法是,当尾部存不下,先存尾部,剩余的存头部,同时在copy key存到接下来的位置,但是当头部开始,存不下一个完整的key,会付出溢出flush到磁盘。当碰到整个buffer都存储不下key,那么会抛出异常
MapBufferTooSmallException表示buffer太小容纳不小.
MapOutputBuffer初始化分析
// k/v serialization
comparator = job.getOutputKeyComparator()
keyClass = (Class<K>)job.getMapOutputKeyClass()
valClass = (Class<V>)job.getMapOutputValueClass()
serializationFactory = new SerializationFactory(job)
keySerializer = serializationFactory.getSerializer(keyClass)
keySerializer.open(bb)
valSerializer = serializationFactory.getSerializer(valClass)
valSerializer.open(bb)
comparator是key之间用于比较的类,在没有设置的情况下,默认是key所属类里面的一个子类,这个子类继承自WritableComparator。以Text作为key为例,就是class Comparator extends WritableComparator。Map处理的输入并不排序,会对处理完毕后的结果进行排序,此时就会用到该比较器。
serializationFactory,序列化工厂类,其功能是从配置文件中读取序列化类的集合。Map处理的输出是Key,Value集合,需要进行序列化才能写到缓存以及文件中。
keySerializer和valSerializer这两个序列化对象,通过序列化工厂类中获取到的。序列化和反序列化的操作基本类似,都是打开一个流,将输出写入流中或者从流中读取数据。
keySerializer.open(bb)和valSerializer.open(bb)打开的是流,但不是文件流,而是BlockingBuffer,也就是说后续调用serialize输出key/value的时候,都是先写入到Buffer中。这里又涉及一个变量bb。
其定义是:BlockingBuffer bb = new BlockingBuffer()。使用BlockingBuffer的意义在于将序列化后的Key或Value送入BlockingBuffer。BlockingBuffer内部又引入一个类:Buffer。Buffer实际上最终也封装了一个字节缓冲区byte[] kvbuffer,Map之后的结果暂时都会存入kvbuffer这个缓存区,等到要慢的时候再刷写到磁盘,Buffer这个类的作用就是对kvbuffer进行封装,比如在其write方法中存在以下代码:
public synchronized void write(byte b[], int off, int len)
{
spillLock.lock();
try {
do {
.......
} while (buffull && !wrap);
} finally {
spillLock.unlock();
}
if (buffull) {
final int gaplen = bufvoid - bufindex;
System.arraycopy(b, off, kvbuffer, bufindex, gaplen);
len -= gaplen;
off += gaplen;
bufindex = 0;
}
System.arraycopy(b, off, kvbuffer, bufindex, len);
bufindex += len;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
上面的 System.arraycopy 就是将要写入的b(序列化后的数据)写入到 kvbuffer中。因此,Buffer相当于封装了kvbuffer,实现环形缓冲区等功能,BlockingBuffer则继续对此进行封装,使其支持内部Key的比较功能。
那么,上面write这个方法又是什么时候调用的呢?实际上就是MapOutputBuffer的collect方法中,会对KeyValue进行序列化,在序列化方法中,会进行写入:
public void serialize(Writable w) throws IOException {
w.write(dataOut);
}
此处的dataout就是前面 keySerializer.open(bb)这一 方法中传进来的,也就是BlockingBuffer(又封装了Buffer):
public void open(OutputStream out) {
if (out instanceof DataOutputStream) {
dataOut = (DataOutputStream) out;
} else {
dataOut = new DataOutputStream(out);
}
}
因此,当执行序列化方法serialize的时候,会调用Buffer的write方法,最终将数据写入byte[] kvbuffer。
collect分析
这里分析的collect是MapOutputBuffer中的collect方法,在用户层的map方法内调用collector.collect最终会一层层调用到MapOutputBuffer.collect。
collect的代码我们分为两部分来看,一部分是根据索引区来检查是否需要触发spill,另外一部分是操作buffer并更新索引区的记录。
第一部分代码如下
if (bufferRemaining <= 0) {
spillLock.lock();
try {
do {
if (!spillInProgress) {
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
final int bUsed = distanceTo(kvbidx, bufindex);
final boolean bufsoftlimit = bUsed >= softLimit;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
resetSpill();
bufferRemaining = Math.min(
distanceTo(bufindex, kvbidx) - 2 * METASIZE,
softLimit - bUsed) - METASIZE;
continue;
} else if (bufsoftlimit && kvindex != kvend) {
startSpill();
final int avgRec = (int)
(mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
final int distkvi = distanceTo(bufindex, kvbidx);
final int newPos = (bufindex +
Math.max(2 * METASIZE - 1,
Math.min(distkvi / 2,
distkvi / (METASIZE + avgRec) * METASIZE)))
% kvbuffer.length;
setEquator(newPos);
bufmark = bufindex = newPos;
final int serBound = 4 * kvend;
bufferRemaining = Math.min(
distanceTo(bufend, newPos),
Math.min(
distanceTo(newPos, serBound),
softLimit)) - 2 * METASIZE;
}
}
} while (false);
} finally {
spillLock.unlock();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
其中的resetSpill()是处理有key存在尾部存了一部分,头部存了一部分的情况。由于key的比较函数需要的是一个连续的key,因此需要对key进行特殊处理。
startSpill() 是为了激活spill
private void startSpill() {
assert !spillInProgress;
kvend = (kvindex + NMETA) % kvmeta.capacity();
bufend = bufmark;
spillInProgress = true;
spillReady.signal();
}
第二部分代码。
try {
int keystart = bufindex;
keySerializer.serialize(key);
if (bufindex < keystart) {
bb.shiftBufferedKey();
keystart = 0;
}
final int valstart = bufindex;
valSerializer.serialize(value);
bb.write(b0, 0, 0);
int valend = bb.markRecord();
mapOutputRecordCounter.increment(1);
mapOutputByteCounter.increment(
distanceTo(keystart, valend, bufvoid));
kvmeta.put(kvindex + PARTITION, partition);
kvmeta.put(kvindex + KEYSTART, keystart);
kvmeta.put(kvindex + VALSTART, valstart);
kvmeta.put(kvindex + VALLEN, distanceTo(valstart, valend));
kvindex = (kvindex - NMETA + kvmeta.capacity()) % kvmeta.capacity();
} catch (MapBufferTooSmallException e) {
LOG.info("Record too large for in-memory buffer: " + e.getMessage());
spillSingleRecord(key, value, partition);
mapOutputRecordCounter.increment(1);
return;
}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
SpillThread的run方法。
public void run() {
spillLock.lock();
spillThreadRunning = true;
try {
while (true) {
spillDone.signal();
while (!spillInProgress) {
spillReady.await();
}
try {
spillLock.unlock();
sortAndSpill();
} catch (Throwable t) {
sortSpillException = t;
} finally {
spillLock.lock();
if (bufend < bufstart) {
bufvoid = kvbuffer.length;
}
kvstart = kvend;
bufstart = bufend;
spillInProgress = false;
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
spillLock.unlock();
spillThreadRunning = false;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
SpillThread线程的run方法中调用sortAndSpill把缓存中的输出写到格式为+ ‘/spill’ + spillNumber + ‘.out’的spill文件中。索引(kvindices)保持在spill{spill号}.out.index中,数据保存在spill{spill号}.out中 创建SpillRecord记录,输出文件和IndexRecord记录,然后,需要在kvoffsets上做排序,排完序后顺序访问kvoffsets,也就是按partition顺序访问记录。按partition循环处理排完序的数组,如果没有combiner,则直接输出记录,否则,调用combineAndSpill,先做combin然后输出。循环的最后记录IndexRecord到SpillRecord。
sortAndSpill 函数
private void sortAndSpill() throws IOException, ClassNotFoundException,InterruptedException {
........
try {
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
.......
for (int i = 0; i < partitions; ++i) {
IFile.Writer<K, V> writer = null;
try {
if (combinerRunner == null) {
.......
writer.append(key, value);
.......
}
} else {
.......
combinerRunner.combine(kvIter, combineCollector);
.......
}
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength()
+ CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength()
+ CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, i);
} finally {
if (null != writer)
writer.close();
}
}
if (totalIndexCacheMemory >= indexCacheMemoryLimit) {
Path indexFilename = mapOutputFile
.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
spillRec.writeToFile(indexFilename, job);
} else {
indexCacheList.add(spillRec);
totalIndexCacheMemory += spillRec.size()
* MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
} finally {
if (out != null)
out.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
MapOutputBuffer的compare方法和swap方法
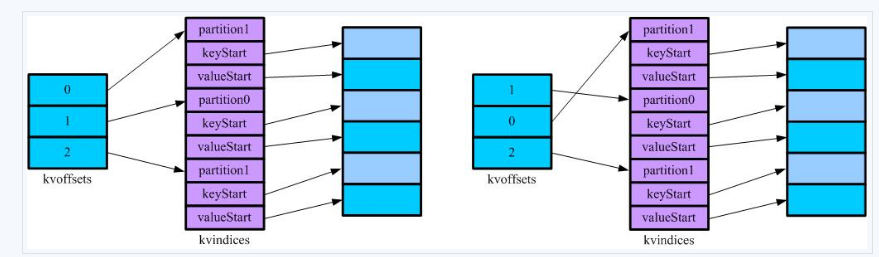
MapOutputBuffer实现了IndexedSortable接口,从接口命名上就可以猜想到,这个排序不是移动数据,而是移动数据的索引。在这里要排序的其实是kvindices对象,通过移动其记录在kvoffets上的索引来实现。 如图,表示了写磁盘前Sort的效果。kvindices保持了记录所属的(Reduce)分区,key在缓冲区开始的位置和value在缓冲区开始的位置,通过kvindices,我们可以在缓冲区中找到对应的记录。kvoffets用于在缓冲区满的时候对kvindices的partition进行排序,排完序的结果将输出到输出到本地磁盘上,其中索引(kvindices)保持在spill{spill号}.out.index中,数据保存在spill{spill号}.out中。通过观察MapOutputBuffer的compare知道,先是在partition上排序,然后是在key上排序。
public int compare(final int mi, final int mj) {
final int kvi = offsetFor(mi % maxRec);
final int kvj = offsetFor(mj % maxRec);
final int kvip = kvmeta.get(kvi + PARTITION);
final int kvjp = kvmeta.get(kvj + PARTITION);
if (kvip != kvjp) {
return kvip - kvjp;
}
return comparator.compare(kvbuffer,
kvmeta.get(kvi + KEYSTART),
kvmeta.get(kvi + VALSTART) - kvmeta.get(kvi + KEYSTART),
kvbuffer,
kvmeta.get(kvj + KEYSTART),
kvmeta.get(kvj + VALSTART) - kvmeta.get(kvj + KEYSTART));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
flush分析
我们看看flush是在哪个时间段调用的,在文章开始处说到runOldMapper处理的时候,有提到,代码如下:
runner.run(in, new OldOutputCollector(collector, conf), reporter)
collector.flush()
Mapper的结果都已经被collect了,需要对缓冲区做一些最后的清理,调用flush方法,合并spill{n}文件产生最后的输出。先等待可能的spill过程完成,然后判断缓冲区是否为空,如果不是,则调用sortAndSpill,做最后的spill,然后结束spill线程.
public void flush() throws IOException, ClassNotFoundException,
InterruptedException {
spillLock.lock();
try {
while (spillInProgress) {
reporter.progress();
spillDone.await();
}
checkSpillException();
final int kvbend = 4 * kvend;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
resetSpill();
}
if (kvindex != kvend) {
kvend = (kvindex + NMETA) % kvmeta.capacity();
bufend = bufmark;
sortAndSpill();
}
} catch (InterruptedException e) {
throw new IOException("Interrupted while waiting for the writer", e);
} finally {
spillLock.unlock();
}
assert !spillLock.isHeldByCurrentThread();
try {
spillThread.interrupt();
spillThread.join();
} catch (InterruptedException e) {
throw new IOException("Spill failed", e);
}
kvbuffer = null;
mergeParts();
Path outputPath = mapOutputFile.getOutputFile();
fileOutputByteCounter.increment(rfs.getFileStatus(outputPath).getLen());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
MapTask.MapOutputBuffer的mergeParts()方法.
从不同溢写文件中读取出来的,然后再把这些值加起来。因为merge是将多个溢写文件合并到一个文件,所以可能也有相同的key存在,在这个过程中如果配置设置过Combiner,也会使用Combiner来合并相同的key。?mapreduce让每个map只输出一个文件,并且为这个文件提供一个索引文件,以记录每个reduce对应数据的偏移量。
private void mergeParts() throws IOException, InterruptedException,
ClassNotFoundException {
..........
{
IndexRecord rec = new IndexRecord();
final SpillRecord spillRec = new SpillRecord(partitions);
for (int parts = 0; parts < partitions; parts++) {
List<Segment<K, V>> segmentList = new ArrayList<Segment<K, V>>(
numSpills);
for (int i = 0; i < numSpills; i++) {
IndexRecord indexRecord = indexCacheList.get(i)
.getIndex(parts);
Segment<K, V> s = new Segment<K, V>(job, rfs,
filename[i], indexRecord.startOffset,
indexRecord.partLength, codec, true);
segmentList.add(i, s);
}
}
........
@SuppressWarnings("unchecked")
RawKeyValueIterator kvIter = Merger.merge(job, rfs,
keyClass, valClass, codec, segmentList,
mergeFactor, new Path(mapId.toString()),
job.getOutputKeyComparator(), reporter,
sortSegments, null, spilledRecordsCounter,
sortPhase.phase(), TaskType.MAP);
long segmentStart = finalOut.getPos();
FSDataOutputStream finalPartitionOut = CryptoUtils
.wrapIfNecessary(job, finalOut);
Writer<K, V> writer = new Writer<K, V>(job,
finalPartitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
if (combinerRunner == null
|| numSpills < minSpillsForCombine) {
Merger.writeFile(kvIter, writer, reporter, job);
} else {
combineCollector.setWriter(writer);
combinerRunner.combine(kvIter, combineCollector);
}
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength()
+ CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength()
+ CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, parts);
}
spillRec.writeToFile(finalIndexFile, job);
finalOut.close();
for (int i = 0; i < numSpills; i++) {
rfs.delete(filename[i], true);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
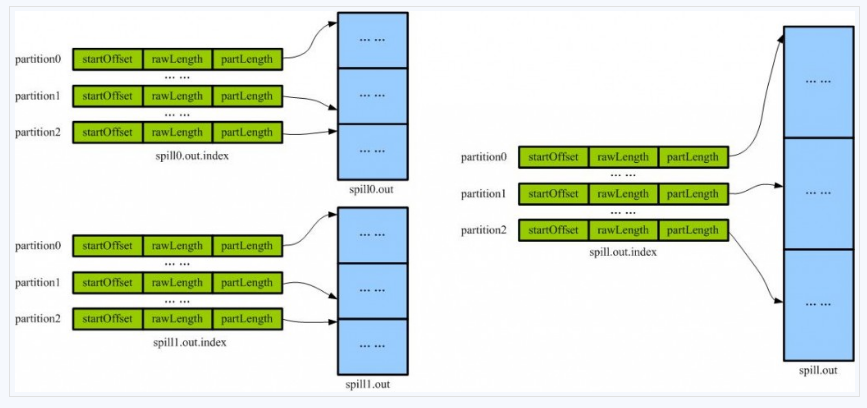
merge最终生成一个spill.out和spill.out.index文件
从前面的分析指导,多个partition的都在一个输出文件中,但是按照partition排序的。即把maper输出按照partition分段了。一个partition对应一个reducer,因此一个reducer只要获取一段即可。
参考文章
http://www.cnblogs.com/jirimutu01/p/4553678.html
http://www.it165.net/pro/html/201402/9903.html
http://blog.csdn.net/gjt19910817/article/details/37843135
原文地址
http://blog.csdn.net/u010143774/article/details/51460947
























 4726
4726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









