









一、软件安装并配置
1.JDK配置
1) 安装jdk
2) 配置环境变量
JAVA_HOME、CLASSPATH、PATH等设置,这里就不多介绍,网上很多资料
2.Eclipse
1).下载eclipse-jee-kepler-SR2-win32-x86_64.zip
2).解压到本地磁盘,如图所示:
3.Ant
1)下载
http://ant.apache.org/bindownload.cgi
apache-ant-1.9.4-bin.zip
2)解压到一个盘,如图所示:
3).环境变量的配置
新建ANT_HOME=E:\ant\apache-ant-1.9.4-bin\apache-ant-1.9.4
在PATH后面加;%ANT_HOME%\bin
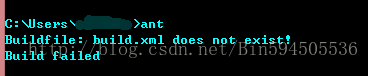
4)cmd 测试一下是否配置正确
ant version 如图所示:

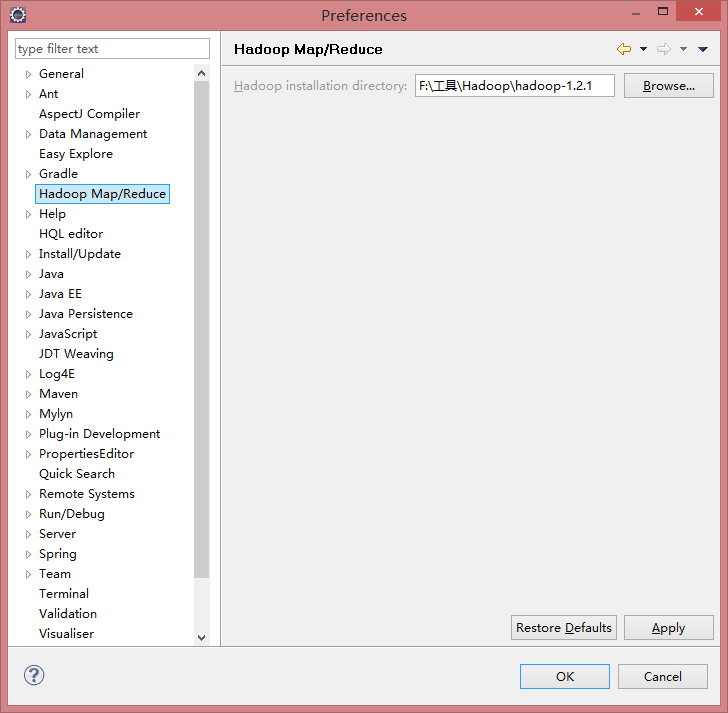
4.Hadoop
1).下载hadoop包
hadoop-2.6.0.tar.gz
解压到本地磁盘,如图所示:

5 下载hadoop2x-eclipse-plugin源代码
1)目前hadoop2的eclipse-plugins源代码由github脱管,下载地址是https://github.com/winghc/hadoop2x-eclipse-plugin,然后在右侧的Download ZIP连接点击下载
2)下载hadoop2x-eclipse-plugin-master.zip
解压到本地磁盘,如图所示:
二、编译hadoop-eclipse-plugin插件
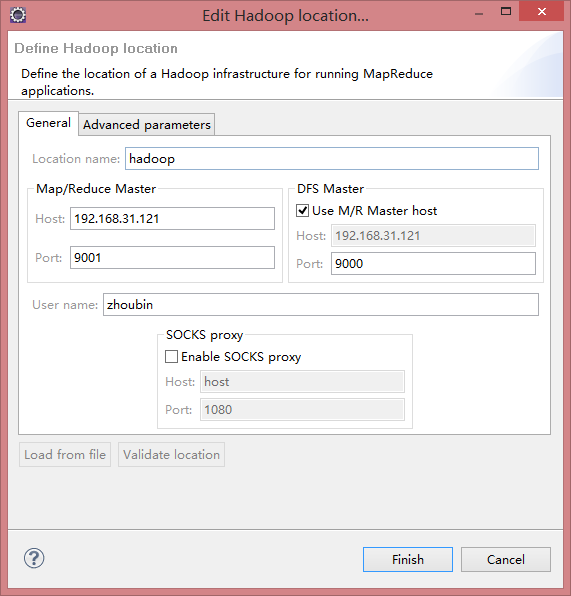
1.hadoop2x-eclipse-plugin-master解压在F盘(以下简称H2EP_HOME),打开命令行cmd,切换到F:\Workspaces\workspace_test\hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin 目录
2.执行ant jar
ant jar -Dversion=2.6.0 -Declipse.home=eclipse的解压目录 -Dhadoop.home=hadoop的解压目录,如图所示:

3 命令行在ivy-resolve-common处卡了
原因是找不到几个依赖包,那几个依赖包可能是换路径了,其实不需要这几个依赖包也可以
解决方案:修改"H2EP_HOME"\src\contrib\eclipse-plugin\build.xml
找到:
<target name="compile" depends="init, ivy-retrieve-common" unless="skip.contrib">
去掉depends修改为
<target name="compile" unless="skip.contrib">
再次执行ant jar -Dversion=2.6.0 -Declipse.home=eclipse的解压目录 -Dhadoop.home=hadoop的解压目录,会提示copy不到相关jar包的错误,
解决方案:
修改"H2EP_HOME"\ivy\libraries.properties文件,
将报错的jar包版本号跟换成与"HADOOP_HOME"\share\hadoop\common\lib下面jar对应的版本号
此步可能会有多个jar包版本不匹配,需要多次修改
|
package
test;
import
java.io.IOException;
import
java.util.StringTokenizer;
import
org.apache.hadoop.conf.Configuration;
import
org.apache.hadoop.fs.Path;
import
org.apache.hadoop.io.IntWritable;
import
org.apache.hadoop.io.Text;
import
org.apache.hadoop.mapreduce.Job;
import
org.apache.hadoop.mapreduce.Mapper;
import
org.apache.hadoop.mapreduce.Reducer;
import
org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public
class
WordCount {
public
static
class
TokenizerMapper
extends
Mapper<Object, Text, Text, IntWritable> {
private
final
static
IntWritable
one
=
new
IntWritable(1);
private
Text
word
=
new
Text();
public
void
map(Object key, Text value, Context context)
throws
IOException, InterruptedException {
StringTokenizer itr =
new
StringTokenizer(value.toString());
while
(itr.hasMoreTokens()) {
word
.set(itr.nextToken());
context.write(
word
,
one
);
}
}
}
public
static
class
IntSumReducer
extends
Reducer<Text, IntWritable, Text, IntWritable> {
private
IntWritable
result
=
new
IntWritable();
public
void
reduce(Text key, Iterable<IntWritable> values, Context context)
throws
IOException, InterruptedException {
int
sum = 0;
for
(IntWritable val : values) {
sum += val.get();
}
result
.set(sum);
context.write(key,
result
);
}
}
public
static
void
main(String[] args)
throws
Exception {
Configuration conf =
new
Configuration();
Job job = Job. getInstance(conf,
"word count"
);
job.setJarByClass(WordCount.
class
);
job.setMapperClass(TokenizerMapper.
class
);
job.setCombinerClass(IntSumReducer.
class
);
job.setReducerClass(IntSumReducer.
class
);
job.setOutputKeyClass(Text.
class
);
job.setOutputValueClass(IntWritable.
class
);
FileInputFormat. addInputPath(job,
new
Path(args[0]));
FileOutputFormat. setOutputPath(job,
new
Path(args[1]));
System. exit(job.waitForCompletion(
true
) ? 0 : 1);
}
}
|
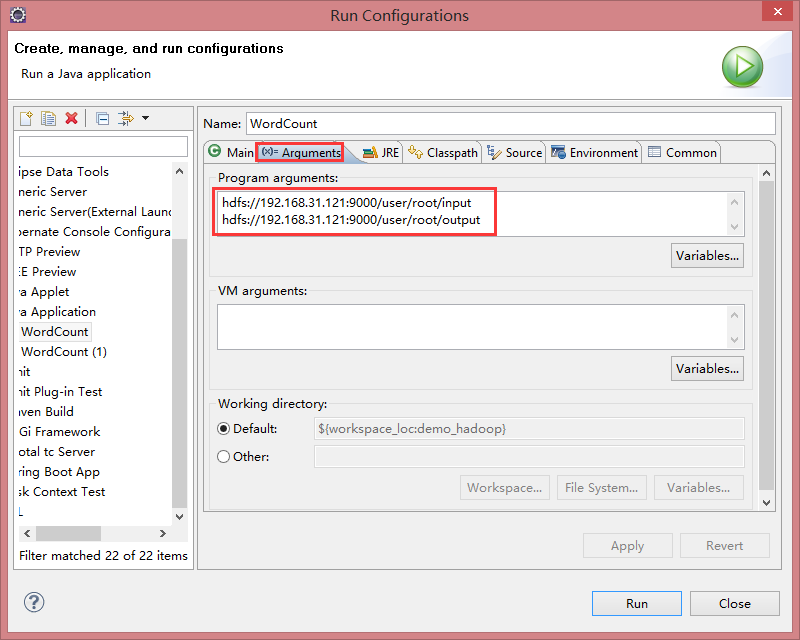
|
private
static
void
checkReturnValue(
boolean
rv, File p,
FsPermission permission
)
throws
IOException {
/**
if (! rv) {
throw new IOException("Failed to set permissions of path: " + p +
" to " +
String.format("%04o", permission.toShort()));
}
*/
}
|














 2187
2187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









