







先模拟登录
再爬取照片
# -*- coding:utf-8 -*-
import urllib
import urllib2
import cookielib
import re
import webbrowser
import tool
import os
#模拟登录淘宝类
class Taobao:
#初始化方法
def __init__(self):
#登录的URL
self.siteURL = 'http://mm.taobao.com/json/request_top_list.htm'
self.loginURL = "https://login.taobao.com/member/login.jhtml"
#代理IP地址,防止自己的IP被封禁
self.proxyURL = 'http://120.193.146.97:843'
#登录POST数据时发送的头部信息
self.loginHeaders = {
'Host':'login.taobao.com',
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:42.0) Gecko/20100101 Firefox/42.0',
'Referer' : 'https://login.taobao.com/member/login.jhtml',
'Content-Type': 'application/x-www-form-urlencoded',
'Connection' : 'Keep-Alive'
}
#用户名
self.username = 'xxxxxxxxxxxxxxxxxx'
#ua字符串,经过淘宝ua算法计算得出,包含了时间戳,浏览器,屏幕分辨率,随机数,鼠标移动,鼠标点击,其实还有键盘输入记录,鼠标移动的记录、点击的记录等等的信息
self.ua = '008#JxEAdwAWAjoAAAAAADM4AAcBABQ5AQEBFaNLXlJ0Y2xodVJ1YHVoYgUBABo5BcsAuAEBAQES6QFLXlJ0Y2xodVJ1YHVoYhYBAAQ3AQEBBAEACTcEBgCuAQEBxwQBAAk3BD0AoAEBAaMWAQAENwEBAQ0BABo+AQ9WaG9lbnZyITZWSE8hMDgtMS0xLTMzNwwBADcBMDU1NjAwOTY1NDM2OTsyZ2U5ZGQ1ZDViZGNlZTM4OTA5MDdkYDkyMzA5NmU2YDUzNzczNWBjFAEABjcDJe08pBcBAAQ3AQH8AQEACDcBAFHv/q+/AgEABjQBAwA1MxMBABY2BI4BEHRzKXJzKUZkKSMjKmBzZnRsCwEApjeKARZpdXVxcjsuLm1uZmhvL3VgbmNgbi9ibmwubGRsY2RzLm1uZmhvL2tpdWxtPnJxbDxgMzBjbi82NjM1ODMzLzA4ODY0NzIzNzgvMC9PUEw4ZnYnZzx1bnEnc2RlaHNkYnVUU008aXV1cXIkMzQyQCQzNDNHJDM0M0d2dnYvdWBuY2BuL2JubCQzNDNHaXV1cXI7Li52dnYvdWBuY2BuL2JubC4DAQAoNwEBYAEBAQEBAQZuAQECfAEBBoEBAQU5AQEGgQEBBREBAQEBAQEBAQQBAAk3BHgAhQEBAV8EAQAJNwRjAJABAQF+BAEACTcF6AC1AQEB8AUBABQ3BcgAVgEBAQENqAAFZQHoAecB5xYBAAQ3AQEBBwEAFDkAAQES80teUnRjbGh1UnVgdWhiBwEABjcBAQEVrA=='
#密码,在这里不能输入真实密码,淘宝对此密码进行了加密处理,256位,此处为加密后的密码
self.password2 = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx每个人不一样哦'
self.post = post = {
'ua':self.ua,
'TPL_checkcode':'',
'CtrlVersion': '1,0,0,7',
'TPL_password':'',
'TPL_redirect_url':'http://i.taobao.com/my_taobao.htm?nekot=udm8087E1424147022443',
'TPL_username':self.username,
'loginsite':'0',
'newlogin':'0',
'from':'tb',
'fc':'default',
'style':'default',
'css_style':'',
'tid':'XOR_1_000000000000000000000000000000_625C4720470A0A050976770A',
'support':'000001',
'loginType':'4',
'minititle':'',
'minipara':'',
'umto':'NaN',
'pstrong':'3',
'llnick':'',
'sign':'',
'need_sign':'',
'isIgnore':'',
'full_redirect':'',
'popid':'',
'callback':'',
'guf':'',
'not_duplite_str':'',
'need_user_id':'',
'poy':'',
'gvfdcname':'10',
'gvfdcre':'',
'from_encoding ':'',
'sub':'',
'TPL_password_2':self.password2,
'loginASR':'1',
'loginASRSuc':'1',
'allp':'',
'oslanguage':'zh-CN',
'sr':'1366*768',
'osVer':'windows|6.1',
'naviVer':'firefox|35'
}
#将POST的数据进行编码转换
self.postData = urllib.urlencode(self.post)
#设置代理
self.proxy = urllib2.ProxyHandler({'http':self.proxyURL})
#设置cookie
self.cookie = cookielib.LWPCookieJar()
#设置cookie处理器
self.cookieHandler = urllib2.HTTPCookieProcessor(self.cookie)
#设置登录时用到的opener,它的open方法相当于urllib2.urlopen
self.opener = urllib2.build_opener(self.cookieHandler,self.proxy,urllib2.HTTPHandler)
#赋值J_HToken
self.J_HToken = ''
#登录成功时,需要的Cookie
self.newCookie = cookielib.CookieJar()
#登陆成功时,需要的一个新的opener
self.newOpener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.newCookie))
#引入工具类
self.tool = tool.Tool()
#得到是否需要输入验证码,这次请求的相应有时会不同,有时需要验证有时不需要
def needCheckCode(self):
#第一次登录获取验证码尝试,构建request
request = urllib2.Request(self.loginURL,self.postData,self.loginHeaders)
#得到第一次登录尝试的相应
response = self.opener.open(request)
#获取其中的内容
content = response.read().decode('gbk')
#获取状态吗
status = response.getcode()
#状态码为200,获取成功
if status == 200:
print u"获取请求成功"
#\u8bf7\u8f93\u5165\u9a8c\u8bc1\u7801这六个字是请输入验证码的utf-8编码
pattern = re.compile(u'\u8bf7\u8f93\u5165\u9a8c\u8bc1\u7801',re.S)
result = re.search(pattern,content)
#如果找到该字符,代表需要输入验证码
if result:
print u"此次安全验证异常,您需要输入验证码"
return content
#否则不需要
else:
#返回结果直接带有J_HToken字样,表明直接验证通过
tokenPattern = re.compile('id="J_HToken" value="(.*?)"')
tokenMatch = re.search(tokenPattern,content)
if tokenMatch:
self.J_HToken = tokenMatch.group(1)
print u"此次安全验证通过,您这次不需要输入验证码"
return False
else:
print u"获取请求失败"
return None
#得到验证码图片
def getCheckCode(self,page):
#得到验证码的图片
pattern = re.compile('<img id="J_StandardCode_m.*?data-src="(.*?)"',re.S)
#匹配的结果
matchResult = re.search(pattern,page)
#已经匹配得到内容,并且验证码图片链接不为空
if matchResult and matchResult.group(1):
return matchResult.group(1)
else:
print u"没有找到验证码内容"
return False
#输入验证码,重新请求,如果验证成功,则返回J_HToken
def loginWithCheckCode(self):
#提示用户输入验证码
checkcode = raw_input('请输入验证码:')
#将验证码重新添加到post的数据中
self.post['TPL_checkcode'] = checkcode
#对post数据重新进行编码
self.postData = urllib.urlencode(self.post)
try:
#再次构建请求,加入验证码之后的第二次登录尝试
request = urllib2.Request(self.loginURL,self.postData,self.loginHeaders)
#得到第一次登录尝试的相应
response = self.opener.open(request)
#获取其中的内容
content = response.read().decode('gbk')
#检测验证码错误的正则表达式,\u9a8c\u8bc1\u7801\u9519\u8bef 是验证码错误五个字的编码
pattern = re.compile(u'\u9a8c\u8bc1\u7801\u9519\u8bef',re.S)
result = re.search(pattern,content)
#如果返回页面包括了,验证码错误五个字
if result:
print u"验证码输入错误"
return False
else:
#返回结果直接带有J_HToken字样,说明验证码输入成功,成功跳转到了获取HToken的界面
tokenPattern = re.compile('id="J_HToken" value="(.*?)"')
tokenMatch = re.search(tokenPattern,content)
#如果匹配成功,找到了J_HToken
if tokenMatch:
print u"验证码输入正确"
self.J_HToken = tokenMatch.group(1)
return tokenMatch.group(1)
else:
#匹配失败,J_Token获取失败
print u"J_Token获取失败"
return False
except urllib2.HTTPError, e:
print u"连接服务器出错,错误原因",e.reason
return False
#通过token获得st
def getSTbyToken(self,token):
tokenURL = 'https://passport.alipay.com/mini_apply_st.js?site=0&token=%s&callback=stCallback6' % token
request = urllib2.Request(tokenURL)
response = urllib2.urlopen(request)
#处理st,获得用户淘宝主页的登录地址
pattern = re.compile('{"st":"(.*?)"}',re.S)
result = re.search(pattern,response.read())
#如果成功匹配
if result:
print u"成功获取st码"
#获取st的值
st = result.group(1)
return st
else:
print u"未匹配到st"
return False
#利用st码进行登录,获取重定向网址
def loginByST(self,st,username):
stURL = 'https://login.taobao.com/member/vst.htm?st=%s&TPL_username=%s' % (st,username)
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:35.0) Gecko/20100101 Firefox/35.0',
'Host':'login.taobao.com',
'Connection' : 'Keep-Alive'
}
request = urllib2.Request(stURL,headers = headers)
response = self.newOpener.open(request)
content = response.read().decode('gbk')
#检测结果,看是否登录成功
pattern = re.compile('top.location = "(.*?)"',re.S)
match = re.search(pattern,content)
if match:
print u"登录网址成功"
location = match.group(1)
return True
else:
print "登录失败"
return False
def getPage(self,pageIndex):
url = self.siteURL + "?page=" + str(pageIndex)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
return response.read().decode('gbk')
#获取索引界面所有MM的信息,list格式
def getContents(self,pageIndex):
page = self.getPage(pageIndex)
pattern = re.compile('<div class="list-item".*?pic-word.*?<a href="(.*?)".*?<img src="(.*?)".*?<a class="lady-name.*?>(.*?)</a>.*?<strong>(.*?)</strong>.*?<span>(.*?)</span>',re.S)
items = re.findall(pattern,page)
contents = []
for item in items:
contents.append([item[0],item[1],item[2],item[3],item[4]])
return contents
#获取MM个人详情页面
def getDetailPage(self,infoURL):
infoURL = 'http:' + infoURL
response = urllib2.urlopen(infoURL)
return response.read().decode('gbk')
#获取个人文字简介
def getBrief(self,page):
pattern = re.compile('<div class="mm-aixiu-content".*?>(.*?)<!--',re.S)
result = re.search(pattern,page)
return self.tool.replace(result.group(1))
#获取页面所有图片
def getAllImg(self,page):
pattern = re.compile('<div class="mm-aixiu-content".*?>(.*?)<!--',re.S)
#个人信息页面所有代码
content = re.search(pattern,page)
#从代码中提取图片
patternImg = re.compile('<img.*?src="(.*?)"',re.S)
images = re.findall(patternImg,content.group(1))
return images
#保存多张写真图片
def saveImgs(self,images,name):
number = 1
print u"发现",name,u"共有",len(images),u"张照片"
for imageURL in images:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = "jpg"
fileName = name + "/" + str(number) + "." + fTail
self.saveImg(imageURL,fileName)
number += 1
# 保存头像
def saveIcon(self,iconURL,name):
splitPath = iconURL.split('.')
fTail = splitPath.pop()
fileName = name + "/icon." + fTail
self.saveImg(iconURL,fileName)
#保存个人简介
def saveBrief(self,content,name):
fileName = name + "/" + name + ".txt"
f = open(fileName,"w+")
print u"正在偷偷保存她的个人信息为",fileName
f.write(content.encode('utf-8'))
#传入图片地址,文件名,保存单张图片
def saveImg(self,imageURL,fileName):
imageURL = 'http:' + imageURL
u = urllib.urlopen(imageURL)
data = u.read()
f = open(fileName, 'wb')
f.write(data)
print u"正在悄悄保存她的一张图片为",fileName
f.close()
#创建新目录
def mkdir(self,path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists=os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
print u"偷偷新建了名字叫做",path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print u"名为",path,'的文件夹已经创建成功'
return False
#将一页淘宝MM的信息保存起来
def savePageInfo(self,pageIndex):
#获取第一页淘宝MM列表
contents = self.getContents(pageIndex)
for item in contents:
#item[0]个人详情URL,item[1]头像URL,item[2]姓名,item[3]年龄,item[4]居住地
print u"发现一位模特,名字叫",item[2],u"芳龄",item[3],u",她在",item[4]
print u"正在偷偷地保存",item[2],"的信息"
print u"又意外地发现她的个人地址是",item[0]
#个人详情页面的URL
detailURL = item[0]
#得到个人详情页面代码
detailPage = self.getDetailPage(detailURL)
#获取个人简介
brief = self.getBrief(detailPage)
#获取所有图片列表
images = self.getAllImg(detailPage)
self.mkdir(item[2])
#保存个人简介
self.saveBrief(brief,item[2])
#保存头像
self.saveIcon(item[1],item[2])
#保存图片
self.saveImgs(images,item[2])
#传入起止页码,获取MM图片
def savePagesInfo(self,start,end):
for i in range(start,end+1):
print u"正在偷偷寻找第",i,u"个地方,看看MM们在不在"
self.savePageInfo(i)
#程序运行主干
def main(self):
#是否需要验证码,是则得到页面内容,不是则返回False
needResult = self.needCheckCode()
#请求获取失败,得到的结果是None
if not needResult ==None:
if not needResult == False:
print u"您需要手动输入验证码"
checkCode = self.getCheckCode(needResult)
#得到了验证码的链接
if not checkCode == False:
print u"验证码获取成功"
print u"请在浏览器中输入您看到的验证码"
webbrowser.open_new_tab(checkCode)
self.loginWithCheckCode()
#验证码链接为空,无效验证码
else:
print u"验证码获取失败,请重试"
else:
print u"不需要输入验证码"
else:
print u"请求登录页面失败,无法确认是否需要验证码"
#判断token是否正常获取到
if not self.J_HToken:
print "获取Token失败,请重试"
return
#获取st码
st = self.getSTbyToken(self.J_HToken)
#利用st进行登录
result = self.loginByST(st,self.username)
if result:
#获得所有宝贝的页面
page = self.savePageInfo(1)
else:
print u"登录失败"
taobao = Taobao()
taobao.main()
结果如下:

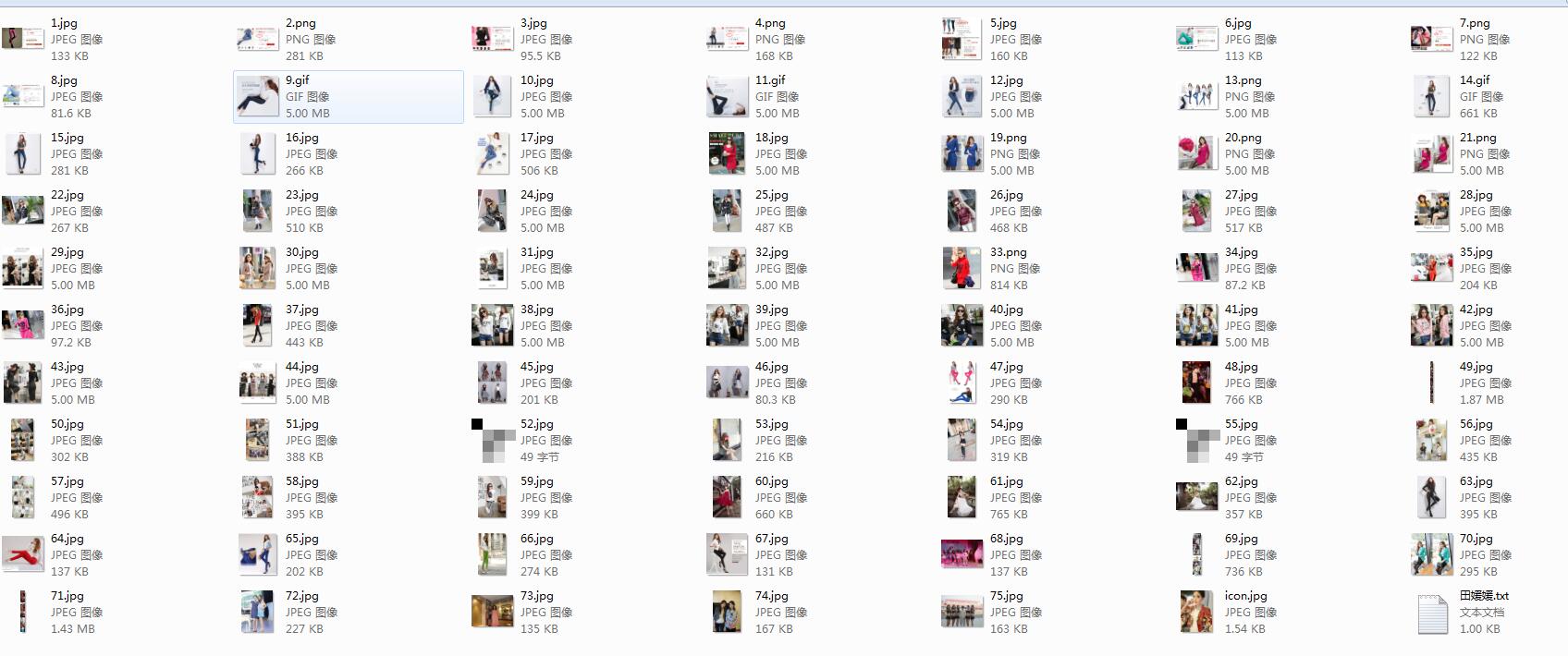
学习参考:http://cuiqingcai.com/1001.html (加入了模拟登录)














 7209
7209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









