






(一)需求分析
网络安全编程作业:编写一个和网络与安全有关的小程序。
本实验使用Java编程,利用Java的爬虫技术获取爬去昵图网上的图片,并按目录储存下来。
(二)设计原理
1.昵图网网页介绍:
昵图网成立于2007年1月1日,是一个设计素材、图片素材共享平台。在平时学习工作中有很多使用到图片的情况,昵图网无疑是一个十分宝贵的资源。本实验使用Java爬虫对昵图网的摄影目录下的所有图片进行爬取,将爬取结果存储到电脑中。
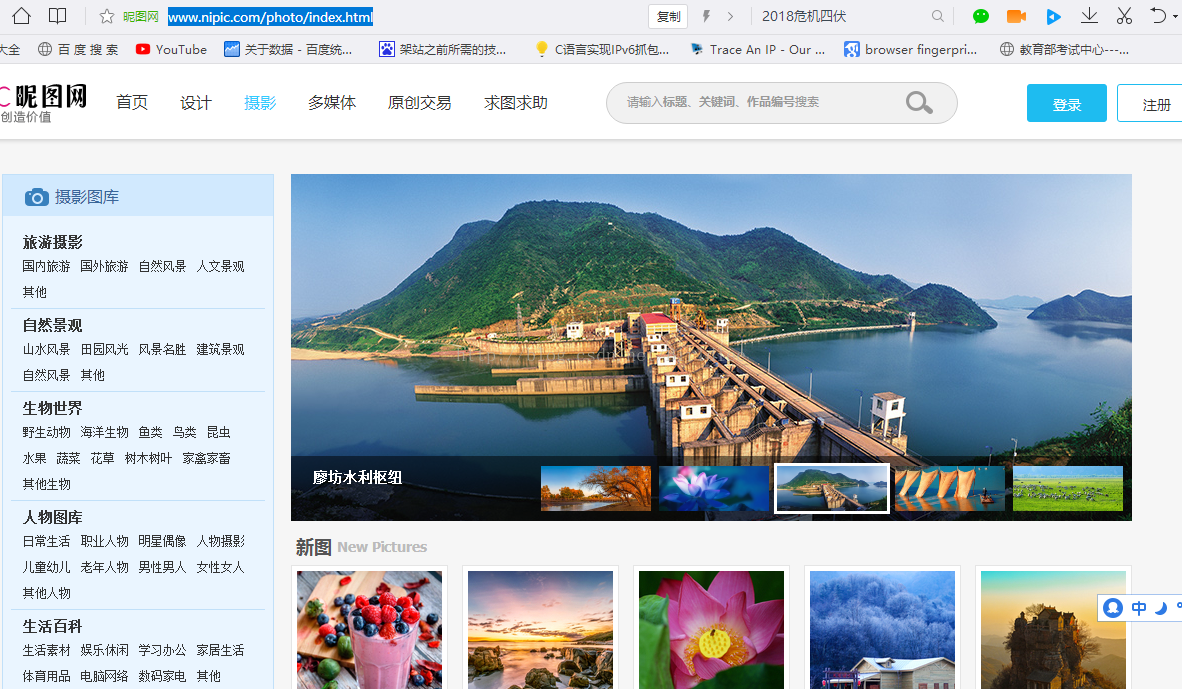
昵图网的首页为http://www.nipic.com/,其中昵图网摄影首页http://www.nipic.com/photo/index.html
。我们通过详细分析摄影板块中的信息,发现昵图网的摄影图片分为是个板块,分别是
旅游摄影,自然景观、生物世界、人文图库、生活百科、现代科技、文华艺术、建筑园林、商务金融、餐饮美食。点击进入这些目录中发现,子目录都遵循着这样的格式:http://www.nipic.com/photo/lvyou/index.html、http://www.nipic.com/photo/jingguan/index.html
所有我们可以建立一个数组分别存储photo下的子目录的称号,这些类别对应的url子目录名分别是"lvyou","jingguan", "shengwu", "renwu","baike", "xiandai","wenyi", "jianzhu","jinrong", "canyin"
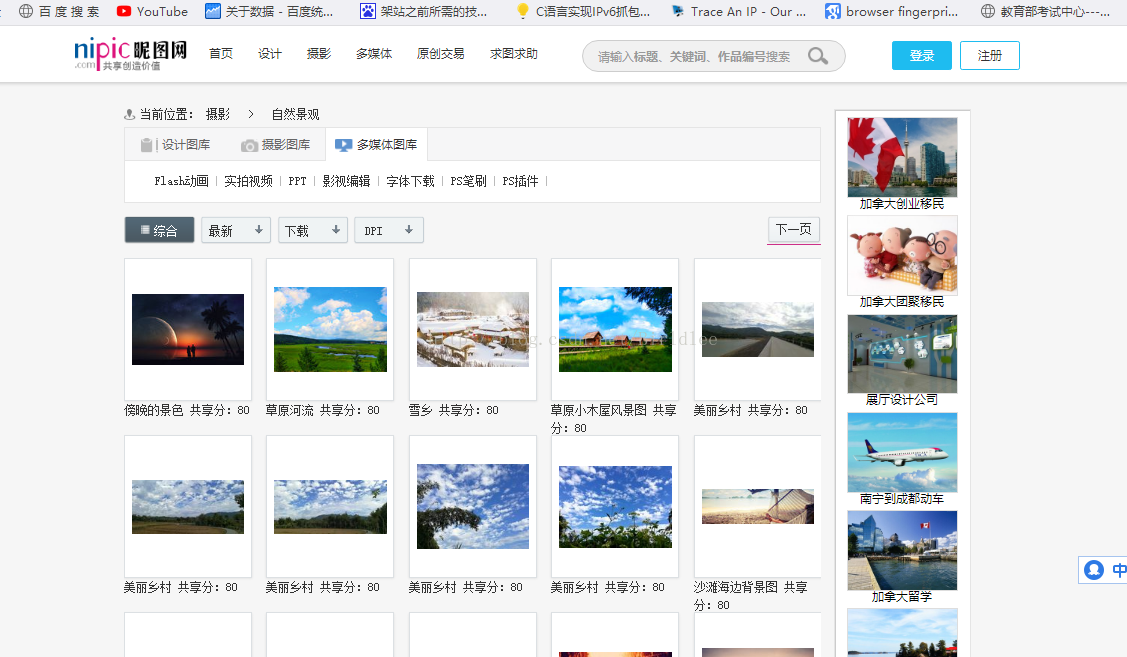
当点进每一张图片的详细信息时,发现此时的URL格式和原来的并不一样,是诸如http://www.nipic.com/show/18816390.html、http://www.nipic.com/show/18816376.html等类型的URL地址
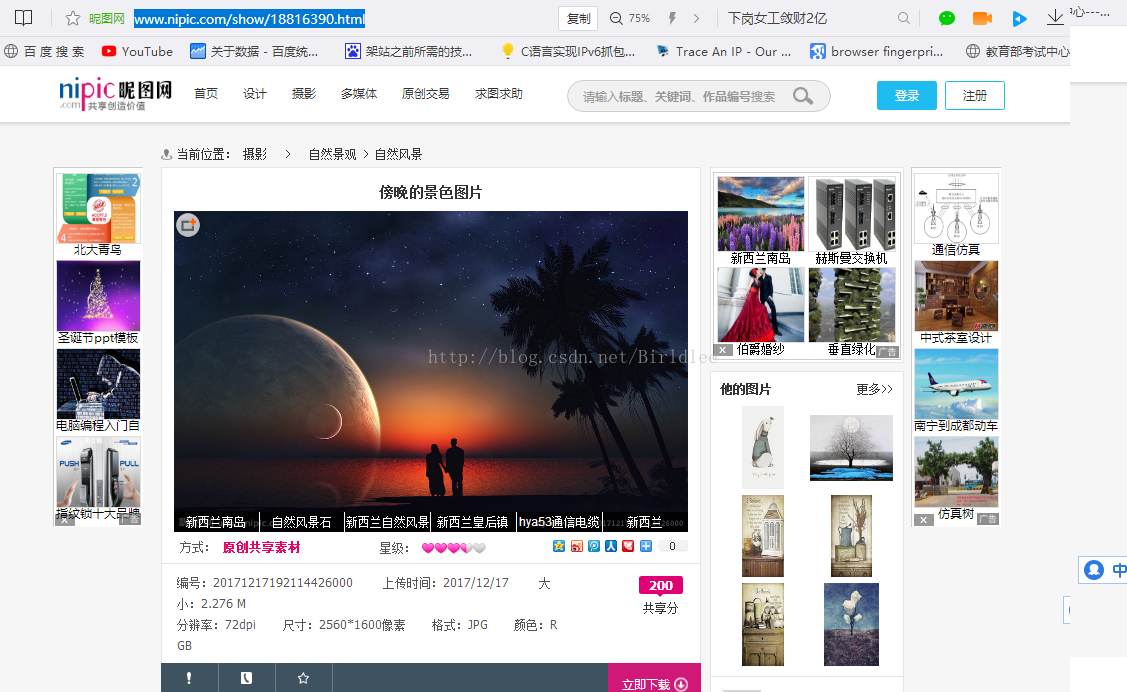
当点击图片分析图片地址时,发现图片的下载地址也和原先的格式不一样,点击复制图片连接,图片的连链接为

图片的下载链接为http://pic149.nipic.com/file/20171217/7672_192114426000_2.jpg,通过分析发现昵图网的图片下载链接都是诸如此类的形式。通过以上对昵图网首页、目录网页、单张图片网页和最后下载链接的地址的分析,得到了昵图网的具体结构,所以便可以开始进行爬虫的编写。
2.Java爬虫介绍
爬虫技术的实现,除了 Python 外, Java 也是一门能支持爬虫技术的语言, Java 提供了许多的爬虫库并且其优点是能比较简单地实现多线程,效率很高。在本次代码的设计中,使用到了 Java 的各种库,实现爬虫功能。
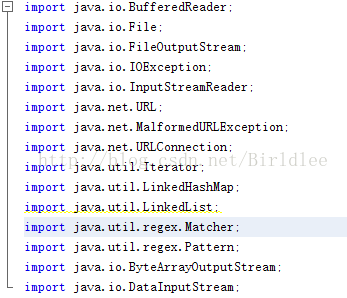
通过使用Java的url库对网页的html源代码进行获取,并使用Java的正则表达式筛选需要的网页链接,然后使用网页下载流对图片进行下载。程序的源代码如下:
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.MalformedURLException;
import java.net.URLConnection;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.LinkedList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
public class NipicCrawl
{
public staticvoid main( String[] args ) throws InterruptedException
{
Filedir = new File( "d:\\pictures\\" );
dir.mkdir();
intpages=10;
Stringmain_web = "http://www.nipic.com/photo/";
String[]indexname = {"lvyou", "jingguan", "shengwu","renwu", "baike", "xiandai",
"wenyi","jianzhu", "jinrong", "canyin"};
intno;
String index_web_regex ="http://www\\.nipic\\.com/show/+\\d*.html";
Stringtitle_regex ="alt=\"[\\u4e00-\\u9fa5]*.*\"/></span></a>";
Stringpicture_regex = "http://pic149.nipic.com/file/+\\d*/+\\w*.jpg";
for(int i = 0; i < indexname.length; i++ )
{
Stringindex = indexname[i];
Stringurl = main_web + index + "/";
no= 10 + i;
Filedir_file = new File( dir, index );
dir_file.mkdir();//创建新文件夹
intpage = pages;
for(int j = 1; j <= page; j++ ) //新文件夹下pages页,每页20张的图片下载开始
{
Tasktask = new Task( dir_file, url, no, index_web_regex, title_regex,
picture_regex,j, page );
newThread( task ).start();
if(j % 10 == 0 )
Thread.sleep(20000 );
}
}
}
}
class Task implements Runnable
{
File dir;
Stringindex_web_url;
intno,begin,end;
Stringindex_web_regex;
Stringtitle_regex;
Stringpicture_regex;
publicTask(File dir,String index_web_url,int no,String index_web_regex,String title_regex,Stringpicture_regex,int end)
{
this(dir,index_web_url,no,index_web_regex,title_regex,picture_regex,1,end);
}
publicTask(File dir,String index_web_url,int no,String index_web_regex,Stringtitle_regex,String picture_regex,int begin,int end)
{
this.dir=dir;
this.no=no;
this.begin=begin;
this.end=end;
this.picture_regex=picture_regex; //"http://pic149.nipic.com/file/+\\d*/+\\w*.jpg";
this.title_regex=title_regex; //"alt=\"[\\u4e00-\\u9fa5]*.*\"/></span></a>";
this.index_web_url=index_web_url; //main_web + index + "/";
this.index_web_regex=index_web_regex; //"http://www\\.nipic\\.com/show/+\\d*.html";
}
@Override
public void run()
{
WebsitListwebsitList=newWebsitList(index_web_url,no,begin,end,index_web_regex,title_regex);
try
{
websitList.initUrls();
}catch(IOException e1)
{
System.out.println(index_web_url+"已跳过");
}
Iterator<String>iterator=websitList.index_web_show_urls.keySet().iterator();
int i=0;
while(iterator.hasNext())
{
try
{
String url_key=iterator.next();
Stringtitle=websitList.index_web_show_urls.get(url_key);
//System.out.println(url_key+":"+title);
DetailPage detailPage=new DetailPage(url_key,title,picture_regex);
detailPage.initPages();
detailPage.downloadAll(dir,i);
i++;
}catch(Exception e)
{
continue;
}
if(i%6==0)
{
System.out.println("休息十秒");
for(int j=0;j<10;j++)
{
try
{
Thread.sleep(1000);
}
catch(InterruptedException e)
{
e.printStackTrace();
}
}
System.out.println();
}
}
}
}
/**
* @classnameWebsitList
* @authorLiHongpeng
*/
class WebsitList
{
private Patterntitle_pattern;
private Stringindex_web_url;
int begin,end;
int num;
Patternpattern_index_show;
LinkedHashMap<String,String> index_web_show_urls=newLinkedHashMap<String,String>();
publicWebsitList(String index_web_url,int num,int begin,int end,Stringindex_web_regex,String title_regex)
{
this.begin=begin;
this.end=end;
this.num=num;
this.index_web_url=index_web_url; //main_web + index + "/";
this.pattern_index_show=Pattern.compile(index_web_regex); //"http://www\\.nipic\\.com/show/+\\d*.html";
this.title_pattern=Pattern.compile(title_regex); //"alt=\"[\\u4e00-\\u9fa5]*.*\"/></span></a>";
}
public voidinitUrls() throws IOException
{
URLurl=null;
for(int i=begin;i<=end;i++)
{
try
{
if(i!=1)
url=new URL(index_web_url+"index.html?page="+i);
else
{
url=new URL(index_web_url+"index.html");
}
URLConnectionconnection=url.openConnection();
connection.connect();
BufferedReader in = new BufferedReader(newInputStreamReader(connection.getInputStream()));
String line;
while((line=in.readLine())!=null)
{
//result+=line;
matchAll(line);
}
}catch(IOException e)
{
System.out.println("已跳过"+url);
}
}
}
private voidmatchAll(String line)
{
Stringtitle,web_show_url;
Matchermatcher_for_show=pattern_index_show.matcher(line);
Matchertitle_matcher=title_pattern.matcher(line);
while(matcher_for_show.find())
{
if(title_matcher.find())
{
web_show_url=matcher_for_show.group();
title=title_matcher.group();
index_web_show_urls.put(web_show_url, title);
System.out.println("添加成功"+title+web_show_url);
}
}
}
public intgetTotal()
{
return end;
}
public voidsetTotal(int total)
{
this.end=total;
}
}
class DetailPage
{
private Patternpic_pattern;
String title;
private intpages=1;
String srcs;
// LinkedList<String> srcs=new LinkedList<String>();
Stringshow_url;
publicDetailPage(String show_url,String title,String picture_regex) throwsIOException
{
this.title=title;
this.show_url=show_url;
this.pic_pattern=Pattern.compile(picture_regex);
}
public voidinitPages() throws IOException
{
try
{
URLurl=new URL(show_url);
URLConnection connection=url.openConnection();
connection.connect();
BufferedReader in =new BufferedReader(newInputStreamReader(connection.getInputStream()));
Stringline;
Stringresult="";
while((line=in.readLine())!=null)
{
result+=line;
}
matchSrcs(result);
}catch(Exception e)
{
System.out.println("已跳过");
}
}
private voidmatchSrcs(String line)
{
Stringpic_url;
Matcherpic_url_matcher=pic_pattern.matcher(line);
if(pic_url_matcher.find())
{
pic_url=pic_url_matcher.group();
srcs=pic_url;
System.out.println("获取图片网址"+pic_url);
}
}
public voiddownloadAll(File dir,int name) throws IOException
{
if(title==null)
return;
URL url=newURL(srcs);
Stringpath=dir.getAbsolutePath()+"\\"+name+".jpg";
System.out.println("下载路径与图片名"+dir.getAbsolutePath()+"\\"+name+".jpg");
try
{
DataInputStream dataInputStream=new DataInputStream(url.openStream());
FileOutputStream fileOutputStream=new FileOutputStream(new File(path));
ByteArrayOutputStream output=new ByteArrayOutputStream();
System.out.println(srcs+"开始下载");
byte[]buf=new byte[1024];
int len;
while((len=dataInputStream.read(buf))>0)
{
output.write(buf,0,len);
}
fileOutputStream.write(output.toByteArray());
dataInputStream.close();
fileOutputStream.close();
System.out.println(srcs+"下载完成");
name++;
}catch(MalformedURLException e)
{
System.out.println( "连接失败,跳过当前文件");
}catch(IOException e)
{
System.out.println( "连接失败,跳过当前文件");
}
}
}(三)设计详细
本程序一共有四个大类,分别为NipicCrawl:整个程序的主程序和入口,实现主线程的创建和核心操作。Task:支持线程的创建,对每一个类别目录创建任务进行下载。WebsitList:收集子目录网页的网址信息和标题信息,把它们储存到一个LinkedHashMap类型的哈希链接列表中。DetailPage:LinkedHashMap中每一项目录网页进行详细图片地址的提取,下载图片。
为了匹配到需要的URL地址,程序中设计了三个正则表达式,分别是
String index_web_regex ="http://www\\.nipic\\.com/show/+\\d*.html";
String title_regex="alt=\"[\\u4e00-\\u9fa5]*.*\"/></span></a>";
String picture_regex ="http://pic149.nipic.com/file/+\\d*/+\\w*.jpg";
分别用来匹配昵图网子目录下每张图片的详细信息网址、每张图片的标题和每张图片下载地址。
如下的代码用来开启线程,对每个子目录下的网页进行获取、下载图片。并且每隔10页使用Sleep进行休息,以防线程过多造成混乱。
for( int i = 0; i < indexname.length; i++ )
{
String index = indexname[i];
String url = main_web + index + "/";
no = 10 + i;
File dir_file = new File( dir, index );
dir_file.mkdir();//创建新文件夹
int page = pages;
for( int j = 1; j <= page; j++ ) //新文件夹下pages页,每页20张的图片下载开始
{
Task task = new Task( dir_file, url, no, index_web_regex, title_regex,
picture_regex, j, page );
new Thread( task ).start();
if( j % 10 == 0 )
Thread.sleep( 20000 );
}
}
在run方法中创建了一个iterator的迭代数组来获得WebsitList中的网页和标题,并使用DetailPage创建详细网页信息,对网页中的图片进行下载。
WebsitList websitList=newWebsitList(index_web_url,no,begin,end,index_web_regex,title_regex);
try
{
websitList.initUrls();
}catch(IOException e1)
{
System.out.println(index_web_url+"已跳过");
}
Iterator<String>iterator=websitList.index_web_show_urls.keySet().iterator();
int i=0;
while(iterator.hasNext())
{
try
{
String url_key=iterator.next();
Stringtitle=websitList.index_web_show_urls.get(url_key);
//System.out.println(url_key+":"+title);
DetailPage detailPage=newDetailPage(url_key,title,picture_regex);
detailPage.initPages();
detailPage.downloadAll(dir,i);
i++;
} WebsitList websitList=newWebsitList(index_web_url,no,begin,end,index_web_regex,title_regex);
try
{
websitList.initUrls();
}catch(IOException e1)
{
System.out.println(index_web_url+"已跳过");
}
Iterator<String>iterator=websitList.index_web_show_urls.keySet().iterator();
int i=0;
while(iterator.hasNext())
{
try
{
String url_key=iterator.next();
Stringtitle=websitList.index_web_show_urls.get(url_key);
//System.out.println(url_key+":"+title);
DetailPage detailPage=newDetailPage(url_key,title,picture_regex);
detailPage.initPages();
detailPage.downloadAll(dir,i);
i++;
}而在WebsitList中,存在着名为index_web_show_urls的LinkedHashMap,用来存放网页信息和标题,用来提供给run方法的下载。
class WebsitList
{
private Pattern title_pattern;
private String index_web_url;
int begin,end;
int num;
Pattern pattern_index_show;
LinkedHashMap<String,String>index_web_show_urls=new LinkedHashMap<String,String>();Run方法中使用DetailPage中的downLoadAl方法对图片进行下载。并把图片存储到相应的文件夹下。
public void downloadAll(Filedir,int name) throws IOException
{
if(title==null)
return;
URL url=new URL(srcs);
Stringpath=dir.getAbsolutePath()+"\\"+name+".jpg";
System.out.println("下载路径与图片名"+dir.getAbsolutePath()+"\\"+name+".jpg");
try
{
DataInputStream dataInputStream=newDataInputStream(url.openStream());
FileOutputStream fileOutputStream=newFileOutputStream(new File(path));
ByteArrayOutputStream output=newByteArrayOutputStream();
System.out.println(srcs+"开始下载");
byte[] buf=new byte[1024];
int len;
while((len=dataInputStream.read(buf))>0)
{
output.write(buf,0,len);
}
fileOutputStream.write(output.toByteArray());
dataInputStream.close();
fileOutputStream.close();
System.out.println(srcs+"下载完成");
name++;
}catch (MalformedURLException e)
{
System.out.println( "连接失败,跳过当前文件");
}catch (IOException e)
{
System.out.println( "连接失败,跳过当前文件");
}
}
}(四)项目测试情况
在配置好Java环境中的系统打开Windows的CMD,使用javac对文件进行编译。
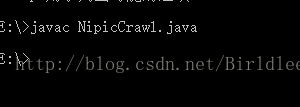
使用java NipicCrawl指令运行代码。
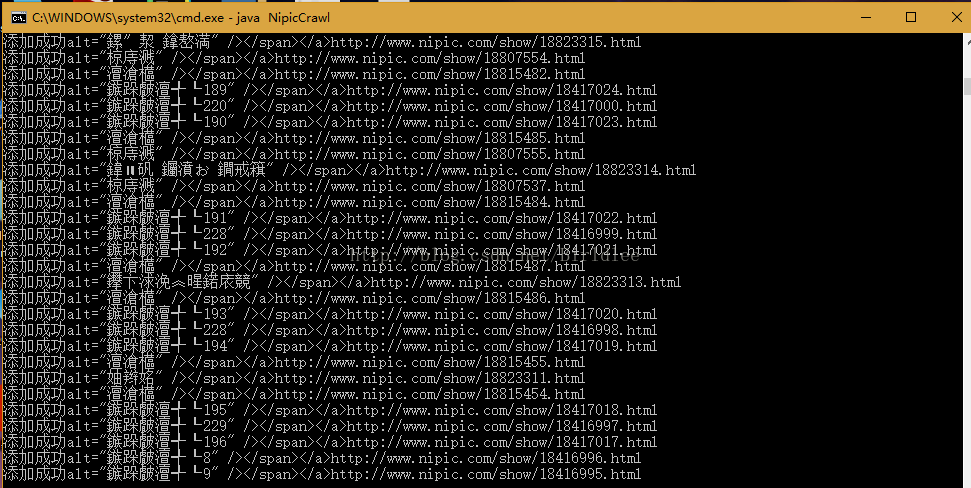
显示标题和对应网址一斤添加成功,由于网页中使用的是UTF-8编码,与WindowsCMD编码不一致所以标题显示出来的是乱码,这不影响图片的下载。打开D盘的picture文件夹,可以看到爬虫爬取到的图片
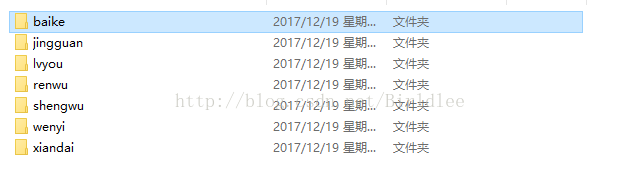
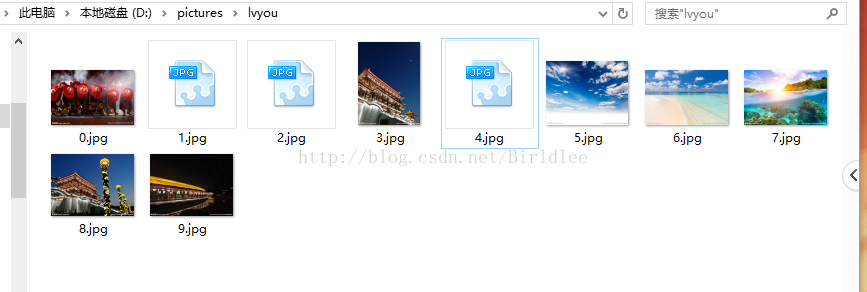
五、总结
网络爬虫是一项十分实用的网络编程技术,能够以程序化、快速化的方式批量获取互联网上的各种信息,如今网络爬虫已运用与图片获取、视频获取、大数据分析、搜索引擎等各个领域,具有十分广泛的应用场景。现在主流的爬虫语言是Python,但同时Java借助它强大的API和封装库,也能很好地支持爬虫功能,通过本次作业,我进一步地巩固了Java的语法和编程、并深入学习了Java在Web中的应用,学习了网络爬虫的各种有关知识,例如正则表达式、URL类的使用等等,同时也学会了如何对目标网站网址内容进行分析以编写合适的正则表达式来截取需要的URL。在作业的过程中遇到了很多困难,从一开始对正则表达式的不知半解到通过不断学习、查看博客和文章,慢慢掌握了正则表达式的使用规则;从对Java Web功能的不熟悉到慢慢了解Java URL的使用以及更多Java高级语法和编程的使用,通过这次作业收获了非常多的知识和宝贵的实践经验。
在实验的最后,文件的保存阶段,由于自己程序设计时对标题匹配和保存的程序设计不合理以及自己能力还不足,无法找出错误,在昵图网上爬取下来的图片的文件名中的中文部分是乱码。所以在这次作业之后,自己一定继续学习,解决现在的不足之处,更加完善现有的代码,并在以后不断继续网络安全编程的学习,带着这门课所学到的知识和经验不断前进。














 4806
4806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









