







本博文是转载自一篇博文,介绍GAN(Generative Adversarial Networks)即生成式对抗网络的原理以及GAN的优缺点的分析和GAN网络研究发展现状。下面是内容。
1. 生成式模型
1.1 概述
机器学习方法可以分为生成方法(generative approach)和判别方法(discriminative approach),所学到的模型分别称为生成式模型(generative model)和判别式模型(discriminative model)[1 李航]。生成方法通过观测数据学习样本与标签的联合概率分布P(X, Y),训练好的模型能够生成符合样本分布的新数据,它可以用于有监督学习和无监督学习。在有监督学习任务中,根据贝叶斯公式由联合概率分布P(X,Y)求出条件概率分布P(Y|X),从而得到预测的模型,典型的模型有朴素贝叶斯、混合高斯模型和隐马尔科夫模型等。无监督生成模型通过学习真实数据的本质特征,从而刻画出样本数据的分布特征,生成与训练样本相似的新数据。生成模型的参数远远小于训练数据的量,因此模型能够发现并有效内化数据的本质,从而可以生成这些数据。生成式模型在无监督深度学习方面占据主要位置,可以用于在没有目标类标签信息的情况下捕捉观测到或可见数据的高阶相关性。深度生成模型可以通过从网络中采样来有效生成样本,例如受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)、深度信念网络(Deep Belief Network, DBN)、深度玻尔兹曼机(Deep Boltzmann Machine, DBM)和广义除噪自编码器(Generalized Denoising Autoencoders)。近两年来流行的生成式模型主要分为三种方法[OpenAI 首批研究]:
- 生成对抗网络(GAN:Generative Adversarial Networks)
GAN启发自博弈论中的二人零和博弈,由[Goodfellow et al, NIPS 2014]开创性地提出,包含一个生成模型(generative model G)和一个判别模型(discriminative model D)。生成模型捕捉样本数据的分布,判别模型是一个二分类器,判别输入是真实数据还是生成的样本。这个模型的优化过程是一个“二元极小极大博弈(minimax two-player game)”问题,训练时固定一方,更新另一个模型的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布。 - 变分自编码器(VAE: Variational Autoencoders)
在概率图形模型(probabilistic graphical models )的框架中对这一问题进行形式化——在概率图形模型中,我们在数据的对数似然上最大化下限(lower bound)。 - 自回归模型(Autoregressive models)
PixelRNN 这样的自回归模型则通过给定的之前的像素(左侧或上部)对每个单个像素的条件分布建模来训练网络。这类似于将图像的像素插入 char-rnn 中,但该 RNN 在图像的水平和垂直方向上同时运行,而不只是字符的 1D 序列。
1.2 生成式模型的分类[重磅 | Yoshua Bengio深度学习暑期班]
全观察模型(Fully Observed Models)
模型在不引入任何新的非观察局部变量的情况下直接观察数据。这类模型能够直接编译观察点之间的关系。对于定向型图模型,很容易就能扩展成大模型,而且因为对数概率能被直接计算(不需要近似计算),参数学习也很容易。对于非定向型模型,参数学习就困难,因为我们需要计算归一化常数。全观察模型中的生成会很慢。下图展示了不同的全观察生成模型[图片来自Shakir Mohamed的展示]:
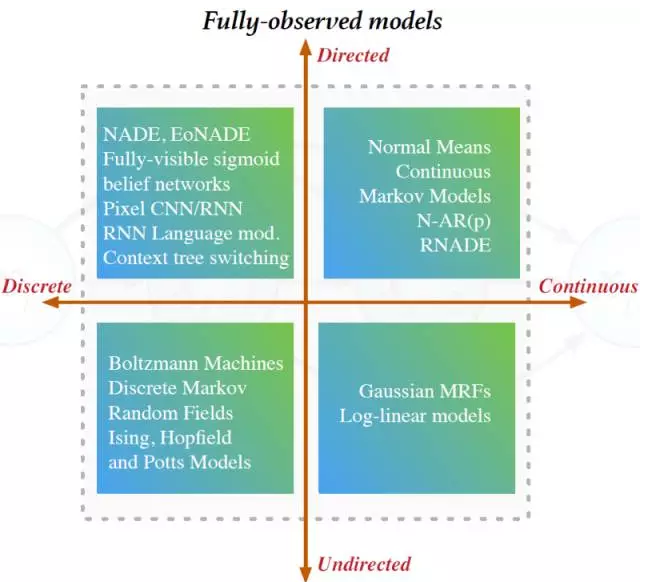
变换模型( Transformation Models)
模型使用一个参数化的函数对一个非观察噪音源进行变换。很容易做到(1):从这些模型中取样 (2):在不知道最终分布的情况下仅算期望值。它们可用于大型分类器和卷积神经元网络。然而,用这些模型维持可逆性并扩展到一般数据类型就很难了。下图显示了不同的变换生成模型[图片来自Shakir Mohamed的展示]:
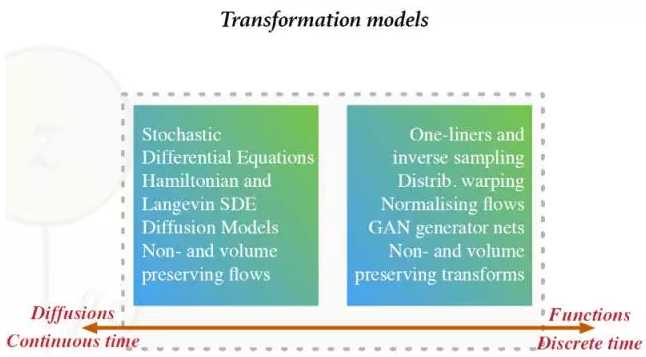
隐变量模型( Latent Variable Models)
这些模型中引入了一个代表隐藏因素的非观察局部随机变量。从这些模型中取样并加入层级和深度是很容易的。也可以使用边缘化概率进行打分和模型选择。然而,决定与一个输入相联系的隐变量却很难。下图显示了不同的隐变量生成模型[图片来自Shakir Mohamed的展示]:
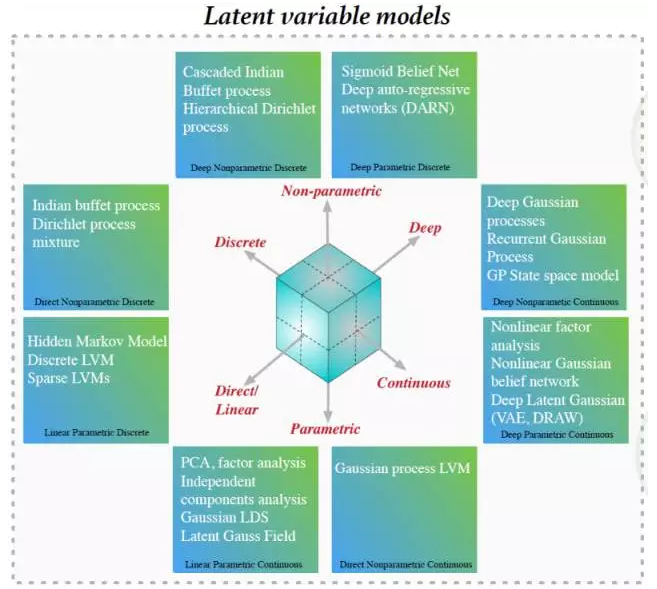
1.3 生成式模型的应用
我们需要生成(Generative models)模型,这样就能从关联输入移动到输出之外,进行半监督分类(semi-supervised classification)、数据操作(semi-supervised classification)、填空(filling in the blank)、图像修复(inpainting)、去噪(denoising)、one-shot生成 [Rezende et al, ICML 2016]、和其它更多的应用。下图展示了生成式模型的进展(注意到纵轴应该是负对数概率)[图片来自Shakir Mohamed的展示]:
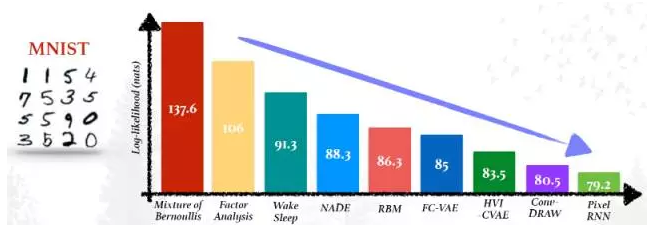
另据2016 ScaledML会议IIya Sutskever的演讲报告“生成模型的近期进展”介绍,生成模型主要有以下功能:
- Structured prediction,结构化预测(例如,输出文本);
- Much more robust prediction,更鲁棒的预测
- Anomaly detection,异常检测
- Model-based RL,基于模型的增强学习
生成模型未来推测可以加以应用的领域:
- Really good feature learning, 非常好的特征学习
- Exploration in RL, 在强化学习中的探索
- Inverse RL, 逆向增强学习
- Good dialog that actually works, 真正使用的对话
- “Understanding the world”, “理解世界”
- Transfer learning, 迁移学习
2. 生成式对抗网络
2.1 GAN的思想与训练方法
GAN[Goodfellow Ian,GAN]启发自博弈论中的二人零和博弈(two-player game),由[Goodfellow et al, NIPS 2014]开创性地提出。在二人零和博弈中,两位博弈方的利益之和为零或一个常数,即一方有所得,另一方必有所失。GAN模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。生成模型G捕捉样本数据的分布,判别模型是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率。G和D一般都是非线性映射函数,例如多层感知机、卷积神经网络等。如图2-1所示,左图是一个判别式模型,当输入训练数据x时,期待输出高概率(接近1);右图下半部分是生成模型,输入是一些服从某一简单分布(例如高斯分布)的随机噪声z,输出是与训练图像相同尺寸的生成图像。向判别模型D输入生成样本,对于D来说期望输出低概率(判断为生成样本),对于生成模型G来说要尽量欺骗D,使判别模型输出高概率(误判为真实样本),从而形成竞争与对抗。
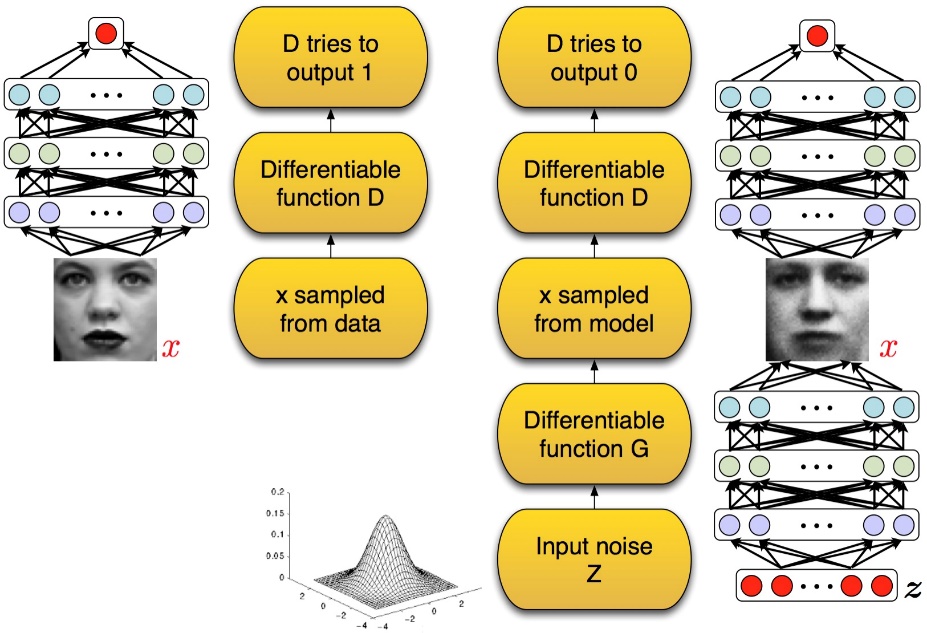
GAN模型没有损失函数,优化过程是一个“二元极小极大博弈(minimax two-player game)”问题:
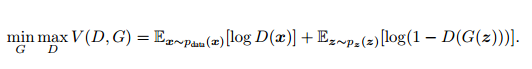
这是关于判别网络D和生成网络G的价值函数(Value Function),训练网络D使得最大概率地分对训练样本的标签(最大化log D(x)),训练网络G最小化log(1 – D(G(z))),即最大化D的损失。训练过程中固定一方,更新另一个网络的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布。生成模型G隐式地定义了一个概率分布Pg,我们希望Pg 收敛到数据真实分布Pdata。论文证明了这个极小化极大博弈当且仅当Pg = Pdata时存在最优解,即达到纳什均衡,此时生成模型G恢复了训练数据的分布,判别模型D的准确率等于50%。

图2-2 生成式对抗网络算法流程
2.2 GAN的优势与缺陷
与其他生成式模型相比较,生成式对抗网络有以下四个优势【OpenAI Ian Goodfellow的Quora问答】:
- 根据实际的结果,它们看上去可以比其它模型产生了更好的样本(图像更锐利、清晰)。
- 生成对抗式网络框架能训练任何一种生成器网络(理论上-实践中,用 REINFORCE 来训练带有离散输出的生成网络非常困难)。大部分其他的框架需要该生成器网络有一些特定的函数形式,比如输出层是高斯的。重要的是所有其他的框架需要生成器网络遍布非零质量(non-zero mass)。生成对抗式网络能学习可以仅在与数据接近的细流形(thin manifold)上生成点。
- 不需要设计遵循任何种类的因式分解的模型,任何生成器网络和任何鉴别器都会有用。
- 无需利用马尔科夫链反复采样,无需在学习过程中进行推断(Inference),回避了近似计算棘手的概率的难题。
与PixelRNN相比,生成一个样本的运行时间更小。GAN 每次能产生一个样本,而 PixelRNN 需要一次产生一个像素来生成样本。
与VAE 相比,它没有变化的下限。如果鉴别器网络能完美适合,那么这个生成器网络会完美地恢复训练分布。换句话说,各种对抗式生成网络会渐进一致(asymptotically consistent),而 VAE 有一定偏置。
与深度玻尔兹曼机相比,既没有一个变化的下限,也没有棘手的分区函数。它的样本可以一次性生成,而不是通过反复应用马尔可夫链运算器(Markov chain operator)。
与 GSN 相比,它的样本可以一次生成,而不是通过反复应用马尔可夫链运算器。
与NICE 和 Real NVE 相比,在 latent code 的大小上没有限制。
GAN目前存在的主要问题:
- 解决不收敛(non-convergence)的问题。
目前面临的基本问题是:所有的理论都认为 GAN 应该在纳什均衡(Nash equilibrium)上有卓越的表现,但梯度下降只有在凸函数的情况下才能保证实现纳什均衡。当博弈双方都由神经网络表示时,在没有实际达到均衡的情况下,让它们永远保持对自己策略的调整是可能的【OpenAI Ian Goodfellow的Quora】。 - 难以训练:崩溃问题(collapse problem)
GAN模型被定义为极小极大问题,没有损失函数,在训练过程中很难区分是否正在取得进展。GAN的学习过程可能发生崩溃问题(collapse problem),生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。【Improved Techniques for Training GANs】 - 无需预先建模,模型过于自由不可控。
与其他生成式模型相比,GAN这种竞争的方式不再要求一个假设的数据分布,即不需要formulate p(x),而是使用一种分布直接进行采样sampling,从而真正达到理论上可以完全逼近真实数据,这也是GAN最大的优势。然而,这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的 pixel的情形,基于简单 GAN 的方式就不太可控了。在GAN[Goodfellow Ian, Pouget-Abadie J] 中,每次学习参数的更新过程,被设为D更新k回,G才更新1回,也是出于类似的考虑。
3. 条件生成式对抗网络,Conditional Generative Adversarial Networks
3.1 CGAN的思想
上面分析提出,与其他生成式模型相比,GAN这种竞争的方式不再要求一个假设的数据分布,即不需要formulate p(x),而是使用一种分布直接进行采样sampling,从而真正达到理论上可以完全逼近真实数据,这也是GAN最大的优势。然而,这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的 pixel的情形,基于简单 GAN 的方式就不太可控了。为了解决GAN太过自由这个问题,一个很自然的想法是给GAN加一些约束,于是便有了Conditional Generative Adversarial Nets(CGAN)【Mirza M, Osindero S. Conditional】。这项工作提出了一种带条件约束的GAN,在生成模型(D)和判别模型(G)的建模中均引入条件变量y(conditional variable y),使用额外信息y对模型增加条件,可以指导数据生成过程。这些条件变量y可以基于多种信息,例如类别标签,用于图像修复的部分数据[2],来自不同模态(modality)的数据。如果条件变量y是类别标签,可以看做CGAN 是把纯无监督的 GAN 变成有监督的模型的一种改进。这个简单直接的改进被证明非常有效,并广泛用于后续的相关工作中[3,4]。Mehdi Mirza et al. 的工作是在MNIST数据集上以类别标签为条件变量,生成指定类别的图像。作者还探索了CGAN在用于图像自动标注的多模态学习上的应用,在MIR Flickr25000数据集上,以图像特征为条件变量,生成该图像的tag的词向量。
3.2 Conditional Generative Adversarial Nets
3.2.1 Generative Adversarial Nets
Generative Adversarial Nets是由Goodfellow[5]提出的一种训练生成式模型的新方法,包含了两个“对抗”的模型:生成模型(G)用于捕捉数据分布,判别模型(D)用于估计一个样本来自与真实数据而非生成样本的概率。为了学习在真实数据集x上的生成分布Pg,生成模型G构建一个从先验分布 Pz (z)到数据空间的映射函数 G(z; θg )。 判别模型D的输入是真实图像或者生成图像,D(x; θd )输出一个标量,表示输入样本来自训练样本(而非生成样本)的概率。
模型G和D同时训练:固定判别模型D,调整G的参数使得 log(1 − D(G(z))的期望最小化;固定生成模型G,调整D的参数使得logD(X) + log(1 − D(G(z)))的期望最大化。这个优化过程可以归结为一个“二元极小极大博弈(minimax two-player game)”问题:
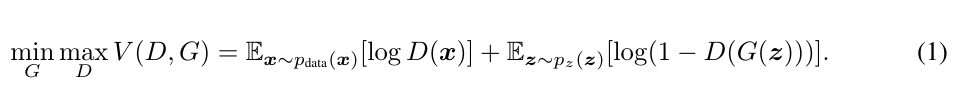
3.2.2 Conditional Adversarial Nets
条件生成式对抗网络(CGAN)是对原始GAN的一个扩展,生成器和判别器都增加额外信息y为条件, y可以使任意信息,例如类别信息,或者其他模态的数据。如Figure 1所示,通过将额外信息y输送给判别模型和生成模型,作为输入层的一部分,从而实现条件GAN。在生成模型中,先验输入噪声p(z)和条件信息y联合组成了联合隐层表征。对抗训练框架在隐层表征的组成方式方面相当地灵活。类似地,条件GAN的目标函数是带有条件概率的二人极小极大值博弈(two-player minimax game ):
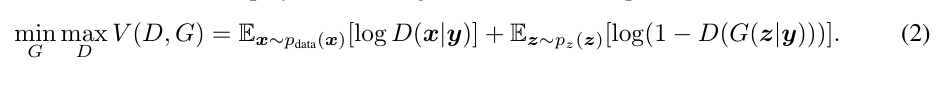
CGAN的网络结构
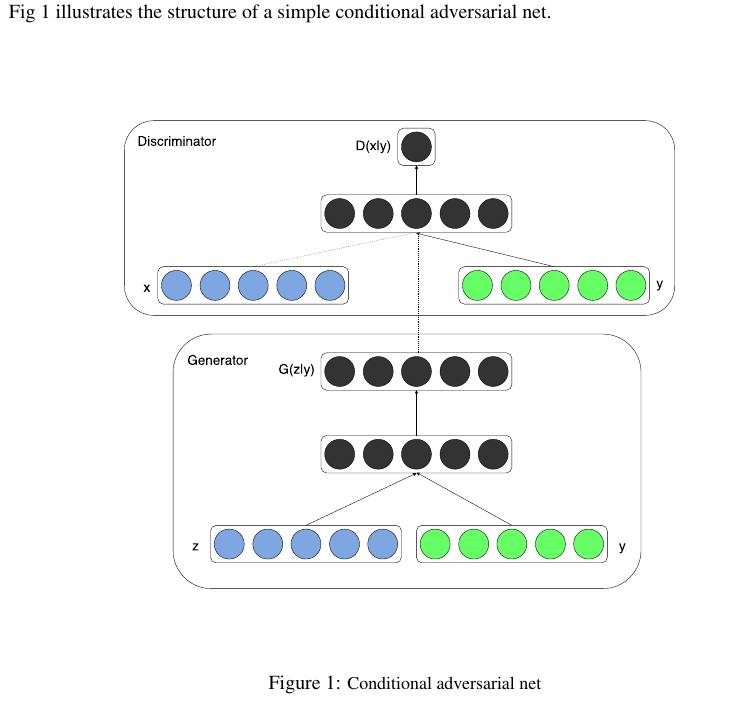
3.3 实验
3.3.1 MNIST数据集实验
在MNIST上以类别标签为条件(one-hot编码)训练条件GAN,可以根据标签条件信息,生成对应的数字。生成模型的输入是100维服从均匀分布的噪声向量,条件变量y是类别标签的one hot编码。噪声z和标签y分别映射到隐层(200和1000个单元),在映射到第二层前,联合所有单元。最终有一个sigmoid生成模型的输出(784维),即28*28的单通道图像。
判别模型的输入是784维的图像数据和条件变量y(类别标签的one hot编码),输出是该样本来自训练集的概率。

3.3.2 多模态学习用于图像自动标注
自动标注图像:automated tagging of images,使用多标签预测。使用条件GAN生成tag-vector在图像特征条件上的分布。数据集: MIR Flickr 25,000 dataset ,语言模型:训练一个skip-gram模型,带有一个200维的词向量。
【生成模型输入/输出】
噪声数据 100维=>500维度
图像特征4096维=>2000维
这些单元全都联合地映射到200维的线性层,
输出生成的词向量 (200维的词向量)
【判别模型的输入/输出】
输入:
500维词向量;
1200维的图像特征
???生成式和判别式的条件输入y,维度不一样???一个是4096维的图像特征,另一个是?维的?向量 _???
如图2所示,第一列是原始像,第二列是用户标注的tags ,第三列是生成模型G生成的tags。
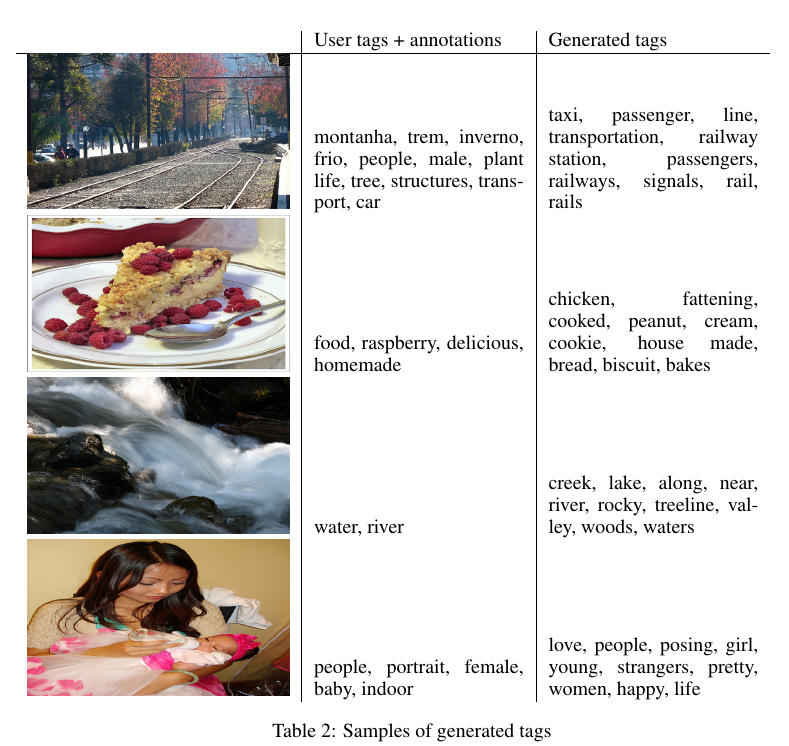
3.4 Future works
1. 提出更复杂的方法,探索CGAN的细节和详细地分析它们的性能和特性。
2. 当前生成的每个tag是相互独立的,没有体现更丰富的信息。
3. 另一个遗留下的方向是构建一个联合训练的调度方法去学校language model














 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









