





#POS请求:直接向服务器发送数据
#get请求:从服务器获取数据
#有道,向服务器发送数据,再获取数据
分析:
(1)这里要注意的是三个函数urllib.request.Request(),urllib.request.urlopen()与urllib.parse.urlencode()。
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)这个类是一个抽象的URL请求。
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)。因此urllib.request.urlopen()其实不止一个参数,有好几个哦,其中第二个是data,data应该是一个buffer的标准应用程序/ x-www-form-urlencoded格式(python标准库原文:data should be a buffer in the standard application/x-www-form-urlencoded format)。
urllib.parse.urlencode()函数接受一个映射或序列集合,并返回一个字符串的格式(python标准库原文:The urllib.parse.urlencode() function takes a mapping or sequence of 2-tuples and returns a string in this format)。
(2)分析URL,此时分析有道翻译页面真实的Request URL
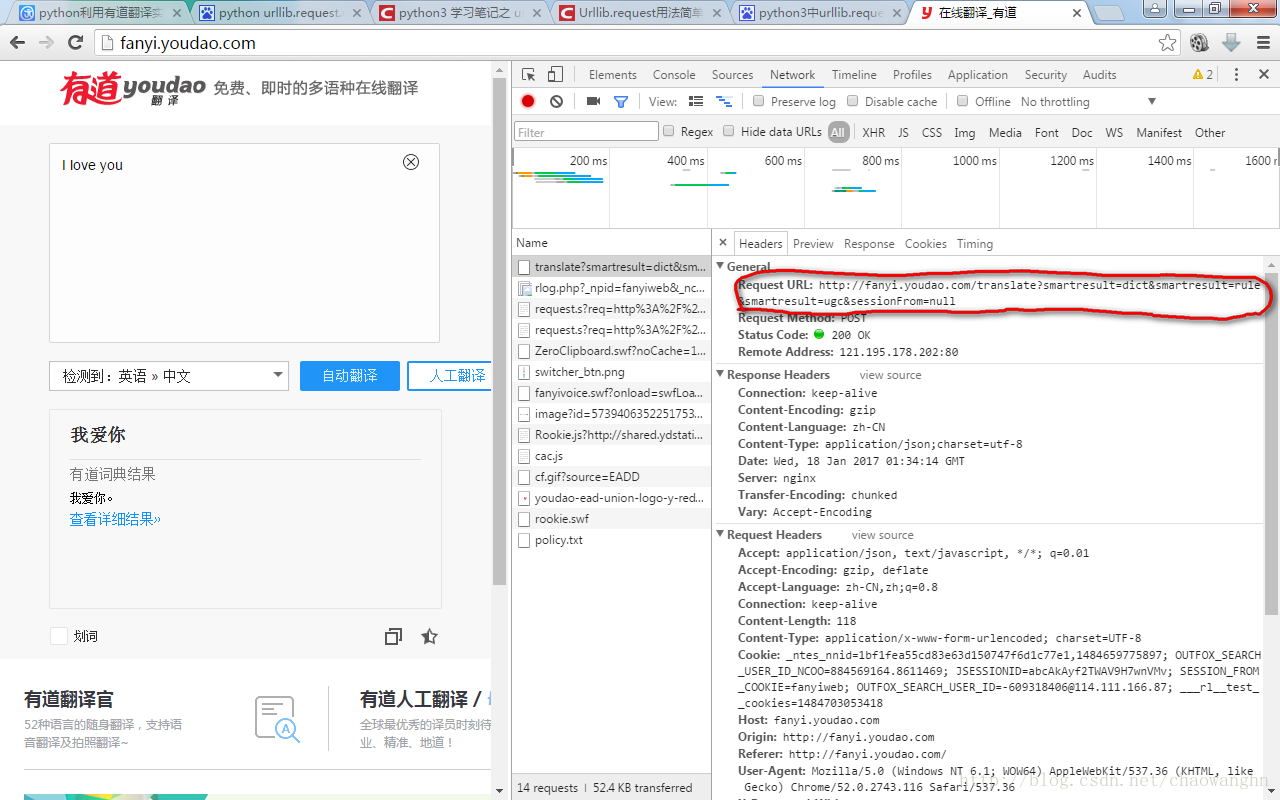
Request URL:
http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null
(3)Data为字典
type:AUTO
i:I love you
doctype:json
xmlVersion:1.8
keyfrom:fanyi.web
ue:UTF-8
action:FY_BY_CLICKBUTTON
typoResult:true
关于这个data的问题,也是出现了问题,比如创建字典的两种方法,第一种还没有发现错误,暂时还是按照dic[key]=value的做法来吧,还有就是,在输入data的内容时和网上的教程不一样,但没有关系,按照你用的那个浏览器的表单数据输入就ok,什么都不用改。
(4)headers 应该是一个字典,如果 add_header()被称为与每个键和值作为参数。这通常是用来“恶搞” User-Agent头的值,因为使用一个浏览器识别本身——一些常见HTTP服务器只允许请求来自浏览器而不是脚本。例如,Mozilla Firefox可能识别本身 “Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11”。而 urllib默认的用户代理字符串 是”Python-urllib/2.6”在Python 2.6()。
加入head有两种办法,一是head={},head[]='' 二是 add—header,作用只是,隐藏你的访问途径,是服务器认为是浏览器,访问,但如果访问数据的频率过快的话,仍然会被封IP的,因此,一下的time和代理的方法就有用了。
(5)存储为json格式,则使用json.load()方法
target=json.loads(html)结果为:
{‘errorCode’: 0, ‘smartResult’: {‘entries’: [”, ‘我爱你。’], ‘type’: 1}, ‘elapsedTime’: 0, ‘translateResult’: [[{‘tgt’: ‘我爱你’, ‘src’: ‘I love you’}]], ‘type’: ‘EN2ZH_CN’}
我看到翻译的结果在这里:
‘translateResult’: [[{‘tgt’: ‘我爱你’, ‘src’: ‘I love you’}]]。包含在字典的Value里,外面有2层列表,里面还有一层字典。
添加代理(学习中)
但是,对于网站服务器,会发现同一个IP在短时间内有大量的登录,识别是爬虫。因为,即使现在我们修改了 User-Agent,也不起作用。此时的做法有两种:
1. 笨方法,修改访问时间
修改每次访问的时间,比如每5秒钟访问一次服务器,这样效率太低。
2)聪明方法:使用代理
步骤为:
1.参数是一个字典{“类型”:”代理ip:端口号”}
proxy_support=urllib.request.ProxyHandler({})
2.定制、创建一个opener
opener=urllib.request.build_opener(proxy_support)
3a.安装opener
urllib.request.install_opener(opener)
3b.调用opener
opener.open(url)














 1616
1616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









