







ELFhash函数在UNIX系统V 版本4中的“可执行链接格式”( Executable and Linking Format,即ELF )中会用到,ELF文件格式用于存储可执行文件与目标文件。ELFhash函数是对字符串的散列。它对于长字符串和短字符串都很有效,字符串中每个字符都有同样的作用,它巧妙地对字符的ASCII编码值进行计算,ELFhash函数对于能够比较均匀地把字符串分布在散列表中。这些函数使用位运算使得每一个字符都对最后的函数值产生影响
下面是腾讯的一个面试题:
// ELF Hash Function
unsigned int ELFHash(char *str)
{
unsigned int hash = 0;
unsigned int x = 0;
while (*str)
{
hash = (hash << 4) + (*str++);//hash左移4位,当前字符ASCII存入hash低四位。
if ((x = hash & 0xF0000000L) != 0)
{//如果最高的四位不为0,则说明字符多余7个,如果不处理,再加第九个字符时,第一个字符会被移出,因此要有如下处理。
//该处理,如果对于字符串(a-z 或者A-Z)就会仅仅影响5-8位,否则会影响5-31位,因为C语言使用的算数移位
hash ^= (x >> 24);
//清空28-31位。
hash &= ~x;
}
}
//返回一个符号位为0的数,即丢弃最高位,以免函数外产生影响。(我们可以考虑,如果只有字符,符号位不可能为负)
return (hash & 0×7FFFFFFF);
}
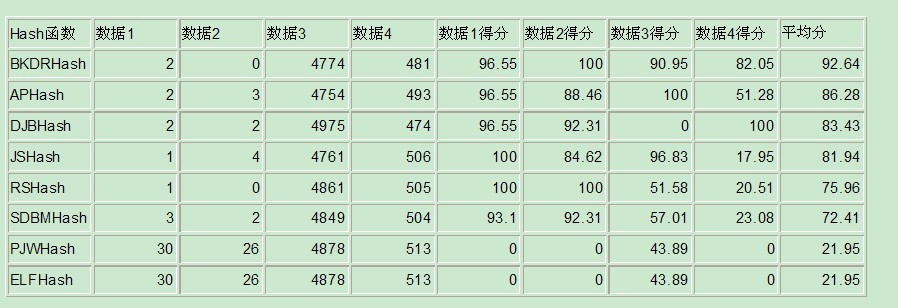
常用的字符串Hash函数还有ELFHash,APHash等等,都是十分简单有效的方法。这些函数使用
位运算使得每一个字符都对最后的函数值产生影响。另外还有以MD5和SHA1为代表的杂凑函数,
这些函数几乎不可能找到碰撞。
常用字符串哈希函数有BKDRHash,APHash,DJBHash,JSHash,RSHash,SDBMHash,
PJWHash,ELFHash等等。
BKDRHash无论是在实际效果还是编码实现中,效果都是最突出的。APHash也是较为优秀的算法。DJBHash,JSHash,RSHash与SDBMHash各有千秋。PJWHash与ELFHash效果最差,但得分相似,其算法本质是相似的。
各种哈希函数的C语言程序代码
//简单哈希,平方取中
for( i = 0; i < s; i++ )
{
hash = arr[i];
hash *= hash;
hash /= 256;
hash %= 65535;
hashTable[hash] = arr[i];
}
//SDBMHash
unsigned int SDBMHash(char *str)
{
unsigned int hash = 0;
while (*str)
{
// equivalent to: hash = 65599*hash + (*str++);
hash = (*str++) + (hash << 6) + (hash << 16) - hash;
}
return (hash & 0x7FFFFFFF);
}
// RS Hash
unsigned int RSHash(char *str)
{
unsigned int b = 378551;
unsigned int a = 63689;
unsigned int hash = 0;
while (*str)
{
hash = hash * a + (*str++);
a *= b;
}
return (hash & 0x7FFFFFFF);
}
// JS Hash
unsigned int JSHash(char *str)
{
unsigned int hash = 1315423911;
while (*str)
{
hash ^= ((hash << 5) + (*str++) + (hash >> 2));
}
return (hash & 0x7FFFFFFF);
}
// P. J. Weinberger Hash
unsigned int PJWHash(char *str)
{
unsigned int BitsInUnignedInt = (unsigned int)(sizeof(unsigned int) * 8);
unsigned int ThreeQuarters = (unsigned int)((BitsInUnignedInt * 3) / 4);
unsigned int OneEighth = (unsigned int)(BitsInUnignedInt / 8);
unsigned int HighBits = (unsigned int)(0xFFFFFFFF) << (BitsInUnignedInt
- OneEighth);
unsigned int hash = 0;
unsigned int test = 0;
while (*str)
{
hash = (hash << OneEighth) + (*str++);
if ((test = hash & HighBits) != 0)
{
hash = ((hash ^ (test >> ThreeQuarters)) & (~HighBits));
}
}
return (hash & 0x7FFFFFFF);
}
// ELF Hash
unsigned int ELFHash(char *str)
{
unsigned int hash = 0;
unsigned int x = 0;
while (*str)
{
hash = (hash << 4) + (*str++);
if ((x = hash & 0xF0000000L) != 0)
{
hash ^= (x >> 24);
hash &= ~x;
}
}
return (hash & 0x7FFFFFFF);
}
// BKDR Hash
unsigned int BKDRHash(char *str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313 etc..
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
// DJB Hash
unsigned int DJBHash(char *str)
{
unsigned int hash = 5381;
while (*str)
{
hash += (hash << 5) + (*str++);
}
return (hash & 0x7FFFFFFF);
}
// AP Hash
unsigned int APHash(char *str)
{
unsigned int hash = 0;
int i;
for (i=0; *str; i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ (*str++) ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ (*str++) ^ (hash >> 5)));
}
}
return (hash & 0x7FFFFFFF);
}
一下部分为转载:http://fullfocus.javaeye.com/blog/133223
因为有项目需要,要做一个类似ispell 的软件,其中会产生大量的对单词的查找操作,于是经过一翻研究,得出以下HASH算法,经过验证比一般的查表的FNV HASH算法产生的分布曲线基本没什么两样,并且在大部分的不同字典下,本算法要比查表的FNV HASH算法表现出速度更快,分布更均匀。但是因为是实验结果,所以暂时还没得出有效的数学推论,但是从大量的不同的字典测试数据来看,此算法确实效率不 错。
由于以前没有涉及过相关的纯算法的设计,所以刚刚开始的时候,打算随便选用一种HASH,比如说用%除大质数,然后借此搭建一个比较强壮的测试环境,然后打算根据测试结果来改进HASH算法的模型。
最开始,我的HASH函数是这样的:
unsigned int hash_func(char *str, int len)
{
register unsigned int sum = 0;
register char *p = str;
while(p - str < len)
sum += *(p++);
return sum % MAX_PRIME_LESS_THAN_HASH_LEN;
}
非常简单,但是这是绝对不可取的,通过这个函数,我选取了一个23w词的字典做为测试,当HASH SIZE=1024的时候看得出震荡幅度相当大,那么如何来改进呢?首先想到可能产生的冲突的是这种情况:abcd和acbd,对于这两种单词来说,如果用上面的HASH函数,就一定会发生碰撞,为什么呢?因为每个字符少了关于它自己的位置信息,于是第一次改进版本的HASH函数就给每个字符加上了它的位置信息,将上面所描述的函数改进为:
unsigned int hash_func(char *str, int len)
{
register unsigned int sum = 0;
register char *p = str;
while(p - str < len)
sum += *(p++) * (p–str);
return sum % MAX_PRIME_LESS_THAN_HASH_LEN;
}
某种程度上来说,比不带位置信息产生的分布图要好多了,但是仍然非常的不均匀。那么接来分析产生分布不均匀的原因,因为是用的乘法,所以仍然太过于依赖字母产生的结果了。于是改用XOR操作,选用以下函数:
unsigned int hash_func(char *str, int len)
{
register unsigned int sum = 0;
register char *p = str;
while(p - str < len)
sum += (*(p++) * (p–str)) ^ sum;
return sum % MAX_PRIME_LESS_THAN_HASH_LEN;
}
上图虽然震荡幅度比较,不过做出来的regression line明显比上两张图片平得多了。但是结果仍然非常不好,从800到100的range太大。原因还是因为数据分布得不够均匀,于是思考单独的用加法来 算是不是不太好,根据其他查表类HASH算法的过程,发现其大多都用了高低位来组合成最后的结果,于是我也采用了他们的方法:
unsigned int hash_func(char *str, int len)
{
register unsigned int sum = 0;
register unsigned int h = 0;
register unsigned short *p = (unsigned short *)str;
register unsigned short *s = (unsigned short *)str;
while(p - s < len)
{
register unsigned short a = *(p++) * (p-s);
sum += sum ^ a;
h += a;
}
return ((sum << 16) | h) % MAX_PRIME_LESS_THAN_HASH_LEN;
}
最后得出结论,不用查表的方法,而通过字符串本身的位置对字符本身进行修正的方法也能得到结果相当满意的 HASH函数,之后换了几个大小不同的字典进行测试,得出的图象都大致和上图一致,非常令人满意。对于这个项目,包括如何检查单词错误,和自动修正等等相关的内容,会随着项目的完成一一在整理成文档,希望大家支持
|
PHP中出现的字符串Hash函数 |
| static unsigned long hashpjw(char *arKey, unsigned int nKeyLength) |
| { |
| unsigned long h = 0, g; |
| char *arEnd=arKey+nKeyLength; |
| while (arKey < arEnd) { |
| h = (h << 4) + *arKey++; |
| if ((g = (h & 0xF0000000))) { |
| h = h ^ (g >> 24); |
| h = h ^ g; |
| } |
| } |
| return h; |
| } |
| 2.2 OpenSSL中出现的字符串Hash函数 |
| unsigned long lh_strhash(char *str) |
| { |
| int i,l; |
| unsigned long ret=0; |
| unsigned short *s; |
| if (str == NULL) return(0); |
| l=(strlen(str)+1)/2; |
| s=(unsigned short *)str; |
| for (i=0; i |
| ret^=(s[i]<<(i&0x0f)); |
| return(ret); |
| } */ |
| /* The following hash seems to work very well on normal text strings |
| * no collisions on /usr/dict/words and it distributes on %2^n quite |
| * well, not as good as MD5, but still good. |
| */ |
| unsigned long lh_strhash(const char *c) |
| { |
| unsigned long ret=0; |
| long n; |
| unsigned long v; |
| int r; |
| if ((c == NULL) || (*c == '/0')) |
| return(ret); |
| /* |
| unsigned char b[16]; |
| MD5(c,strlen(c),b); |
| return(b[0]|(b[1]<<8)|(b[2]<<16)|(b[3]<<24)); |
| */ |
| n=0x100; |
| while (*c) |
| { |
| v=n|(*c); |
| n+=0x100; |
| r= (int)((v>>2)^v)&0x0f; |
| ret=(ret(32-r)); |
| ret&=0xFFFFFFFFL; |
| ret^=v*v; |
| c++; |
| } |
| return((ret>>16)^ret); |
| } |
| 在下面的测量过程中我们分别将上面的两个函数标记为OpenSSL_Hash1和OpenSSL_Hash2,至于上面的实现中使用MD5算法的实现函数我们不作测试。 |
| 2.3 MySql中出现的字符串Hash函数 |
| #ifndef NEW_HASH_FUNCTION |
| /* Calc hashvalue for a key */ |
| static uint calc_hashnr(const byte *key,uint length) |
| { |
| register uint nr=1, nr2=4; |
| while (length--) |
| { |
| nr^= (((nr & 63)+nr2)*((uint) (uchar) *key++))+ (nr << 8); |
| nr2+=3; |
| } |
| return((uint) nr); |
| } |
| /* Calc hashvalue for a key, case indepenently */ |
| static uint calc_hashnr_caseup(const byte *key,uint length) |
| { |
| register uint nr=1, nr2=4; |
| while (length--) |
| { |
| nr^= (((nr & 63)+nr2)*((uint) (uchar) toupper(*key++)))+ (nr << 8); |
| nr2+=3; |
| } |
| return((uint) nr); |
| } |
| #else |
| /* |
| * Fowler/Noll/Vo hash |
| * |
| * The basis of the hash algorithm was taken from an idea sent by email to the |
| * IEEE Posix P1003.2 mailing list from Phong Vo (kpv@research.att.com) and |
| * Glenn Fowler (gsf@research.att.com). Landon Curt Noll (chongo@toad.com) |
| * later improved on their algorithm. |
| * |
| * The magic is in the interesting relationship between the special prime |
| * 16777619 (2^24 + 403) and 2^32 and 2^8. |
| * |
| * This hash produces the fewest collisions of any function that we've seen so |
| * far, and works well on both numbers and strings. |
| */ |
| uint calc_hashnr(const byte *key, uint len) |
| { |
| const byte *end=key+len; |
| uint hash; |
| for (hash = 0; key < end; key++) |
| { |
| hash *= 16777619; |
| hash ^= (uint) *(uchar*) key; |
| } |
| return (hash); |
| } |
| uint calc_hashnr_caseup(const byte *key, uint len) |
| { |
| const byte *end=key+len; |
| uint hash; |
| for (hash = 0; key < end; key++) |
| { |
| hash *= 16777619; |
| hash ^= (uint) (uchar) toupper(*key); |
| } |
| return (hash); |
| } |
| #endif |
| Mysql中对字符串Hash函数还区分了大小写,我们的测试中使用不区分大小写的字符串Hash函数,另外我们将上面的两个函数分别记为MYSQL_Hash1和MYSQL_Hash2。 |
| 2.4 另一个经验字符串Hash函数 |
| unsigned int hash(char *str) |
| { |
| register unsigned int h; |
| register unsigned char *p; |
| for(h=0, p = (unsigned char *)str; *p ; p++) |
| h = 31 * h + *p; |
| return h; |
| } |














 1544
1544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









