






基于 Hadoop 构建对象存储系统
By 云深作者: Terry/Alen/Adam/ SeymourZ
转载请注明出处
前言
l 云计算领域目前有两大代表性系统: Google 和 Amazon ,它们各自的存储系统为 Google GFS 和 Amazon S3 ,都提供高可靠性、高性能、高可扩展性的存储能力
l Hadoop HDFS 就是 Google GFS 存储系统的开源实现,主要应用场景是作为并行计算环境( MapReduce )的基础组件,同时也是 Bigtable (如 HBase 、 HyperTable )的底层分布式文件系统。 Hadoop HDFS 也有自身的局限性,虽然作为分布式文件系统称谓,但它并不适合所有的应用场合。如:单点 namespace 问题,小文件问题等,早有阐述。 http://www.cloudera.com/blog/2009/02/
l Amazon S3 作为一个对象存储系统运营,为客户提供 1 到 5G 任意大小的对象(文件)存储,从有限的资料来看, S3 没有采用 GFS 的类似的体系架构,也不对外提供完整的文件系统呈现,更多的是一种对象存储访问的形式。
l 既然 Hadoop HDFS 适合处理和存储大块的文件,我们是否也可以把 HDFS 作为一种容器看待,通过上层抽象,对外提供类似 Amazon S3 一样的对象存储功能呢?答案我想是肯定的,下面就讨论基于 Hadoop 开源项目,构建一个高可靠,高性能、高扩展性的对象存储系统,实现类似 Amazon S3 的用户接口。
系统架构
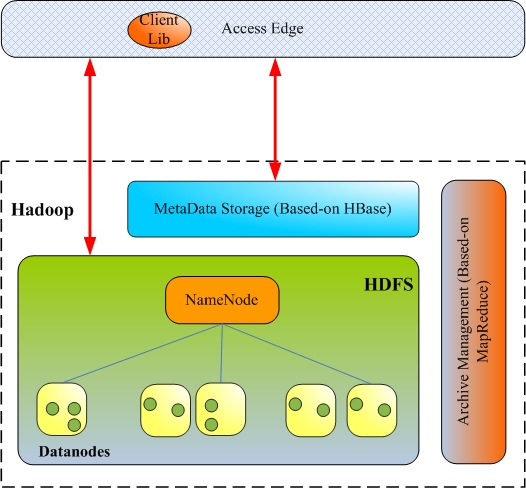
图 -1 系统架构
系统组成:
对象访问接口层( Access Edge )
§ 提供客户端 Lib ,供上层应用调用 ;
§ 提供 REST 和 SOAP 接口,支持 web 业务的访问。
对象元数据存储层( MetaData Storage )
§ 实现对象操作业务逻辑,包括:
1. Bucket 创建;
2. Bucket 删除;
3. Bucket 信息查询;
4. 对象创建;
5. 对象元数据信息查询;
6. 对象删除;
7. 对象元数据修改;
§ 负责对象元数据的管理和维护,基于 Hbase 实现,由 Hbase 实现系统的扩展和高可靠性
对象实体数据存储 (DataNode)
§ 提供对象数据的可靠存储;
§ 提供对象归档文件的存储;
§ 基于 HDFS ,支持数据冗余
归档管理 (Archive Management)
§ 零散的小对象文件的归档;
§ 归档文件的存储管理;
§ 失效对象的磁盘空间回收;
§ 归档文件的再归档;
§ 相关元数据信息的修改;
元数据存储子系统
采用 Bigtable ( HBase )的结构化存储系统,提供 Mata Data 存储:
可用 Object 元数据表结构
| 列名 | 类型 | 备注 |
| Object 标识符 | 字符串 | Row key ; 格式: Usr:bucket:full path |
| 用户自定义元数据 | 字符串 | <key , value> 列表 格式: Key0 : value0|key1:value1|… |
| 归档标志 | Bool | 标识 object 文件是否已被归档 |
| 数据位置描述 | 字符串 | 格式: Hdfs://filepath:offset:size |
| 最后修改时间 | 时间戳 | 标识元数据版本 |
已删除 Object 元数据表结构
| 列名 | 类型 | 备注 |
| Object 标识符 | 字符串 | Row key ; 格式: Usr:bucket:full path |
| 归档标志 | Bool | 标识 object 文件是否已被归档 |
| 数据位置描述 | 字符串 | 格式: Hdfs://filepath:offset:size |
Bucket 信息表结构
| 列名 | 类型 | 备注 |
| bucket 标识符 | 字符串 | Row key ; 格式: Usr:bucket |
| 用户自定义元数据 | 字符串 | <key , value> 列表 格式: Key0 : value0|key1:value1|… |
| Max space | int64 | Bucket 允许的最大空间 |
| Used space | int64 | Bucket 已使用的空间 |
注: RowKey 的设计,应该为系统处理提供最合适的索引
HDFS 中对象数据的存储形式
对象在 HDFS 中存储有两种形式:
§ 对象文件 —— 每个文件对应一个对象,对象创建时存储到对象存储系统 中的形态;
-
- 归档文件 —— 为了减少 HDFS 中小文件的数据,将小的对象文件和归档文件归档。
HDFS 中目录结构:
§ /data_dir-|-/object_dir/-|-obj_file0
| |-obj_file1
|
|-/arch_dir/-|-arch_file0
|-arch_file1
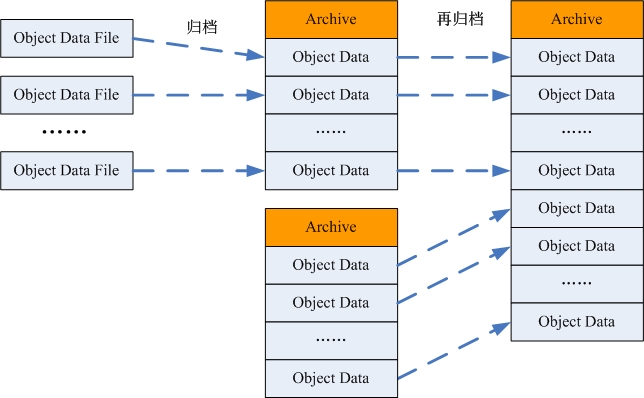
图 -2 HDFS 上的对象数据存储
Bucket 的创建和删除
Bucket 创建:
1、 Bool Create Bucket(user_id, buck_name, buck_size, … );
2、 MetaData Storage 查询 Bucket 信息表确定是否已经存在相同的 user bucket 记录 ;
3、 如果 Bucket 信息表中不存在相同的 user Bucket 记录,则在表中插入一条 user bucket 记录 ;
4、 返回 True 或者 False 表示操作成功与否;
Bucket 删除:
1、 Bool DropBucket(user_id, buck_name);
2、 MetaData Storage 查询 Bucket 信息表确定是否已经存在相同的 user bucket 记录 ;
3、 如果 Bucket 信息表中存在相同的 user Bucket 记录,则查询 ObjectMeta 表确定 Bucket 是否为空;
4、 若 Bucket 为空,则删除 Bucket 信息表中对应的记录;
5、 返回 True 或者 False 表示操作成功与否;
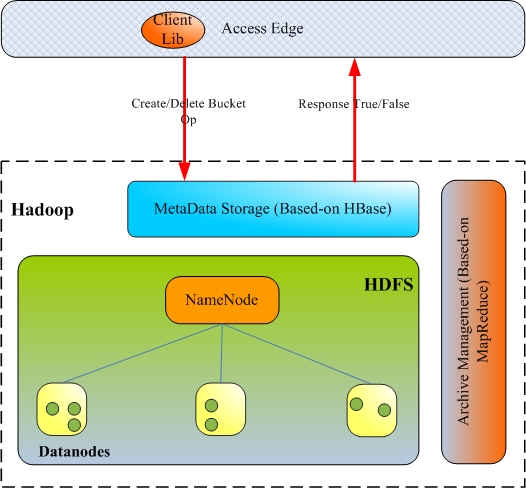
图 -3 Bucket 的创建和删除
对象的创建
-
- Client 提交创建对象请求 create_obj_req(usr,bucket,obj_key,obj_meta);
- 检查 user 和 Bucket 的合法性,要求存在、可访问、容量允许;生成对象在 HDFS 中的对象文件的 URI ;
- 返回对象文件 URI ;
- 将对象数据写入 HDFS 的对象文件;
- 通知 MetaData Storage 对象数据存储完成;
- 更新对象元数据索引信息,包括:
① 对象元数据信息插入;
② Bucket 的已使用空间大小,对于同一个对象的多个版本,以最新版本空间大小为准;
-
- 返回创建对象成功。
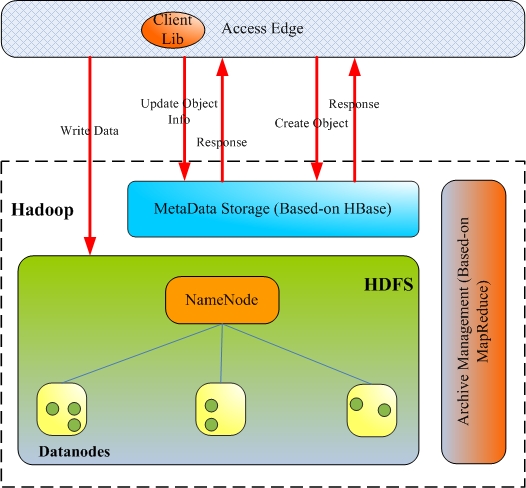
图 -4 对象的创建
对象的删除
-
- Client 提交删除对象请求 delete_obj_req(usr,bucket,obj_key);
- 检查 user 和 Bucket 的合法性,要求存在、访问权限;不合法则返回失败;
- User 和 Bucket 检查通过,则进行如下处理:
① 删除对象在元数据表中的信息;
② 将删除对象及其在 hdfs 中的路径信息存入到已删除对象表中;
③ 更新 Bucket 使用空间大小;
对象删除时,对象可能有两种存储形态:
-
- 对象文件 —— Archive Management 归档处理时,会直接删除无效的该文件;
- 归档文件的一部分 —— Archive Management 对磁盘利用率低的归档文件压缩处理时,删除该数据;
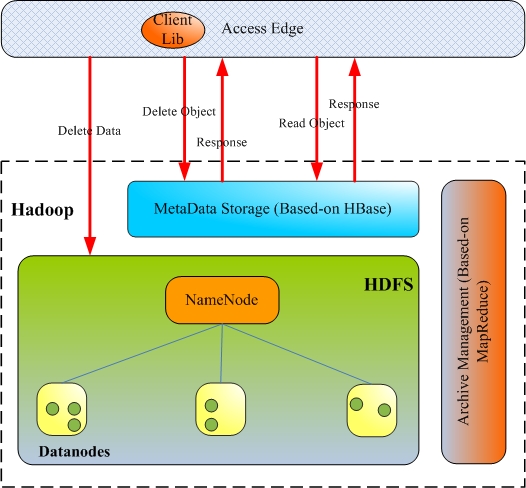
图 -5 对象的删除
小文件的归档管理
该部分主要由周期性执行的 MapReduce 任务完成;有以下几个处理流程:
-
- 对象归档
- 扫描元数据信息表,统计未归档的对象信息,包括在 HDFS 中的 URI 、对象大小等;
- 根据配置的归档文件大小限制,对统计所得的对象进行分组;
- 将每个分组中的对象文件合并到一个归档文件中;
- 更新相关对象元数据信息表中的数据位置描述项;
- 删除旧的对象文件;
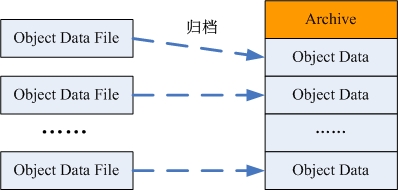
图 -6 小文件的归档
归档文件的压缩
-
- 扫描已删除对象表,统计无效对象信息;
- 对于未归档的无效对象文件,直接删除;
- 将已归档的无效对象按照归档文件分组;
- 统计涉及到的归档文件的空间利用率;
- 统计利用率利用率低于阈值的每个归档文件中所有有效对象信息;
- 将归档文件中的有效对象数据合并到一个新的归档文件中;
- 更新相关对象元数据信息表中的数据位置描述项;
- 删除旧的归档文件;
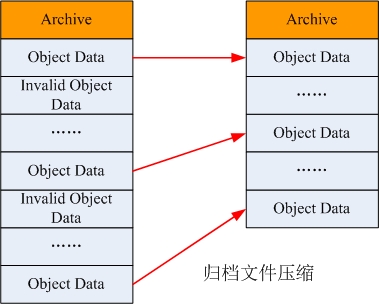
图 -7 归档文件的压缩
归档文件的再归档
1. 扫描归档文件列表,统计占用磁盘空间低于阈值的归档文件;
2. 根据归档文件大小配置参数,将统计所得归档文件分组;
3. 统计各分组归档文件涉及到的对象;
4. 将每个分组中的归档文件合并到一个归档文件;将归档文件中的有效对象数据合并到一个新的归档文件中;
5. 更新相关对象元数据信息表中的数据位置描述项;
6. 删除旧的归档文件;
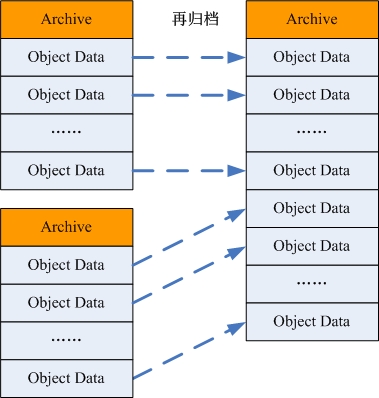
图 -8 归档文件的再归档
总结语
基于 Hadoop 实现类似 Amazon S3 的对象存储系统,有一定的先天优势,例如 Hadoop 的 HDFS 作为数据存储的容器,解决了数据冗余备份的问题; Hadoop 的半结构化的存储系统 HBase 可以支撑 MetaData 的存储,同时解决了 MetaData 存储层的可靠性和可扩展性等问题。 HDFS 天生不能适合存储大量小文件的缺陷,可以使用 MapReduce 处理架构在后台提供对象归档管理功能( Hadoop 已经有了 HAV 的功能,只是没有平台化),使得 HDFS 仍然存储自己喜欢的“大文件”。这种基于 Hadoop 实现的对象存储系统,并不能保证在现阶段达到和 Amazon S3 一样的服务效率,但随着 Hadoop 系统的不断完善(例如 HDFS 访问效率的提高, Append 功能的支持等),相信也能有不俗的表现。















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









