









一 Auto-Sharding简介
MongoDB提供了一种称为Auto-Sharding,即自动分片的机制来实现系统的水平扩展。虽然分片的概念源于关系型数据库的分区,但还是有一些差别。最大的差别是MongoDB自动完成所有的工作,不需要人工介入,并且当各个分片中的数据分布不平衡时,自动完成数据地重分布。
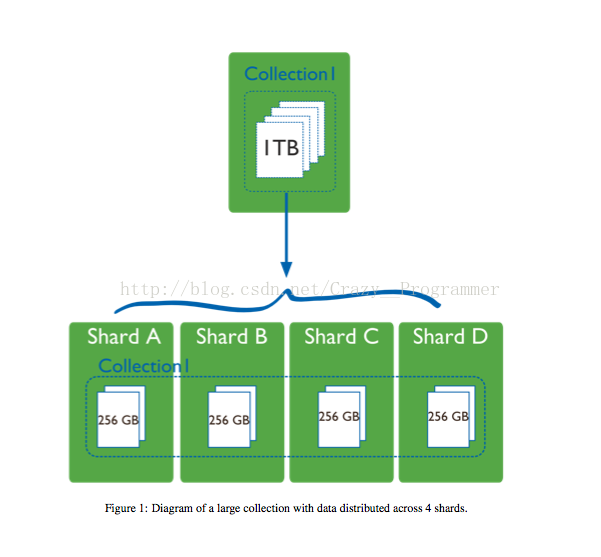
分片(Sharding)是指将数据拆分,分散在不同机器上的过程,有时也用分区(partitioning)来表示。使用分片不仅可以将数据分散到不同的机器上,不需要功能强大的大型计算机就可以存储更多的数据,而且分片将对数据库的读写操作分散到不同的机器上,可以有效减少单台机器的CPU和RAM的压力,提高QPS,使整个集群能够处理更大的负载。
使用分片集群需要满足很多的要求,其部署的代价是比较高的, 什么时候会用到分片集群的部署?
1. 存储的数据集接近或将超过单个MongoDB实例存储数据能力的时候。
2. 系统活跃工作集将要超过你系统RAM最大容量的时候(希望将大量数据放在内存中提高性能)。
3. 单个MongoDB实例无法满足写操作请求的时候(单个mongod已经不能满足写数据的性能需要了)。
注意:部署分片集群需要花费大量的时间和资源,如果当你的系统已经达到或超过它的极限的时候再部署分片集群的话,那么在不影响你应用的情况下部署分片集群是困难的。如果你认为你需要将来划分你的数据库的话,不要等你的系统超过其能力的时候才进行分片,也就是说分片要提前去进行。
二 Auto - Sharding 成员
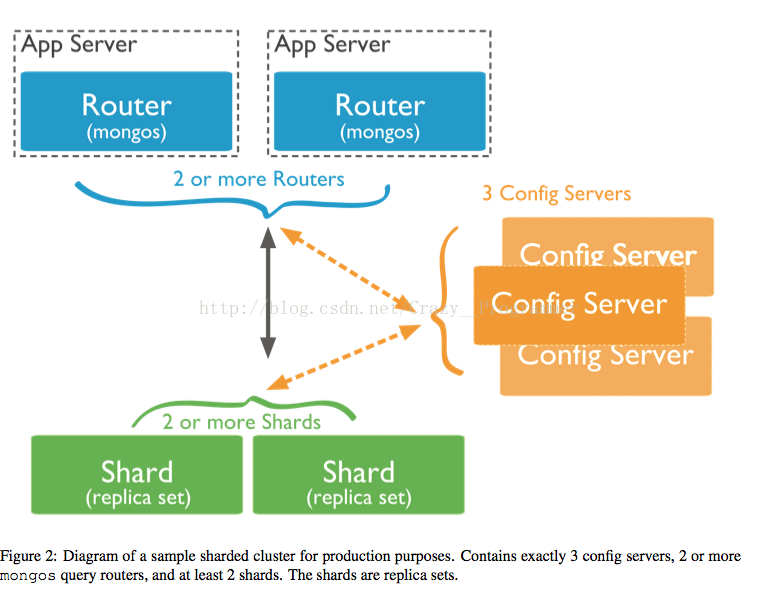
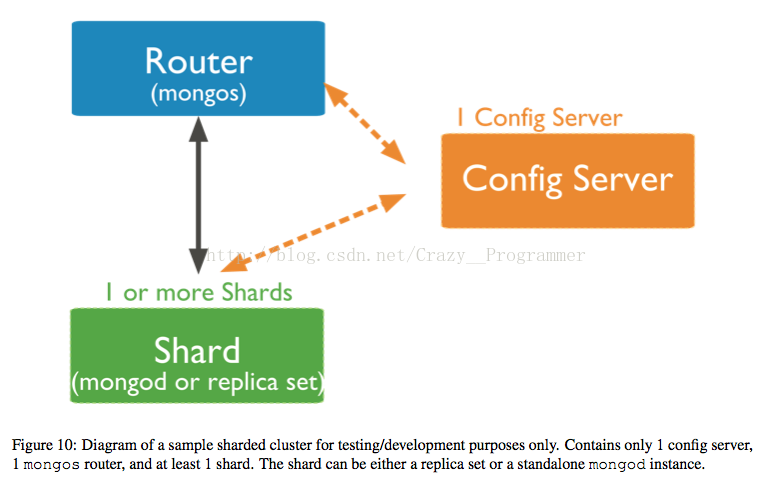
分片集群(Sharded Cluster Components):由shards、Config Servers 和 mongos instance(query routers)三部分组成。分片就是将数据存储到多台机器中,使用分片来使数据横向存储支持大规模的数据集部署和支持负载均衡提高吞吐量。
Shard
称为片,上面运行mongod进程来存储数据。每个shard 可以是一台服务器运行单独一个Mongod实例,但是为了提高系统的可靠性实现自动故障恢复,一个Shard应该是一个复制集(官方建议)。
Shard相当于Hadoop HDFS中的datanode,用来存储数据。每个Shard中存储了一个集合的的部分数据,即集合的子集。
注意:1.在开发测试环境下,一个Shard可以只包含一个mongod实例。但在商业部署的条件下,一个 Shard是一个复制集。
2.只有分片的集合,它的文档才会水平的存储到集群的各个分片上,没有分片的集合的文档会存储到主分片上(primary shard)。主分片用来存储已分片的集合和未分片的集合的数据。
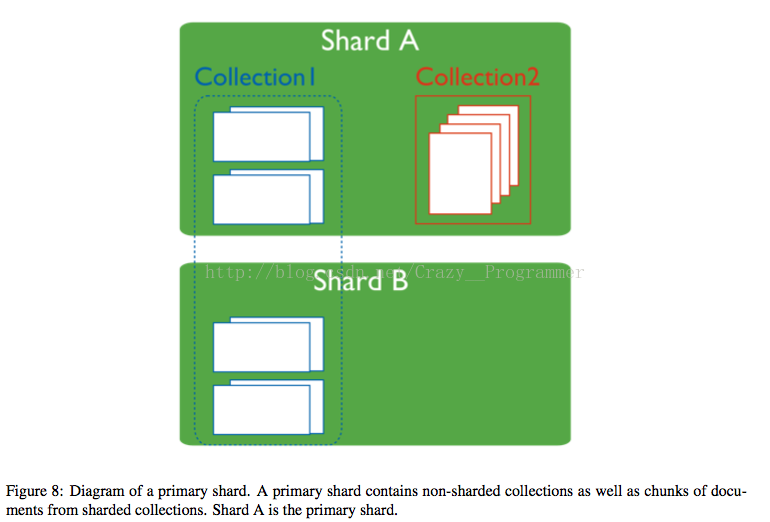
3. 使用movePrimary命令可以改变主分片,但是这样会付出很大的代价,因为它会将所有未分片集合的数据拷贝到主分片上,而在拷贝数据的过程中你是不能进行其他操作的。当我们部署分片集群的时候,第一个分片会被默认的作为主分片。
4. 使用sh.status() 方法可以查看整个分片集群的状态 :包括哪个分片是主片,数据块的分布情况。
Config Server (配置服务器)
配置服务器是一个Mongod实例,它负责存储了集群中的
元数据(MetaData) ,包括每个shard服务器上的块列表以及每个数据块所对应的片键取值范围
,每个配置服务器都有一份包括所有块信息的完全副本,系统使用一个两阶段锁提交协议来保证config server中配置的快速一致性和高可靠性。
Config Server 相当于Hadoop HDFS中的镜像文件和编辑日志
Config Servers有张从数据块到具体分片的映射表, monogs进程通过这张映射表来将客户端的请求路由到指定分片上,在商业部署上一般会放置3个配置服务器。
注意:为防止单点故障,进行备份和提高安全,在实际部署时通常是需要部署3个配置服务器。如果只部署一个配置服务器,它出现故障宕机的话,那么整个集群就无法访问。如果它无法从故障恢复的话,这个集群也将不可用。
配置服务器存储的数据是十分重要的,应该经常对其进行备份,
注意:
1.如果三个中的一个或两个配置服务器变的不可用,那么整个集群的元数据就会变为只读状态,但此时你仍然可以从分片读和写数据,但是在Shard中不会进行数据块的分割和移动,只有三个配置服务器都可以用的情况下才会进行数据块的分割和移动。
如果三个配置服务器都变得不可用了,在没有重启mongos进程的情况下,你依然可以读写集群中的数据,但是如果在所有配置服务器变得可用前你重启了mongos进程的话,那就无法进行读写了。也就是说,在没有集群元数据的情况下,整个集群是无法使用的。所以要总是确保配置服务器的可用且功能完整。
2. 当有下列情况发生时会写配置服务器:当有数据块进行分裂的时候;在分片间移动数据块的时候;
当有下列情况发生时会读配置服务器:当mongos集群第一次启动的时候,或者一个已经存在的mongos进程进行重启的时候;当一个数据块移动完毕后,mongos进程更新自己缓存的元数据的时候。
Mongos
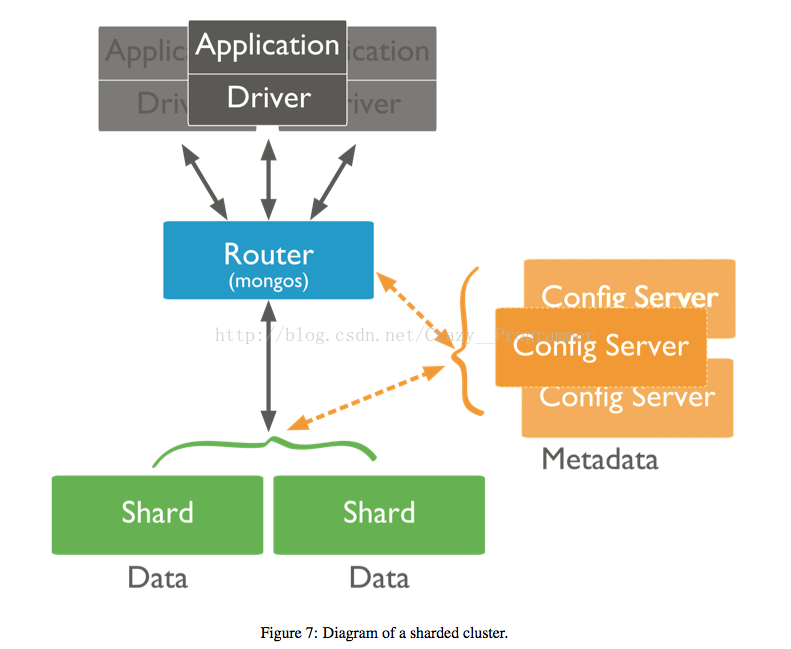
Mongos是一个mongos进程,可以将其看作一个路由和协调进程,它是集群与客户端交互的窗口,它使集群中多个组件看起来像一个单一的系统。
当Mongos启动的时候,它会从配置服务器获取同步数据 ,将配置服务器存储的数据全部缓存到内存中,当收到客户端的请求时,mongos通过查找映射表为请求寻找合适的片服务器,并将聚合后的结果传送给客户端。
Mongos的功能类似于Hadoop HDFS中的namenode,协调调度作用。
Mongos 进程并不需要持久状态,它的数据是其刚启动时从配置服务器中获得的,configure serve中发生的任何变化都会传播到每一个mongos进程。monogs进程可以运行在任何服务器上,同时启动的mongos进程数量也没有限制。
注意:1. 在开发测试环境下可以只用一个mongos进程,为了分担来自客户端的请求,和避免单点故障需要启动多个mongos进程。
2. 客户端的程序不能直接访问分服务器,mongons隐藏了分片的细节,对于客户端来说是透明的。
3. 在实际部署的集群中,确保你的数据是有备份的,你的系统是高可用的,不存在单点故障点。为了达到上述的目的,一个商业集群必须有一下的组件:3个配置服务器,每一个配置服务器必须在不同的机器上 ,两个或多个复制集 ,一个或多个mongos。
4. 在开发测试环境下的分片集群组件:一个配置服务器;至少一个分片 (一个复制集接或者是一个mongod实例);一个mongos实例。
三 Sharding工作过程
为了维护数据的均衡分布,MongoDB使用了两个后台进程:一个是分割器(
Splitting
) ,一个是平衡器(
Balancer
)。
分割器(Splitting)
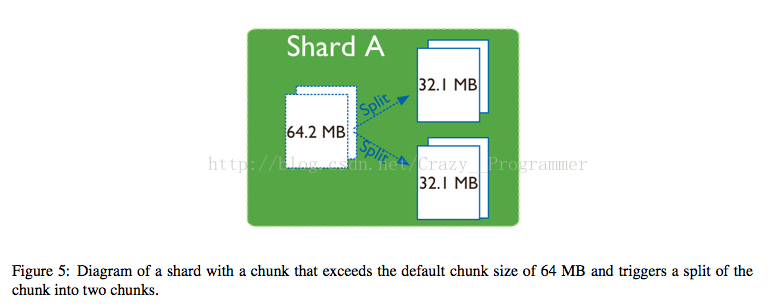
分割器的作用是防止数据块变大, 当一个数据块中的数据“长大”到指定大小时,分割器会将其一分为二。插入和更新操作都有可能触发分割。 分割的对象不是具体的数据,而是元数据,也就是说分割的过程只是修改元数据,可以认为是一种逻辑上的块划分,不会影响到分片上数据的分布,其过程是非常高效的。
数据块大小的选择
MongoDB将片键的值域划分为不重叠的区间,每一个子区间对应一个数据块。MongoDB在集群间分发数据块。 数据块默认大小是60MB,也可以增大和减小。
如果块设置的太小的话,少量的数据会产生大量的块,很容易使集群进入不平衡的状态,会引起频繁的块移动,影响集群的性能,除此之数据块的个数的增加,也会导致元数据的文件大小的增加,影响查询效率。
如果数据块太大的话,会减少数据块移动的频率,有利于数据的查询,但是一旦需要移动数据块的时候会花费很长的时间,影响集群的整体性能。
注意:数据块的大小是可变的,减小当前数据块大小的时候,系统需要花费时间来将原来大的数据块进行分割;如果增大当前数据块的话,原来小的数据块会继续“长大”直到超出新的设定值。
平衡器(Balancer)
平衡器的作用是管理数据数据块的移动, 当一个集合的数据块在集群中分布达到移动阈值(Migration Thresholds)的时候,平衡器就将数目最多的分片上的数据块移动到数目比较少的分片上。比如说,users集合在分片1上有100个数据块,分片2上有50个数据块,平衡器就会将分片1上的数据块移动到分配2上,直至uers集合在两个分片上的数据块个数相同。
数据移动的过程
1.平衡器向源分片发送moveChunk的命令
2.源分片收到命令后,会启动自己内部的一个moveChunk命令,如果在数据移动过程中有客户端发来读写请求的话,都会发送到源分片。(因为配置服务器上的元数据还没有改变)
3. 目标片开始向源分片请求将要移动的数据块的文档,准备拷贝文档数据。
4 .当目标分片接收到据块的最后一个文档后,目标分片会启动一个同步进程来检查,是否已经拷贝完全部的文档。
5 .当同步完成后,目标分片会连接配置服务器,更新元数据列表中数据块的地址。
6. 当目标分片完成元数据更新后,源分片就会删除原来的数据块.如果有新的数据块需要移动的话,可以继续进行移动。
7.配置服务器会通知monogs进程更新自己的映射表。
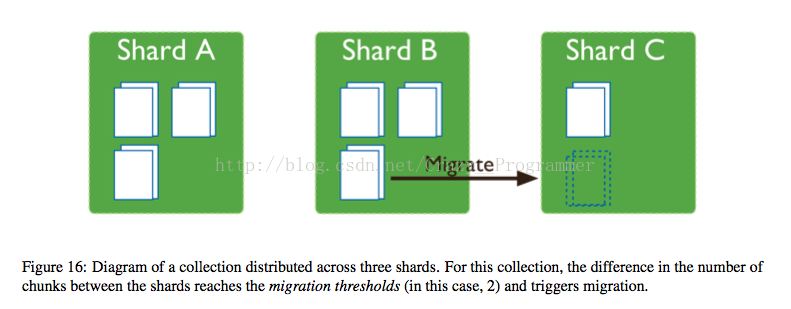
移动过程中,目标分片会拷贝源分片上将要移动的数据块中的文档,当移动完成后会更新配置服务器上的元数据,并删除源分片上的数据块。如果移动过程中,涉及到正在移动数据块的数据请求都会发送到源数据块上。如果移动过程中,发生错误的话,平衡器就会终止数据的复制,将待移动的数据块还保留在源分片上。
当添加和删除分片的时候都会使集群进去不平衡的状态,导致数据块的移动。
注意:1.平衡器的工作有两个目标,第一是保持不同分片之间的数据平衡,另外还需要尽量最小化不同分片之间交互的数据块次数。
2.除了使用平衡器自动移动数据块外,也可以手动的方式来移动数据块。
3.默认数据块的大小是64MB,平衡器不能保证每个分片间的数据块时刻是相等的,如果那样的话会频繁的发生数据块的移动,这样会严重影响集群的性能。一般情况下会设定一个(Migration Thresholds)移动阈值,当集群中不平衡数据块超过指定阈值的时候,才会进行数据块的移动。
4.在实际的条件下,你的数据会保持在一个单一分片上,除非你的集群有成千上百个数据块的时候。
下一节重点介绍片键的选择问题














 1592
1592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









