






python爬数据小试牛刀–beautifulSoup使用
1.环境配置
- 编译环境:python 2.7
- 编译器:pycharm
- HTML或XML提取工具:beautifulSoup(安装自行百度)
2.网站分析
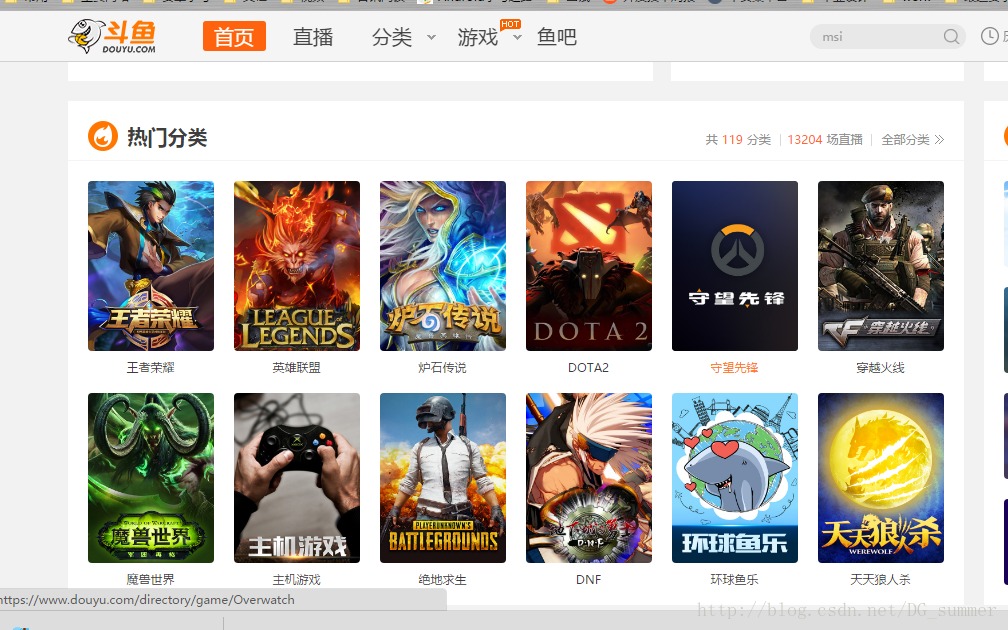
- 网站:斗鱼(http://www.douyu.com)
- 爬取目标:首页的图片
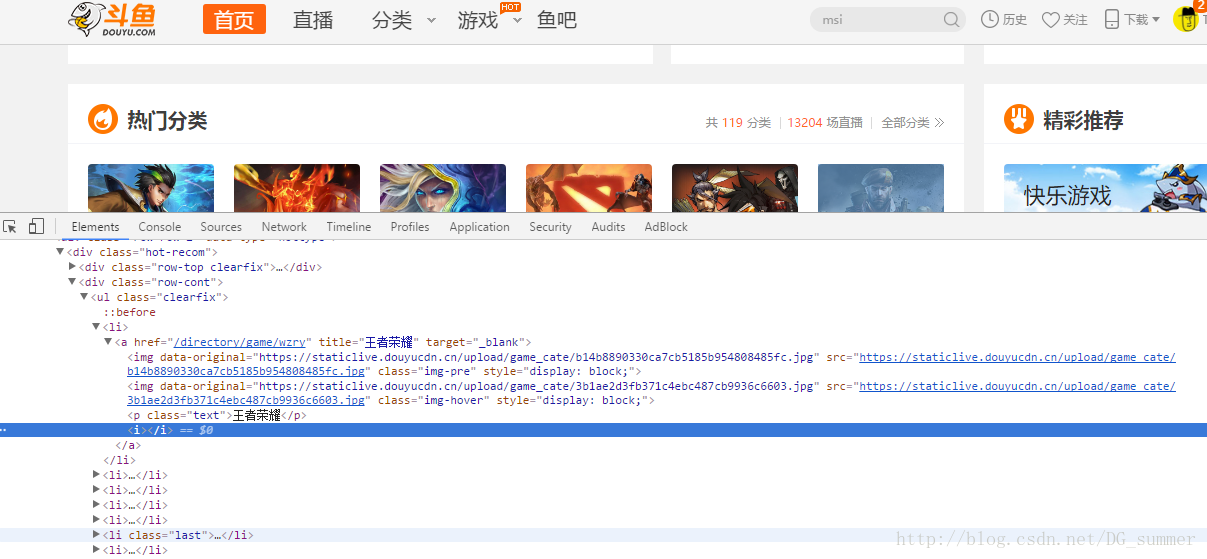
- 步骤一:查看图片信息,鼠标右键图片,选择检查
- 步骤二:分析发现图片连接都在src下面
- 步骤三:代码编写
- 导入库

 3980
3980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















