







Application Layer 应用层


第一句话作者是说网络应用是计算机网络存在的理由吗?(有个貌似是法语词查了下,我觉得应该是)——如果我们做不出任何有用的应用 ,那么久没有任何必要有网络协议来为他们提供支撑 。
这一章我们将学习网络应用的概念和实现层面 ,我们从定义主要的应用层概念开始 ,包括应用,客户端,服务器,进程和传输层接口所需要的网络服务。 我们详细介绍几个网络应用,包括Web,email ,DNS , 和peer-to-peer(P2P) file distribution . 之后我们在TCP和UDP之上讲网络应用的发展,我们将学习socket API并学习一些用Python语言编写的简单的客户-服务器应用 ,我们还在章尾提供了几个有趣的套接字编程任务。
应用层是开始学习协议的好地方,我们已经熟识了很多应用,这些应用都仰赖于我们将要学习的协议, It will give us a good feel for what protocols are all about and will introduce us to many of the same issues that we’ll see again when we study transport, network, and link layer protocols.(翻不下去了 ,shit!!)
2.1 Principles of Network Applications
如果你有一个很好的新的网络应用的点子 ,他可能会服务全人类,可能取悦你的上司,可能让你发财 ,别管动机是什么,我们现在来看看怎么让想法变成实际的应用 。
网络应用的核心就是编写能运行于不同终端而且能通过网络互相交流的程序 ,例如Web应用就有两个很重要的程序,浏览器运行于用户的计算机,Web服务器程序运行于服务器主机 。
所以开发你的应用的时候你需要写能运行于多种终端系统上的软件程序 ,可以用C ,Python或者java ,重要的是,你不用为运行于网络核心的部件写软件,比如路由器和链路层交换机 ,即使你想写也不行,如我们第一章所学的,网络中心的设备不作用与应用层而是作用于较低的层次 ,特别是在网络层及其以下 ,这种基本的设计就是让应用软件与终端系统隔离。
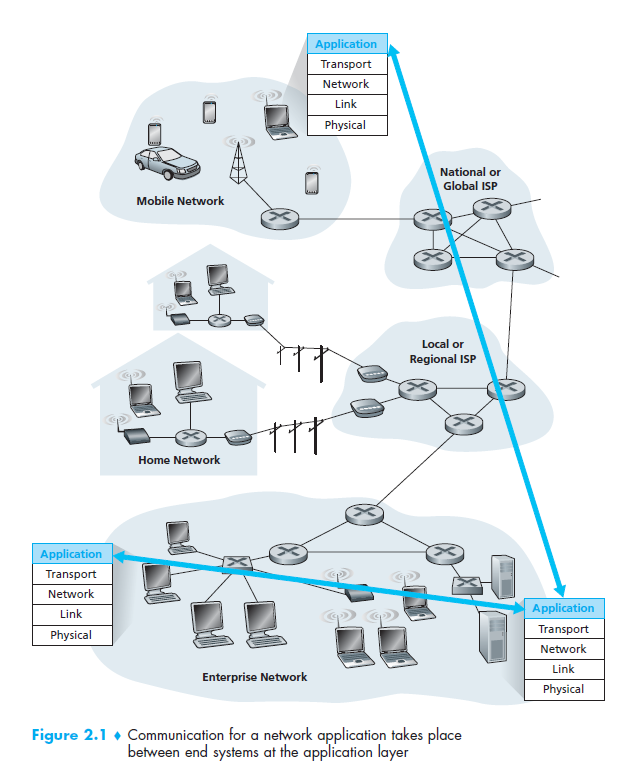
2.1.1 Network Application Architecture
应用架构和网络架构不同,网络架构是固定的五层,而应用架构是由开发者决定的,而且受到所运行的终端系统的制约,在这方面,开发者通常学者两种主要架构方式中的一种,客户-服务器架构或者P2P架构 。
客户-服务器架构中有一个永远在线的主机 ,叫做server,其他向它请求服务的计算机我们叫做clients ,这种架构中,各个client不是直接与彼此交流的,这种架构的另个特点是server有个公开的,固定的地址,叫做IP地址,由于servern有个固定的地址而且一直在线,所以client可以随时发送数据包到server。用这种结构的应用有Web ,FTP ,Telnet和email .
对于客户-服务器架构的应用来说,一个服务器可能不够用,所以便出现了data center ,这里集合很多主机,用来组成一个强大的虚拟主机 。
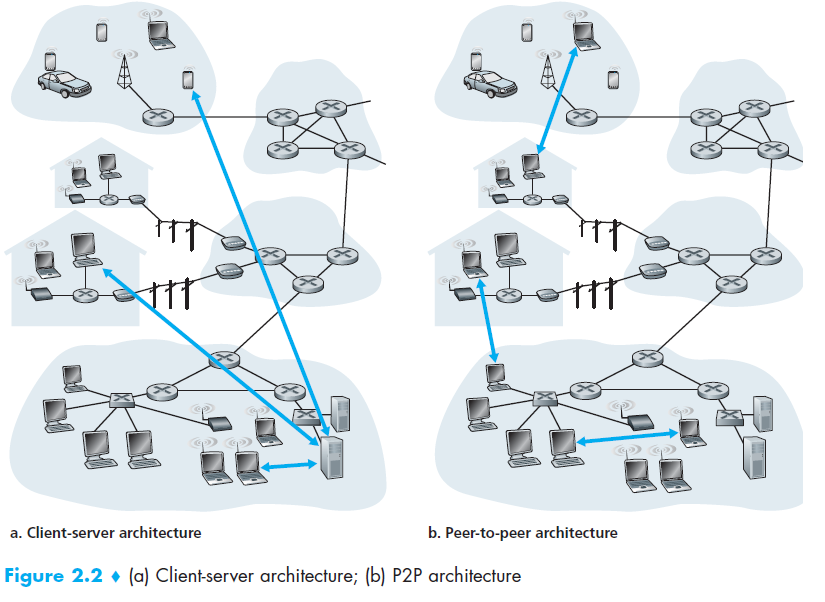
对于P2P架构,它很少或者根本不依赖或极少依赖服务,取而代之,应用会在成对的间接连接的计算机间提供直接通信 ,叫做peers ,peers不是被服务提供者占有的,而是使用者的台机或笔记本,因为peers通信不经过服务器,所以这架构叫做P2P, 今天很多流量很大的应用都是基于P2P架构,包括文件分享(比如,BitTorrent),网络电话(比如,Skype)。。。。。
有些应用是混合架构的,比如许多即时通信软件,服务器用来追踪用户的IP地址,但是用户间的信息传送石不需要经过经过服务器而是直接传送的。
P2P架构一个最吸引人的特点是self-scalability(自扩展),例如,在一个P2P文件分享软件中,虽然每个终端请求文件都产生工作量,但每个终端通过向其他终端分发文件增加了系统的服务能力 ,而且这个架构不用配置服务器这种基础设施所以就很省钱,但是这种架构面临三个主要挑战:
1).ISP Friendly :很多居住区的ISP都是非对称带宽,即下载比上传要快的多,但是P2P视频流软件和文件分享软件都把上传压力从服务器转到ISP,所以造成很大的ISP压力,所以以后的P2P应用应该设计的ISP友好一些。
2).Security :由于它高度分散式和开发的特点,P2P应用在安全方面有很大挑战
3).Incentives :P2P应用将来的成功将取决于让用户愿意为应用分享带宽,存储,和计算资源,所以激励政策也是一大挑战。
2.1.2 Processes Communicating 进程通信
在构建应用之前,我们还得知道程序通信的基本原理,在计算机术语中叫做进程通信,如果进程运行于同一个终端系统,那进程间通信就可以解决问题,但是我们这本书更关注的是在不同计算机间通信。
两个不同终端系统中的进程通过网络交换messages来通信,进程通信在应用层。
Client and Server Processes
一个网络应用由彼此通信的进程组成 ,我们通常把发送方叫做client,响应方叫做server 。P2P应用中也许你发现终端即是client也是server ,但是我们定义如下:
In the context of a communication session between a pair of processes, the process that initiates the communication (that is, initially contacts the other process at the beginning of the session) is labeled as the client. The process that waits to be contacted to begin the session is the server.
The Interface Between the Process and the Computer Network
通过学习我们知道 ,应用包含很多对交流进程,两个进程彼此发送信息的时候,进程发送到网络和从网络中接收信息都要一个软件接口,叫做socket ,一个类比就是process是房子,socket是门,
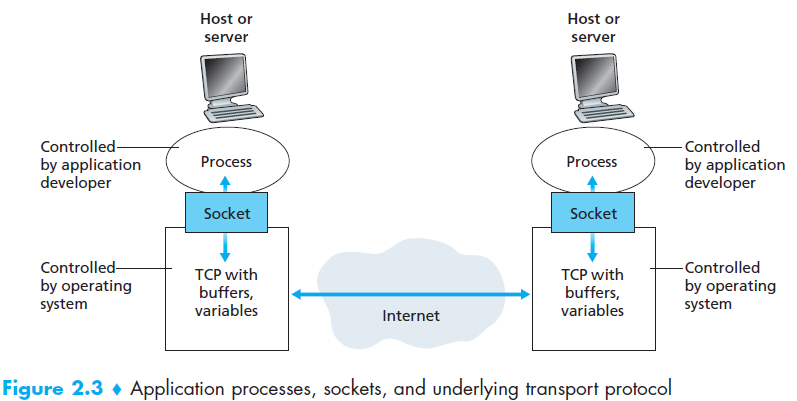
上图描述了两个进程间的socket 通信(传输协议假设为TCP协议),socket是计算机内应用层与传输层的接口 ,socket也叫做应用与网络间的API(Application Programming Interface),因为socket是构建应用所仰赖的编程接口。
应用开发者可以控制应用层的所有东西,但是对传输层的控制却几乎做不到,唯一可以控制的传输层部分为(1)传输协议的选择(2)大概还能确定下一些传输层的参数,比如缓冲区最大值,最大的包尺寸 。
一旦开发者选中了哪个传输层协议, 应用就得用这个协议所提供的服务来构建 。
Addressing Process
一个主机上的程序如果想发送数据包到另一个主机上的程序,那么接收方就得有个地址,为了识别目标,两个信息需要被指明:(1)主机的地址(2)能明确出主机上的接收程序的标识符 。
在互联网中,我们用IP地址来识别主机 ,它是个32位的数,可以认为它是唯一的,除此之外,我们还得有个标识说明哪个程序(或者更准确,哪个接口)来接受消息,因为通常一台计算机会运行很多网络应用 ,目标主机的port number(端口号)能解决这个问题 。很流行的应用都有特定的端口号 ,举个栗子,Web server的端口号是80, mail server的端口号是25,一个列表。
2.1.3 Transport Services Available to Application
我们上边说socket是应用进程和传输层协议之间的接口,发送方的应用把信息通过socket发送,在socket的另一边,传输层协议得把信息传输到接收进程的socket 。
我们可以大致的把传输层协议所能提供的服务分为四部分,reliable data transfer ,throughput ,timing ,and security 。
Reliable Data Transfer
我们第一章讲过 ,数据包在传输中会丢失 ,对于一些应用,包的丢失可能造成极大的损失(比如商务软件),因此,我们需要一种保障信息传输正确且完整的服务,如果一个协议提供了这样一种服务,就叫做提供reliable data transfer ,有了这个服务,发送方可以确信信息一定能完整无误的到达。
当协议不提供这种服务的时候 ,也许就会出现信息丢失,这种协议可以被loss-tolerant application接受,大多数的多媒体软件是用这种协议的,因为一些小的信息丢失并不会造成很大影响 。
Thoughput 吞吐量
前边我们已经说过,两个进程间通信,发送方可以发送信息到接收方的速率就是吞吐量,因为网络中会有其他sessions共享带宽,而且这些sessions会来来去去,就造成了吞吐量随时间波动,这些就引出了另一个传输层协议可以提供的服务,叫做保证指定值的吞吐量,这服务会确保吞吐量始终是大于等于你给定的值,举个栗子,一个网络通话应用需要32 kpbs速率,如果协议不能提供这个速率, 那这个通话可能得放弃,这些对吞吐量有特殊需求的应用叫做bandwidth-sensitive application ,当今许多多媒体应用都是这种,当然也有一些应用用自适应编码技术来跟当前可用吞吐量匹配 。还有一类弹性应用是无所谓吞吐量的,比如email ,file transfer ,
Timing
传输层协议还可以提供时间保障服务,这种保障会有很多形式,比如我们可以让每个发出的字节都在100 ms内到达目的地,这会吸引一些实时交互应用 ,对于非实时应用,当然也是低延迟比高延迟要好一些 。
Security
最后,传输层协议还能提供一种或多种安全服务,举个栗子,在发送方,协议可以对发出的所有数据进行加密,然后再接收方,协议还可以提供解密 ,除此之外,还可以提供data integrity 和 end-point authentication 等服务
2.1.4 Transport Services Provided by the Internet
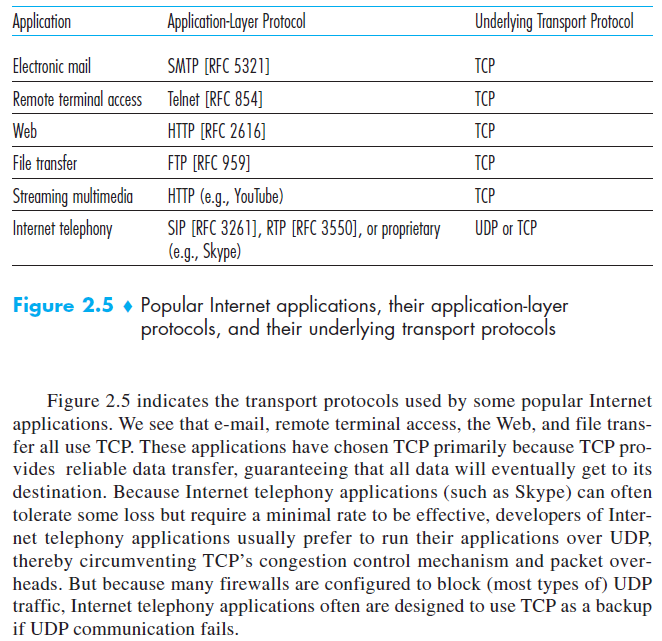
互联网(更确切的,TCP/IP网络)向应用提供两种传输层协议:TCP和UDP ,当你搞出来一个应用的时候,你最先要考虑的就是用TCP还是UDP ,它们两个给应用提供不同系列的服务 。
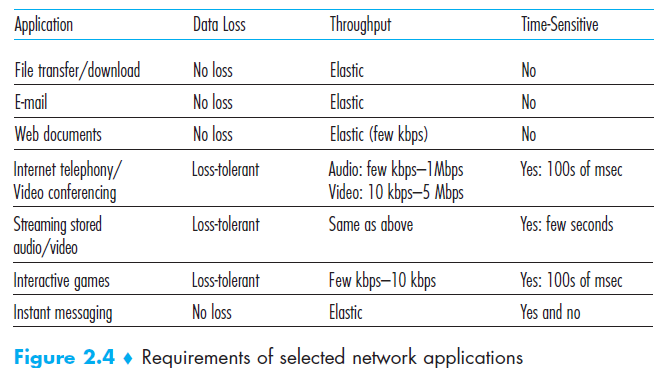
下图是一些应用的服务需求
TCP Service
TCP服务模型包括面向链接的服务和可靠信息传输的服务,但应用用TCP做传输层协议的时候,它就同时享有这两种服务。
Connection-oriented service :TCP 协议在开始发送应用级消息之前client和server得彼此交换传输层信息,这个所谓的握手警告client和server要准备好数据包开始传输了,完成握手对话后,在两个进程的socket之间就会出现一个TCP connection ,这个connection是全双工的,就是说client和server可以同时向彼此发送消息 ,但应用完成消息传输之后 ,它还必须拆除这个connection ,
Reliable data transfer service : 通信进程可以仰赖TCP保证所有的数据都无误正确的传输,但发送方把字节流送人socket,它可以指望TCP把同样的字节流传输到接收方socket ,不会有丢失,也不会有重复 。

UDP Services
UDP是一个不提供不必要服务的,轻量级的传输层协议 ,提供最少量的服务,UDP is connectionless,所以进程可是通信前没有握手 ,UDP提供不可靠的数据传输 ,
UDP没有阻塞控制机制,所以发送方发送速率可以是任意它乐意的(说明下 ,实际的端对端吞吐量可能小于传输速率,因为干预连接的传输能力的限制和阻塞)
Services Not Provided by Internet Transport Protocols
我们已经把传输层协议能提供的服务分为四个部分 ,我们前边都看到了TCP提供可靠数据传输服务,TCP还可以用SSL来加强提供安全服务 ,但是我们简单的介绍中很容易发现并没有提及吞吐量保障和时间保障 ,传输层协议没有提供这两种服务,是不是意味着需要这两种服务的应用就不能在今天的互联网中运行了呢?当然不是,我们后边会讲为什么,总结下来,今天的互联网总能提供满足时间敏感应用的服务,但是不能提供任何时间或吞吐量的保障 。
2.1.5 Application-Layer Protocols
我们讲到网络进程通过发送消息到socket来进行交流 ,但是这些messages是怎么结构化的呢?messages的各个部分又是什么意义呢?进程是怎么发送messages的呢 ?这些问题引领我们进入应用层协议 ,一个应用层协议定义了应用的进程是怎么在不同的终端系统运行并彼此发送消息的 ,特别的,应用层协议定义了:
1).交换的消息的类型,举例,请求消息和回复消息
2).不同的消息类型的语法,比如消息中的某一部分是怎么界定的
3).消息中各个部分的语义,就是每个部分中信息的意义
4).决定什么时间,什么方式来发送消息和接收消息的规定
一些应用层协议是在RFC中明确说明的,因此是公共的,举个栗子,We的应用层协议是HTTP(HyperText Transfer Protocol),它就在RFC中有详细说明,如果开发者遵循HTTP协议来开发,那么这个应用就能访问所有遵循这个协议的网页和服务器 ,还有其他一些协议是不公开的,私有的,举例,Skype就是用私有的传输层协议 。
区分网络应用和应用层协议是很重要的,应用层协议只是应用的一部分 ,举例 ,Web是一个客户-服务器架构的应用,它由很多部分组成 ,包括文本格式保准HTML,Web浏览器(火狐,IE等),Web服务器(Apache或Microsoft),还有应用层协议 (HTTP),它定义浏览器和服务器间交流所交流信息的格式和顺序 ,因此看出协议只是应用的一部分 。
2.1.6 Network Application Covered in This Book
如今每天都会产生很多网络应用 ,但我们不会用百科全书的方式讲很多,我们只挑选几个普遍而且重要的 ,有Web ,file transfer ,electric mail ,directory service(目录服务,如DNS),还有P2P applications.
2.2 The Web and HTTP
1990早期的时候互联网还只是在学术研究领域使用,但是后来有了一个重要的应用,第一次吸引了普通大众的眼球,就是World Wide Web ,它改变了人们交互的方式,而且还在持续改变,它把因特网由众多数据网络中的一个提升成为唯一一个。
吸引大多数用户的是Web请求即答复,用户只得到他们想要的,而不是像以前的广播电视一样 ,除了这一点,Web还有许多让人痴迷的特点,个体在Web上发布信息变得非常简单,每个人都可以是出版人,而且价格低廉,还有超链接和搜索引擎,Forms ,JavaScript,Java applets等很多工具让我们可以与网页和站点交互,2003年之后很多牛逼的应用在Web这个平台上发展起来,比如YouTube,Gmail,Facebook 。
2.2.1 Overview of HTTP
超文本传输协议HTTP是Web的心脏,HTTP在两个程序中执行:client program和server program ,运行于不同的终端系统,通过交换HTTP messages来彼此交流,HTTP定义了这些messages的结构和client与server交换信息的方式 。再详细说明HTTP之前,我们先来看一下Web术语,
Web page(也叫做document)由objects组成,一个object就是一个简单的文件,例如一个HTML文件,一张JPEG图片,或者一个视频片段,这都是可以通过URL寻址的,大部分Web page都有一个base HTML file和几个其他的objects。
base HTML file通过其他对象的URL在页面中引用它们,URL有两个部分:存储这个对象的服务器的主机名和这个对象的路径名 。
http://www.someSchool.edu/someDepartment/picture.gif
例如上边的URL,www.someSchool.edu是主机名,/someDepartment/picture.gif是路径名。
由于Web浏览器(比如火狐和IE)执行client方的HTTP协议,所以在Web的语境中,我们可以把browser和client替换使用 ,Web服务器执行server方的HTTP协议,存放Web objects(每个都可以是可以通过URL寻址的)。
HTTP定义了Web client如何从Web server请求Web pages和服务器如何把Web pages发送给client ,下图就是大体过程 。
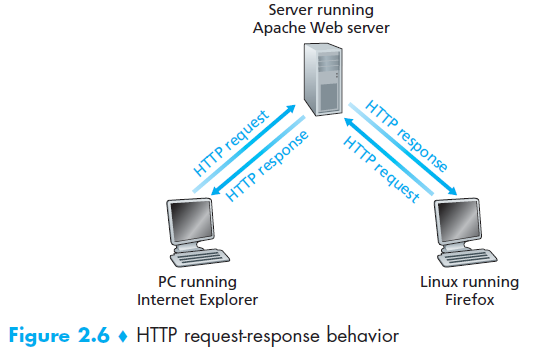
HTTP是用TCP作为传输层协议,HTTP client先与sever建立一个TCP connection ,当connection完成,浏览器和服务器进程就通过socket interface用TCP通信 。HTTP把消息送入到socket interface中,消息就脱离了client的控制而由TCP控制,由于TCP提供可靠地传输服务,所以我们就不用考虑和担心它是怎么处理信息的丢失和顺序问题 ,这也就体现了分层架构的好处,那些工作是较低层协议的工作,在这里,准确的说,是TCP的工作。
因为HTTP服务器不会保留clients的任何信息,所以如果我们连续请求两次同一个对象,它就会回复两次,因此,HTTP被称为stateless protocol,
2.2.2 Non-Persistent and Persistent Connections
在网络应用中 ,client和server可能不间断的通信,也可能是周期性的,还可能是断断续续的,由于这些交流是在TCP协议之上发生的,那么就得考虑是不是得为每对客户-服务器都建立独立的TCP连接呢,或者是都用同一个TCP连接?前一个方法是non-persistent connection ,后一种方法是用了persistent connection ,虽然HTTP默认是用persistent connection,但HTTP clients和server可以被设置成用non-persistent connection 。
HTTP with Non-Persistent Connections
现在我们来从头到尾看一下用non-persistent connection方法server和client传输Web page的步骤,我们假设这个页面有一个base HTML file和十个JPEG图片,这11个对象存储在同一个服务器上,再假设base HTML file的URL是
http://www.someSchool.edu/someDepartment/home.index
然后将会发生什么呢?
1).HTTP client端的进程从80端口 对www.someSchool.edu服务器发起一个TCP连接,80端口是HTTP协议的默认端口 ,为关联TCP connection,client和server方都会有一个socket。
2).HTTP client通过socket向服务器发送一个HTTP request message ,请求消息包含有path name ,即/someDepartment/home.index
3).HTTP server从它的socket收到request ,从它的内存中取出对象/someDepartment/home.index,把这个对象封装进一个HTTP response message,然后通过它的socket把request message发送给client
4).HTTP server 进程通知TCP关闭TCP connection (但是TCP得确认client已经完整无缺的收到response message才会关闭连接)
5).HTTP client收到response message,然后TCP连接停止,这个message显示被封装的对象时一个HTML file,之后client从response message中提取出这个HTML file,然后检测这个HTML file并且找出那十张图片的引用 。
6).为每一张JPEG图片的引用不断重复前四步,
当浏览器收到Web页面后,就在界面上显示给用户,可能不同的浏览器解析Web页面的方式会有些不同,但是这与HTTP协议没有关系 ,HTTP的RFC只定义了在client HTTP program和server HTTP program间通信的协议。
上面的步骤展示的是non-persistent连接,每当服务器发出对象后TCP连接就会关闭,不会为另外的对象停留,说明每个TCP连接只是传输一个请求和一个回复,因此,在这个例子中,但用户请求这个Web页面之后,11个TCP连接需要建立。
上边的描述中我们故意模糊了一个问题,就是那十张图片是顺序的建立TCP连接还是平行的建立TCP连接,事实上 ,我们可以设置平行连接的条数,默认一般是5到10条。
继续之前,我们要做个总共用时的估算,我们定义round-trip time(RTT)来表示一个数据包从client到server然后再返回的时间 ,RTT包括了中间路由和交换机处的传输延迟和排队延迟 ,还有处理延迟,
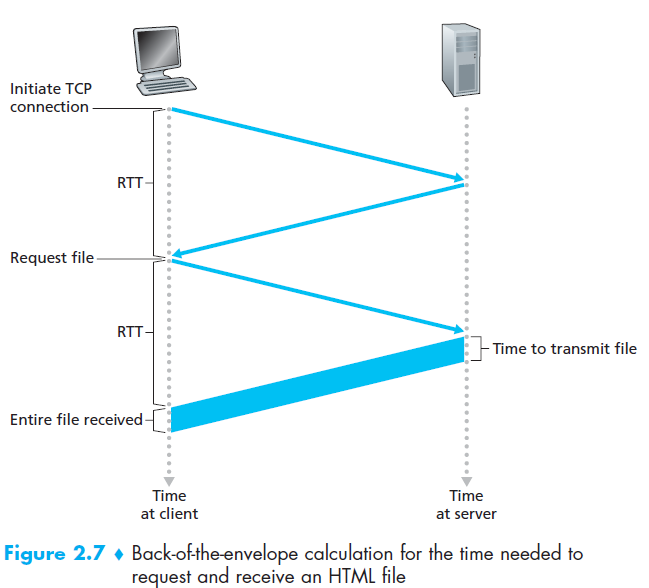
上图显示了从点击一个超链接开始所发生的事,包括一个“three-way handshake”,这个握手的前两个部分消耗一个RTT,然后握手的第三部分会连同一个HTTP请求一起通过TCP连接发送,server收到之后,通过TCP连接回复给client一个HTML file,这两次又消耗掉另一个RTT,所以这整个过程消耗两个RTT .
HTTP with Persistent Connections
non-persistent连接有些缺点,首先每次请求都得新建TCP连接,这样每个连接建立都得TCP分配缓存而且client和server都得keep TCP 变量,这会给Web server很大的负担,因为它可能得同时为成千的用户提供服务,其次,正如我们刚刚所讲,每个object都将会有两个RTT的延迟——一个建立TCP连接,一个请求和回复。
用persistent连接时,服务器发送回复后会保持TCP连接,之后在同个client和这个服务器间的请求会通过这个连接传输,特别的,上边的例子,整个Web page都可以通过一个TCP连接传输 ,更多的,储存在同个服务器上的其他的Web page也可以通过这个连接来传输,,这些请求可以一个接一个的发送,不用等待,服务器在接收到这些请求后也会一个接一个的回复,HTTP默认是使用persistent connection ,服务器会在连接在固定一段时间内没人使用的情况下将其关闭。
2.2.3 HTTP Message Format
HTTP的RFC里定义了HTTP message的格式 ,这里有两种HTTP messages ,request message和response message :
HTTP Request Message


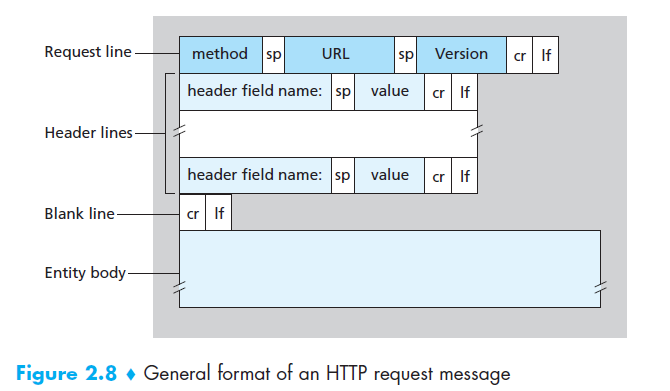
通过这个简单的request message我们可以学习很多 ,首先看到这个message是用普通的ASCII文本写的,所以通常能熟练使用电脑的人能看懂,其次,我们看到这个message有五行,each followed by a carriage return and a line feed ,The last line is followed by an additional carriage return and line feed.虽然这个message之后五行,但是request message可以有很多汗或者只有一行,
HTTP request message的第一行叫做request line ,之后的行被称为header lines ,request line有三个部分:the method field ,the URL field ,the HTTP version field 。method field可以有几个不同的量 ,包括GET, POST ,HEAD ,PUT ,DELETE .大部分的HTTP request message用GET方法,GET方法用来向服务器请求objects ,被请求object的URL放在URL field ,In this example, the browser is requesting the object /somedir/page.html. The version is self-explanatory; in this example, the browser implements version HTTP/1.1.
现在我们再看一下header lines ,其中Host:www.someSchool.edu指出object存储的主机,由于这里已经有了TCP连接,也许你会认为这个header line是没必要的,但是,我们再之后的2.2.5节会看到,Web proxy caches需要这其中的信息,通过提供Connection:close ,浏览器告知服务器它不想用persistent connection,浏览器想让服务器发送完被请求的object之后就将connection关闭,User-agent:这行指明了user agent ,就是向服务器发送请求的浏览器的类型,这里是Mozilla/5.0,是个火狐浏览器 ,这行很有用,因为服务器可以向不同类型的user agent发送同一个object的不同版本(所有这些版本都是通过同一个URL进行寻址) ,最后,Accept-language:行声明用户更偏爱收到一个法语版本的object ,如果法语版本存在的话,如果没有,服务器会发送默认版本,Accept-language行只是HTTP种很多content negotiation headers中的一个。
看完示例后,下面是request message的通用格式 ,你可能已经发现了entity body ,在GET方法中,它是空的,但是再POST方法中有用,当用户填写一个表单的时候HTTP client就会用POST方法,举个栗子,当用户为搜索引擎提供了搜索的关键词,用POST message,用户仍然是从服务器请求一个Web page,但是是Web page的特定内容 ,这些内容决定于用户在表中填入的东西。所以当method field是POST方法的时候,entity body 里就是用户填入表中的内容 。
我们需要说明带有表单的请求并不是都要用POST方法,而是,HTML表单经通常用GET方法,并把需要输入的数据放到被请求的URL中,举个栗子,如果一个表单用GET方法,又两个部分,放入两个部分的分别是monkeys和bananas,然后URL就会变成这样 www.somesite.com/animalsearch?monkeys&bananas.在你每天的Web浏览中,你大概见过这样格式的扩张后的URL 。
HEAD方法和GET相似,当服务器收到个HEAD方法的请求,服务器回复一个HTTP message但是省去被请求的object ,这种方法通常被开发者用来调试 。PUT方法通常连同Web publishing tools一起使用,这种方法也被需要上传object到服务器的应用使用 ,DELETE方法允许用户或者应用删除Web server上的object,
HTTP Response Message
下图是刚刚那么栗子的response

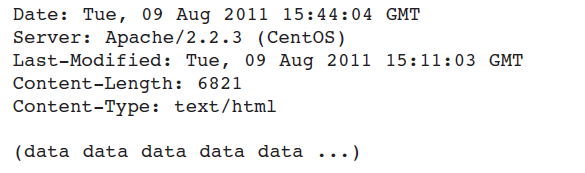
这个message包含三个部分,一个status line,六个header line,还有entity body ,entity body是message的肉——它包含了被请求的object(用最后一行全是data来表示 ) ,status line有三个部分:protocol version field,a status code ,a corresponding status message ,这个例子中,status line说明服务器使用的是HTTP/1.1并且所有事情OK(就是说,服务器已经找到并发送了被请求的object) 。
我们看一下header lines,服务器用Connection:close告知client发送完message之后关闭掉TCP connection,Date :行显示HTTP response生成并被发送的时间和日期,说明下这个时间不是object生成或者最后一次被修改的时间,是服务器从它的文件系统中找到这个object并把这个object放入response message中并发送的时间,Server:行显示message是被Apache Web server生成的,可以类比上边请求信息中的User-agent :行,List-Modified:行对于object的储存是很重要的,不管是在本地client还是在network cache server(也叫做proxy server),Content-Length:行显示被发送的object的总字节数,,Content-Tyoe:行显示在entity body中的object是一个HTML文档(object类型通常是Content-Type声明的,而不是文件的扩展名),
同样的,看完栗子,我们来看一下response message的通用格式 ,


浏览器是怎么确定在request message中包含哪些header lines?服务器是怎么确定在response message中包含哪些header lines?
A browser will generate header lines as a function of the browser type
and version (for example, an HTTP/1.0 browser will not generate any 1.1 header lines), the user configuration of the browser (for example, preferred language), and whether the browser currently has a cached, but possibly out-of-date, version of the object. Web servers behave similarly: There are different products, versions, and configurations, all of which influence which header lines are included in response messages.














 8725
8725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}