







2.6 Peer-to-Peer Applications
这章的application讨论到这里,我们已经看了Web,email,DNS,所有这些都要依赖always-on infrastructure servers,回想我们提到的P2P架构,几乎不依赖always-on infrastructure servers,peers可以直接与彼此交流,这些peers不是服务提供商的,而是用户的笔记本或台机
这一节我们要介绍两个尤其适合P2P架构的应用,第一个是file distribution,这个应用是从一个源把文件发送给很多peers,这个应用使我们开始研究P2P架构的很好的开始,因为它清晰地暴露了P2P架构自扩展(self-scalability)的特性,作为file distribution的一个更具体的例子,我们会讲下BitTorrent系统,我们要讲的第二个P2P应用是database distributed over a large community of peers,对于这种应用,我们会探究下the concept of a DHT(Distributed Hash Table)
2.6.1 P2P File Distribution
我们先从client-server file distribution开始,这种架构中,server必须向每一个peer发送文件——给服务器造成极大的压力并消耗掉非常大的服务器带宽,在P2P架构中,任何一个peer都可以把它已经接受到的文件中的任何部分再次发送给其他的peer,因此可以在分发环节帮助服务器缓解压力
Scalability of P2P Architecture
为了P2P架构和client-server架构做个比较,并且描述下P2P固有的self-scalability,我们现在看一个简单的模型——让每个架构类型发送一个相同的文件到固定数量的peers,
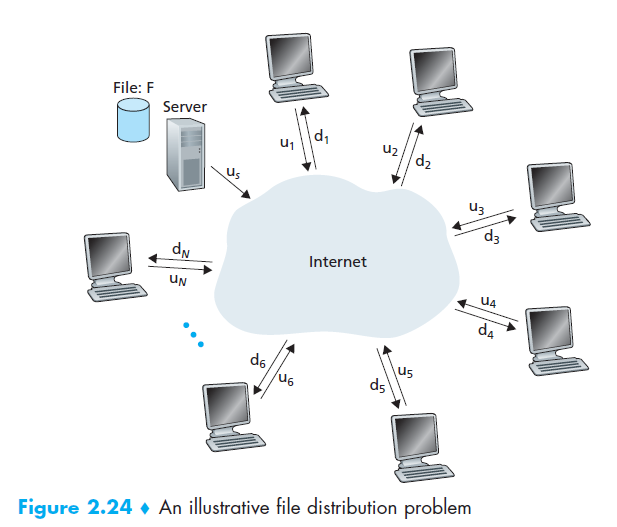
通过上图,我们先看下client-server架构所用时间,
*服务器必须把文件传输给N个peer,因此传输总量是NF bits,则时间至少是NF/us,
*假设dm是所有peers中最小的下载速率,速率最小的peer不可能在F/dm时间内获得所有的F bits,所以至少的时间就是F/dm
然后把上边加一起,总时间Dcs≥max{ NF/us,F/dm},如果N增加的话,这个是时间值是随着它线性增加的
现在再看下P2P架构所用的时间,这种架构peers可以用自己的上传速率来传输自己得到的部分给其他计算机,所以可以协助server进行分发,因此计算它所用的时间也更复杂
*在传输开始时,只有server中有这个文件,为了能让这个文件进入到peers中,服务器必须把这个文件中的每个bit都至少传输过它的线路一遍,因此,最少的时间是F/us(与CS架构不同,P2P架构可能发送过一遍的文件不需要再发送一遍)
*同CS架构一样,下载速率最低的计算机至少要F/dm时间才能得到所有的F bit,所以最小的distribution time至少是F/dm
*最后,总的上传速率是服务器的上传速率加上所有的计算机的上传速率,系统必须向每个peer传输F bits,总的是NF,最少的distribution time是NF/(us+u1,+u2+u3+…+un)
把上边的时间放在一起,
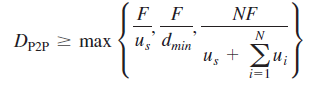
下图是两者的图像对比,
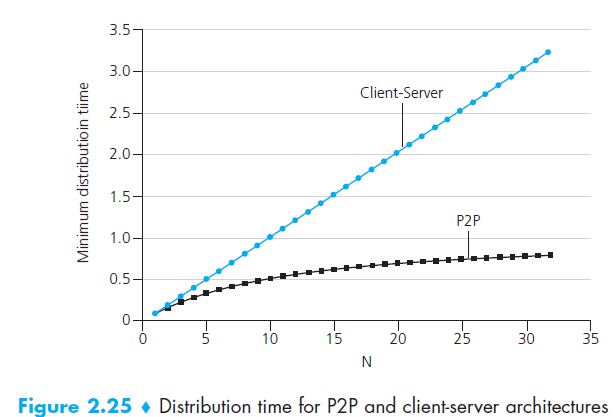
BitTorrent
BitTorrent is a popular P2P protocol for file distribution,在它的语言中,很多peers都参与一个具体文件的传输叫做torrent,洪流中的计算机从彼此那里下载相同大小的chunks,一般256 KB,当一个计算机先加入到torrent时,她没有chunk,然后随时间它不断有越来越多的chunks,而且在它下载chunk的时候它也会把自己有的chunk上传给其他计算机,当一个peer收到了这整个文件的时候,它可能会离开也可能会继续在洪流中把chunks分发给其他计算机,而且,任何时间都可能有任何计算机带着一部分或者全部整个文件离开,也可能会有再次加入
由于这是个很复杂的协议和系统,所以我们只讲它最重要的机能,多有的torrent都有一个infrastructure node叫做tracker,当一个计算机加入到洪流中,它会向tracker注册并且周期性的告知自己还在洪流中,这种条件下,tracker就可以追踪洪流中的peers,
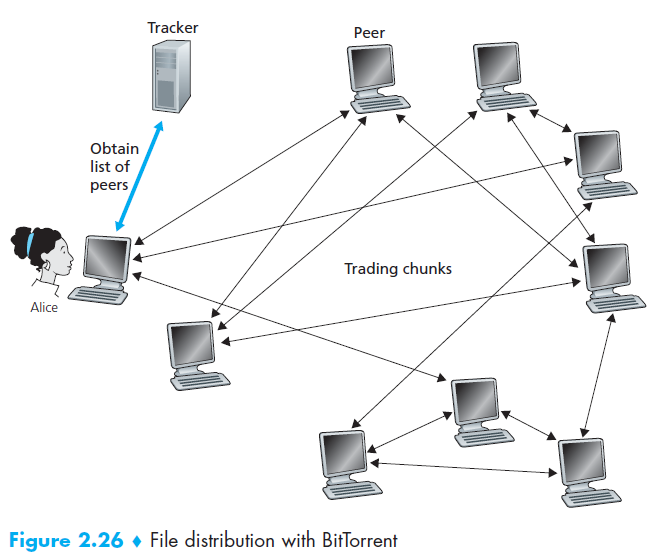
当Alice第一次加入到这个洪流中,tracker就会随机选出洪流中的一部分计算机并把这些计算机的IP地址发送给Alice,然后Alice就尝试与这些被提供的计算机建立TCP连接,我们把成功与Alice建立连接的计算机叫做neighboring peers,图中只显示了三个neighboring peers,但实际上会更多,并且随着时间可能有一些计算机会离开,而其他的计算机会加入,这样总数也就是随时间波动的
在任何时刻,每个peer都有文件的一个子集,不同的计算机可能有不同的子集,周期性的,Alice会向neighboring peers请求它们有的部分,如果Alice有L个neighbor,那么就有L个chunks的列表,然后Alice就会发出请求来获得她现在没有的部分
所以在任何时刻,Alice都会有一部分chunks并且知道她的邻居们有什么,有了这些信息,Alice就需要做两个重要的决定,一是先请求哪个chunks,二是要先响应哪个请求,第一个问题,Alice用rarest first技术,就是先请求她没有,并且在邻居中也是最稀少的chunk,这样这个chunk会在洪流中迅速多起来,这个技术也可以平衡洪流中各种chunk的数量
为确定要响应哪个请求,BitTorrent用了个聪明的交易算法,就是Alice把优先级给最近提供给自己数据速率最高的邻居,对于她的每个邻居,Alice都不停的测量他们传输给自己数据的速率并决定出四个速率最高的计算机,然后她就发送给这四个计算机chunks就像回报,这种测量10s一次,测试速率然后调换最高速率的四个计算机,在BitTorrent的术语中,这四个计算机叫做unchoked,重要的,每30s,她也会随机的选择一个neighbor然后向它发送chunks,我们把随机选中的这个叫做Bob,在BitTorrent的术语中,Bob这种就叫做optimistically unchoked,由于Alice会向Bob发送chunks,所以速率足够高的话就会进入Bob那四个要发送信息的计算机中,如果他们两个的传输速率都到了彼此满意,那么就会成为彼此的unchoked,知道其中一个找到更适合的计算机,The effect is that peers capable of uploading at compatible rates tend to find each other.这个随机选择一个传输的机制也让新来的计算机可以有机会得到chunks,所以他们有东西可以来交易,所有出去上边我们说过的五个之外的计算机都叫做choked,就是,他们不会从Alice那里得到任何的chunks
上边的算法常被称作tit-for-tat(一报还一报),很多P2P live streaming 应用受到BitTOrrent的启发,比如PPLive,ppstream
2.6.2 Distributed Hash Tables(DHTs)
这一节我们要看如何在一个P2P网络中实现一个简单的数据库,先让我们想象一个只有(key,value)对的centralized version of this database,可以用key来查询value,做一个这种数据库就可以直接用CS架构,把所有的这些对都存在一个中心服务器中,但是,我们这一节讨论怎么建立一个分布式,P2P version的数据库,要在很多机器上存储这些对,在P2P系统中,每个计算机只存储其中的一小部分。我们允许每个计算机用key来查询分布式数据库,这个数据库首先确定哪台计算机上有相匹配的对,然后返回这个对给那个发出请求的计算机,而且计算机还被允许向数据库中插入对,这种分布式数据库叫做distributed hash table(DHT)
在描述怎么建立一个DHT之前,先来看一个P2P file sharing为背景的DHT服务,在这里,key就是内容的名字,value是有这个内容的计算机的IP,所以如果Bob和Charlie都有一个最新的Linux,然后DHT数据库中就会包含两个对(Linux,IP-bob),(Linux,IP-charlie),更准确的,因为DHT数据库是分布式的,所以有些peer,就叫Dave吧,要对Linux这个key负责,并且存储着Linux的对,现在想象Alice想要得到个Linux,那么她得先知道哪个计算机有这个内容,然后他就用Linux在DHT数据库中查询,DHT确认Dave负责Linux,然后DHT与Dave连接,获得这两个对并把它们发送给Alice,然后Alice就可以从其中任何一个下载
我们回到创建DHT问题上,一个简单的方法是把所有的键值对都分配给所有的peers,并且每个peer都有一张参与DHT的计算机的IP列表,这种设计中,查询方需要把query发送给每个peer,有所要内容的peer进行回复,这个方法是没法规模化的,因为它不但需要每个计算机知道其他计算机的IP地址而且每个query都要发送给每个计算机
现在我们介绍一种优雅的方法,为此,我们为每个peer分配一个标识符,就是0到2的n次方减一的整数,说明每个这种标识符都是可以用一个n-bit表示,我们同样要求每个key都是相同范围内的整数,我们看到前边提到的key都不是整数,那么我们要用hash函数来把每个key都分配一个这个范围内的整数,hash函数是个many-to-one函数,就是不同的输入能有相同的输出,但是几率非常小,hash函数在每个计算机系统中都有,从这以后,我们再提到key,我们指的是那个key的hash值,
现在看下怎么在DHT中存储键值对,这里的核心问题是定义一个规则把key分配给peer,考虑到每个peer都有一个整数的标识符,而且key也有同样范围内的标识符,一个自然的想法就是把每个对分配给标识符最接近的peer,为执行这个计划,我们得定义什么是最接近,为了方便,我们把最接近的peer定义为key的最接近的前驱,我们看个例子,假设n=4,则所有的标识符范围(0,15),系统中有八个peer,标识符分别为 1,3,4,5,8,10,12,15,我们想把(11,Johnny Wu)这个对存入其中一个peer,用我们的最接近规则,那么应该存在12中,(为完善我们的规则,如果key标识符正好和peer相同没那么就存在相同的那个peer,we use a modulo-2的n次方 convention,storing the (key, value) pair in the peer with the smallest identifier.)
我们假设Alice想把一个对存入DHT,理论上,她先决定哪个peer和key的标识符是最接近的,然后发送个消息到那个peer,指示peer存储键值对,但是她是怎么确认哪个是最近的呢?如果Alice追踪所有的计算机,她当然可以确定,但是这种方法对于大规模的系统是不现实的
Circular DHT
为了解决这个规模问题,我们把peers组织为一个环形,这种结构中,每个peer只追踪它的直接前驱和直接后继,图中这个例子把n设为4,和上边的例子一样的八个peer,每个peer只知道它的直接前驱和直接后继,这种环形排列是overlay network的一种特例,在overlay network中,peers组成抽象逻辑网络在物理链路,路由,主机组成的underlay computer network之上,重叠网络中的链路不是物理连接,只是简单的peer间的虚拟连接,(a)图中有八个peer和八个overlay links,(b)图中有八个peer和16个overlay links,A single overlay link typically uses many physical links and physical routers in the underlay network.
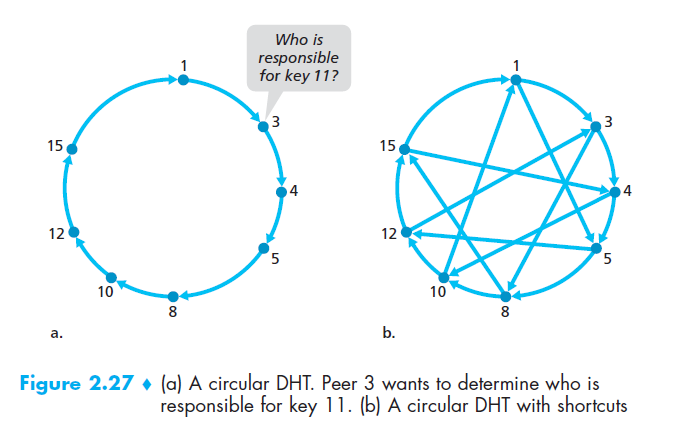
由a图,现在假设peer3想要确定那个peer对key11负责,用这个circular overlay,peer3发送一个顺时针的消息,当一个peer接收到这个消息,由于它知道它的直接前驱和直接后继的标识符,它可以确定他们是不是最接近,如果一个peer对这个key不负责,它就把信息发送给它的直接后继,举例,当peer4收到key11的信息,它确认自己不对此负责(因为它的后继更接近11),所以它要发送给peer5,这个过程会一直持续到消息到达peer12,此时,peer12发送一个消息到peer3,说明它对key11负责
circular DHT提供了一种解决规模问题的优雅方法,但是这种方法又会产生一个新问题,虽然每个peer只需要知道它的前驱和后继,但是消息要在整个环中传递,平均传递n/2次
因此,在设计DHT时,我们需要在每个peer需要追踪的neighbors和单个查询中需要发送的信息个数两者权衡,好在我们可以在这个基础上再改进,一种方法是用环形最基础,再加上shortcuts,这时peer不只追踪它的直接前驱和直接后继,还有相对数量少的散落在环中的peer,图(b)所示,shortcuts用来加快query的传输,当一个peer收到查询消息后,它发送给更接近的neighbor,因此,在图(b)中,当peer4收到查询key11的信息,它确认更接近的是10,然后把消息传递给10,很明显,shortcuts显著的减少了查询所需要发送消息的数量
Peer Churm
在P2P系统中,peer可以来去都不用声明,因此,设计DHT的时候,我们也要考虑到这种波动,我们再看图(a),为了掌控peer的波动,我们需要每个peer追踪它的第一和第二后继,例如,peer4要追踪5和8,我们还需要peer周期性的核实它的两个后继还在,现在我们看看一个peer突然离开时DHT是怎么维持的,假设peer5离开,这时,peer4和3发现5离开了,因为它不再回复ping消息了,因此peer4和3得更新它们的后继状态信息,我们看下peer4是怎么更新状态
1.peer4把它的第一后继5用第二后继8代替
2.peer4从它新的第一后继8获得8的直接后继(10)的IP和标识符,然后peer4把10作为它的第二后继
说完peer离开时的情况,现在看有peer想要加入DHT的情况,假设peer13想加入,加入时,它只知道peer1的存在,然后它会向peer1发送消息,“what’s will be 13’s predecessor and successor?”这个消息会在DHT中传递直到peer12,who realizes that it will be 13’s predecessor and that its current successor, peer 15, will become 13’s successor.Next, peer 12 sends this predecessor and successor information to peer 13. Peer 13 can now join
the DHT by making peer 15 its successor and by notifying peer 12 that it should change its immediate successor to 13.














 4861
4861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









