







简介
hive on spark安装,hive是基于hadoop的数据仓库,hdfs为hive存储空间,mapreduce为hive的sql计算引擎。但是由于mapreduce很多计算过程都要经过硬盘读写等劣势,和spark等计算引擎相比,无论是计算速度,还是计算灵活度上都有很多劣势,这也导致了hive on mapreduce计算速度并不是令人很满意。本篇来讲下hive on spark,将hive的计算引擎替换为spark,速度将有很大的提升.
环境
centos6
hadoop2.6集群,需要hdfs、yarn
hive2.0.0
spark1.5源码
maven3.3(自行安装)
jdk1.7(自行安装)
scala2.10(自行安装)
安装配置
注意:安装时需要注意几个组件的安装节点。
例如我的机器环境
node21
hdfs:namenode,secondarynode,datanode
yarn:resourcemanager,nodemanager
hive
spark
node22
hdfs:datanode
yarn:nodemanager
node23
hdfs:datanode
yarn:nodemanager
以上hadoop中的hdfs和yarn安装后(我的机器不多将主节点也当datanode和nodemanager了)。
hive和spark必须在一个节点上。因为hive要用spark客户端来启动服务。
hive和spark必须要在hadoop的其中一个节点上。因为hive是一定要依赖hdfs的,hive启动的时候要拿环境变量HADOOP_HOME去拿hdfs相关文件,根据spark的启动模式yarn、standalone、mesos来选择是否去拿yarn配置文件,本文用的yarn的启动模式,其它几种模式大家也可以试试。
如果用yarn部署模式不用每台机器都部署hive和spark,hive只是单个服务,不用部署多个,他只存逻辑表的元信息,接收sql任务,翻译成相应的spark任务并执行。用yarn部署模式的话,hive启动spark任务的时候会将spark-assmebly包上传到hdfs上,yarn根据哪些节点启动了spark任务,这些节点自动去hdfs上下载,所以不用每台机器都部署spark,部署了yarn启动时也不用。
下面的安装过程是先安装hadoop集群(hdfs和yarn),然后在namenode上面部署了spark和hive并配置相关配置文件。
安装参考官网
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
1.hadoop
1.1.hadoop2.6集群安装略
参考 http://blog.csdn.net/dante_003/article/details/54943774
2.spark
2.1.spark编译
预编译好的spark是不能部署hive on spark的,因为spark里面默认打入了hive的包(sparksql以及sqlcontext这些都是基于hive做的),spark里面的hive版本和我们安装的hive版本不一样,而且spark里面的hive是被修改过的,所以要将spark里面的hive包给去掉(同理,去掉hive的spark客户端就不能运行sparksql和sqlcontext了),否则执行时会报错。
从github的地址上下载spark的源码https://github.com/apache/spark/tree/branch-1.5
我从spark官网上下载的1.5源码编译报错
下载完成后进入源码根目录执行下面命令,编译时需要用到scala2.10(scala版本要对应,有的反应版本不对编译错误或编译出来的有问题)、jdk1.7、maven3.3
2.0版本之前编译
./make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.6,parquet-provided"
2.0版本之后编译
./dev/make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.7,parquet-provided"编译刚开始应该是在扫描文件,会等几分钟才开始编译,不要认为编译失败卡住了,耐心等待,整个编译过程大约几个小时,主要是要下很多maven包。有资源的朋友可以用vpn或者在aws的ec2上编译。
当出现build success时,说明编译成功,切在根目录里面多出了一个tar.gz包spark-1.5.3-SNAPSHOT-bin-hadoop2-without-hive.tgz
2.2spark部署
将上一部编译成功的tar.gz包解压到你安装的文件夹。
tar xzvf spark-1.5.3-SNAPSHOT-bin-hadoop2-without-hive.tgz -C /opt
cd /opt
mv spark-1.5.3-SNAPSHOT-bin-hadoop2-without-hive spark配置环境变量
export SPARK_HOME=/opt/spark
source /etc/profile2.3spark配置
- spark-env.sh
export JAVA_HOME=/opt/java/jdk
export SCALA_HOME=/opt/scala
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_LAUNCH_WITH_SCALA=0
export SPARK_WORKER_MEMORY=1g
export SPARK_DRIVER_MEMORY=1g
export SPARK_MASTER_IP=192.168.1.21
export SPARK_LIBRARY_PATH=/opt/spark/lib
export SPARK_MASTER_WEBUI_PORT=18080
export SPARK_WORKER_DIR=/opt/spark/work
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_PORT=7078
##下面这个参数不配置会说找不到相关jar包
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/bin/hadoop classpath)- spark-defaults.conf
配置spark启动的默认参数
spark.master yarn-cluster
spark.home /opt/spark
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.memory 1g
spark.driver.memory 1g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
3.hive
3.1.hive安装配置略
参考http://blog.csdn.net/dante_003/article/details/54944319
3.2.配置
拷贝spark包到hive下面
拷贝spark/lib/spark-assembly-1.5.3-SNAPSHOT-hadoop2.6.0.jar 到 hive/lib下面hive-site.xml
<!-- 元数据相关,存储在mysql,没有mysql驱动的要把mysql驱动拷贝到hive的lib下面 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.82:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<!--spark -->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>hive.enable.spark.execution.engine</name>
<value>true</value>
</property>
<property>
<name>spark.home</name>
<value>/opt/spark</value>
</property>
<!--sparkcontext -->
<property>
<name>spark.master</name>
<value>yarn-cluster</value>
</property>
<property>
<name>spark.serializer</name>
<value>org.apache.spark.serializer.KryoSerializer</value>
</property>
<property>
<name>spark.executor.memeory</name>
<value>1g</value>
</property>
<property>
<name>spark.driver.memeory</name>
<value>1g</value>
</property>
<property>
<name>spark.executor.cores</name>
<value>2</value>
</property>
<property>
<name>spark.executor.instances</name>
<value>4</value>
</property>
<property>
<name>spark.app.name</name>
<value>myInceptor</value>
</property>
<!--事务相关 -->
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
<property>
<name>spark.executor.extraJavaOptions</name>
<value>-XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
</value>
</property>
<!--其它 -->
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>启动
启动hadoop
hadoop/sbin/start-all.sh
查看相关web页面,保证hdfs和yarn都启动。
spark
spark不用启动,和hive在一个节点上就可以
启动hive
(也可以启动hiveserver2 通过beeline进入到hive,输入sql执行任务,启动hiveserver2参考http://blog.csdn.net/dante_003/article/details/54944319)
bin/hive
进入命令行模式,运行统计数量的命令
select count(*) from test;
第一次运行会比较慢,因为第一次hive要启动spark集群。
在yarn的页面里面可以看到hive在yarn上面启动了一个spark长服务
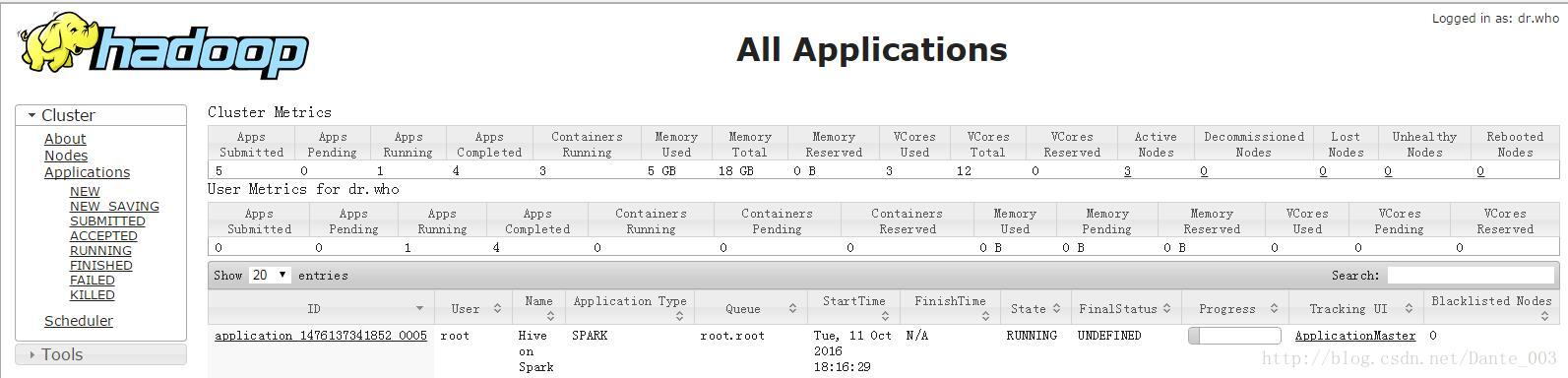
点击右侧的applicationmaster可以看到spark集群的信息
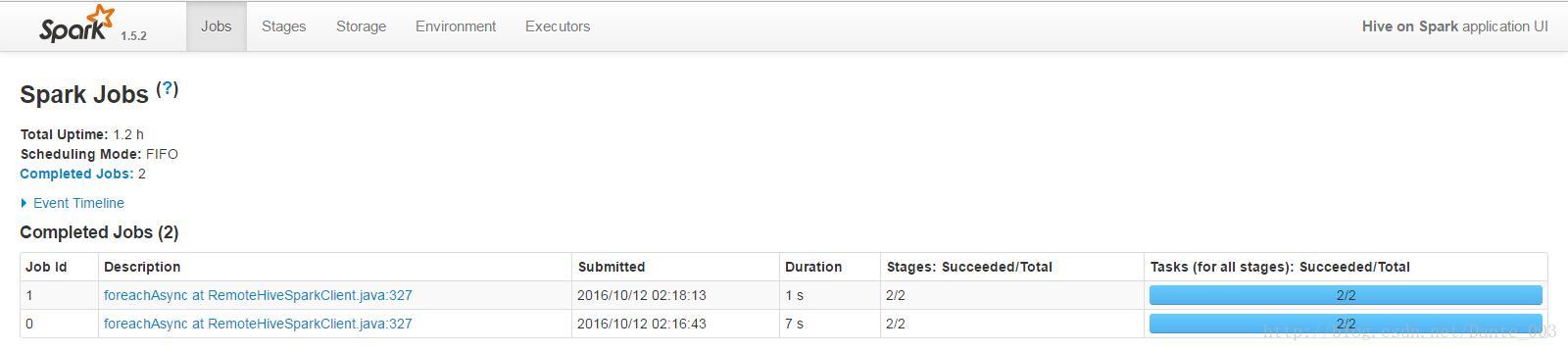
以上可以在hive里面运行其它sql,查看spark集群的执行情况。
hive on spark成功了。














 1433
1433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









