







TensorFlow实现机器学习的“Hello World”
上一篇博客我们已经说了TensorFlow大概怎么使用,这次来说说机器学习中特别经典的案例,也相当于是机器学习的“Hello World”,他就是Mnist手写数字识别,也就是通过训练机器让他能看懂手写的阿拉伯数字。
极客网其实已经把完整的教程都写出来了,但里面还是有些坑的,所以我会把我遇到的坑给大家说一下。
极客网Mnist教程链接:http://wiki.jikexueyuan.com/project/tensorflow-zh/tutorials/mnist_beginners.html
惯例先说一下我的系统环境和软件版本,这个不说真的会有很多坑,因为不同版本的有很多API都不一样
1.系统是ubuntu 16.04 LTS
2.我用的是sublime text3搭建的Python开发环境
3.Python用的是3.5
4.TensorFlow用的是0.12.0,only cpu
一.Mnist数据集准备
- 首先要进行机器训练就必须要有训练的数据,那我们今天的就是Mnist的数据集,那极客学院已经帮我们把这份数据都打包好了,只要在Python里面运行以下代码就可以,复制进去可以直接执行一次。
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import tempfile
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets- 然后你要使用这份数据按照以下代码导入就可以(极客学院的教程里面的代码导入进去会无法执行,原因未知,所以使用我下面这段代码吧)
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)- 那到此你就已经准备好了数据集
下载下来的数据集被分成两部分:60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。详细的分析建议看极客网Mnist教程。
二、构建TensorFlow模型
A.构建模型
首先我们要使用TensorFlow,就需要导入它:
import tensorflow as tf我们通过操作符号变量来描述这些可交互的操作单元,简单的说就是需要一个输入值:
x = tf.placeholder(tf.float32, [None, 784])- x不是一个特定的值,而是一个占位符placeholder,我们在TensorFlow运行计算时输入这个值。我们希望能够输入任意数量的MNIST图像,每一张图展平成784维的向量。我们用2维的浮点数张量来表示这些图,这个张量的形状是[None,784 ]。(这里的None表示此张量的第一个维度可以是任何长度的。)
在构建机器学习神经元网络的时候,有两个特别重要的值就是权重值和偏置量,TensorFlow有一个很好的方法来表示它们,关于这两个参数可以自行Google
W = tf.Variable(tf.zeros([784,10])) #权重值
b = tf.Variable(tf.zeros([10])) #偏置量- 我们赋予tf.Variable不同的初值来创建不同的Variable:在这里,我们都用全为零的张量来初始化W和b。因为我们要学习W和b的值,它们的初值可以随意设置。
注意,W的维度是[784,10],因为我们想要用784维的图片向量乘以它以得到一个10维的证据值向量,每一位对应不同数字类。b的形状是[10],所以我们可以直接把它加到输出上面。
B.实现模型
y = tf.nn.softmax(tf.matmul(x,W) + b)- 首先,我们用tf.matmul(X,W)表示x乘以W,对应之前等式里面的,这里x是一个2维张量拥有多个输入。然后再加上b,把和输入到tf.nn.softmax函数里面。
- softmax是一个回归模型,它用来描述其他各种数值计算,从机器学习模型对物理学模拟仿真模型,简单的说就是建模,把输入一个图片信息,输出他的结果,不同的图片信息会有不同的结果,这些结果具有一定的规律性,根据这个规律性,我们就可以反推输入的是什么图片。
C.训练模型
为了训练我们的模型,我们首先需要定义一个指标来评估这个模型是好的。但在机器学习,我们通常定义指标来表示一个模型是坏的,这个指标称为成本(cost)或损失(loss),然后尽量最小化这个指标。但是,这两种方式是相同的。这时就有一个非常漂亮的成本函数是“交叉熵”(cross-entropy)。交叉熵是用来衡量我们的预测用于描述真相的低效性,也就是他可以衡量我们的模型到底有多坏。
- 为了计算交叉熵,我们首先需要添加一个新的占位符用于输入正确值:
y_ = tf.placeholder("float", [None,10])- 然后我们可以用以下方法来计算交叉熵:
cross_entropy = -tf.reduce_sum(y_*tf.log(y))- 接着我们构建一个反向传播自动修正参数的方法:
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)这个函数的意思就是我们要求TensorFlow用梯度下降算法(gradient descent algorithm)以0.01的学习速率最小化交叉熵。梯度下降算法(gradient descent algorithm)是一个简单的学习过程,TensorFlow只需将每个变量一点点地往使成本不断降低的方向移动
现在,我们已经设置好了我们的模型。在运行计算之前,我们需要添加一个操作来初始化我们创建的变量:
init = tf.initialize_all_variables()- 接着我们可以在一个Session里面启动我们的模型,并且初始化变量:
sess = tf.Session()
sess.run(init)- 然后开始训练模型,这里我们让模型循环训练1000次!
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})D.评估模型
那么我们的模型性能如何呢?
首先让我们找出那些预测正确的标签。tf.argmax 是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,比如tf.argmax(y,1)返回的是模型对于任一输入x预测到的标签值,而 tf.argmax(y_,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))这行代码会给我们一组布尔值。为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。例如,[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))最后,我们计算所学习到的模型在测试数据集上面的正确率。
print (sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))- 这里有个坑是极客学院没有说到的,如果你的Python版本是Python2的话,直接复制极客网的代码不会有问题,但是你是Python3的话,它的print语法已经变了,变成print (),也就是需要把你要打印的东西放在括号里面,不然会报错!
E.运行结果
那我最终的运行结果是92.06%,比极客学院说的91%稍微好点。
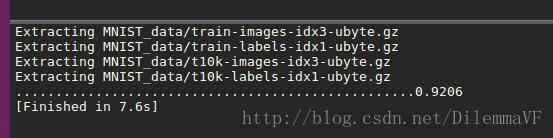
完整代码:
import tensorflow as tf
import sys
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x = tf.placeholder("float", [None, 784])
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x,W) + b)
y_ = tf.placeholder("float", [None,10])
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for i in range(1000):
if i % 20 == 0:
sys.stdout.write('.')
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print (sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))













 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









