







 本文总结了在MySQL中进行大批量数据插入时遇到的问题及解决方案,包括设置innodb_flush_log_at_trx_commit、使用LOAD DATA LOCAL INFILE、调整bulk_insert_buffer_size等方法,以及对InnoDB表的优化策略。实测显示,通过这些优化,插入速度提升了30多倍。同时,文章探讨了字符长度对插入速度的影响,并分析了不同数据量和字段长度下的性能表现。此外,还讨论了集群环境下数据插入的资源利用率和配置选择。
本文总结了在MySQL中进行大批量数据插入时遇到的问题及解决方案,包括设置innodb_flush_log_at_trx_commit、使用LOAD DATA LOCAL INFILE、调整bulk_insert_buffer_size等方法,以及对InnoDB表的优化策略。实测显示,通过这些优化,插入速度提升了30多倍。同时,文章探讨了字符长度对插入速度的影响,并分析了不同数据量和字段长度下的性能表现。此外,还讨论了集群环境下数据插入的资源利用率和配置选择。
最近在做MYSQL大批量数据的测试,就简单总结一下遇到的问题:
首先我是简单的写了一个MYSQL的循环插入数据的SP,具体如下:
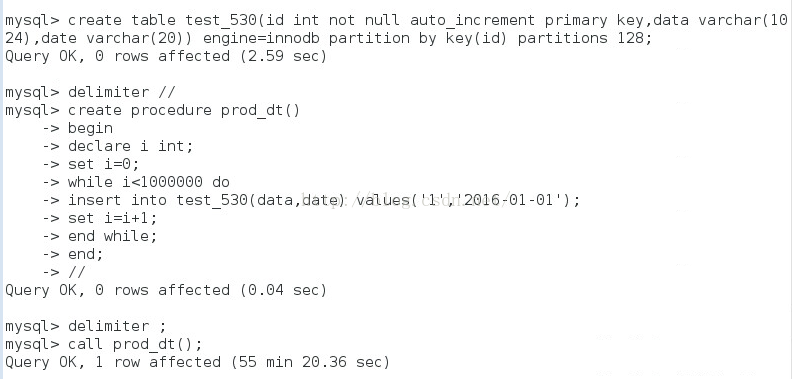
这是插入100W数据的过程和结果,可以看到是换了55min +20S约3320秒(约300rows/s),看到之后我是只崩溃,就在网上查了些提速的方法:
0. 最快的当然是直接 copy 数据库表的数据文件(版本和平台最好要相同或相似);
1. 设置 innodb_flush_log_at_trx_commit = 0 ,相对于 innodb_flush_log_at_trx_commit = 1 可以十分明显的提升导入速度;
2. 使用 load data local infile 提速明显;
3. 修改参数 bulk_insert_buffer_size, 调大批量插入的缓存;
4. 合并多条 insert 为一条: insert into t values(a,b,c), (d,e,f) ,,,
5. 手动使用事物;
当数据量较大时,如上百万甚至上千万记录时,向MySQL数据库中导入数据通常是一个比较费时的过程。通常可以采取以下方法来加速这一过程:
一、对于Myisam类型的表,可以通过以下方式快速的导入大量的数据。 ALTER TABLE tblname DISABLE KEYS; loading the data ALTER TABLE tblname ENABLE KEYS; 这两个命令用来打开或者关闭Myisam表非唯一索引的更新。在导入大量的数据到一个非空的Myisam表时,通过设置这两个命令,可以提高导入的效率。对于导入大量数据到一个空的Myisam表,默认就是先导入数据然后才创建索引的,所以不用进行设置。
二、对于Innodb类型的表,有以下几种方式可以提高导入的效率: ①因为Innodb类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有效的提高导入数据的效率。如果Innodb表没有主键,那么系统会默认创建一个内部列作为主键,所以如果可以给表创建一个主键,将可以利用这个优势提高导入数据的效率。
②在导入数据前执行SET UNIQUE_CHECKS=0,关闭唯一性校验,在导入结束后执行SET UNIQUE_CHECKS=1,恢复唯一性校验,可以提高导入的效率。
③如果应用使用自动提交的方式,建议在导入前执行SET AUTOCOMMIT=0,关闭自动提交,导入结束后再执行SET AUTOCOMMIT=1,打开自动提交,也可以提高导入的效率。
而我创建的是Innodb类型的表,分了128个分区。而我依照以上的方法,设置如下:

插入百万数据的SP如下:
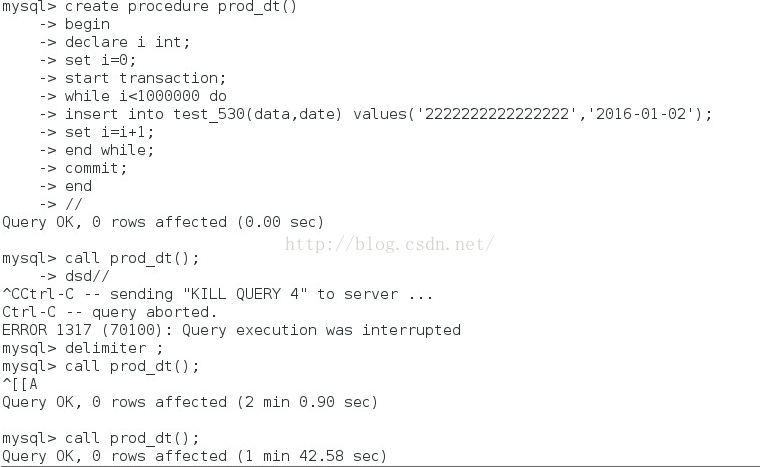
可以明显的看到插入百万数据是100S左右,速度提升了33倍之多。
速度是提升了不少,那就加大插入的数据量,提升10倍,即插入千万的数据量,具体的SP如下:
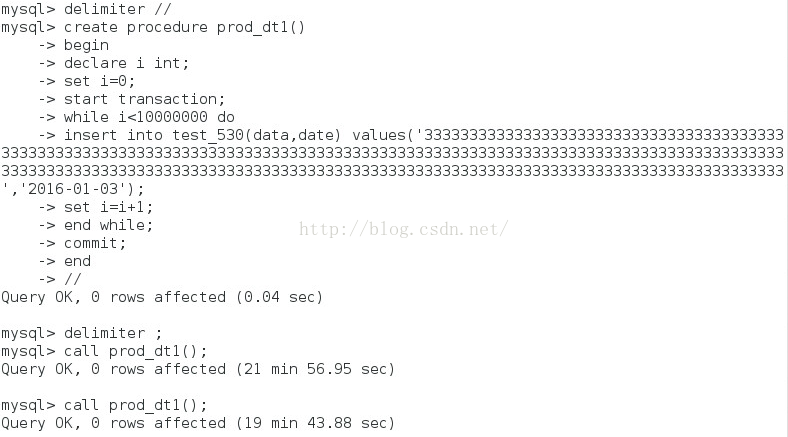
可以看到时间差不多是1200s左右,因为字段加长了,可能也有影响插入的速度。
为了具体验证,就按千万行插入,字段的长度为1000字节,来查看结果,具体的SP和结果如下:
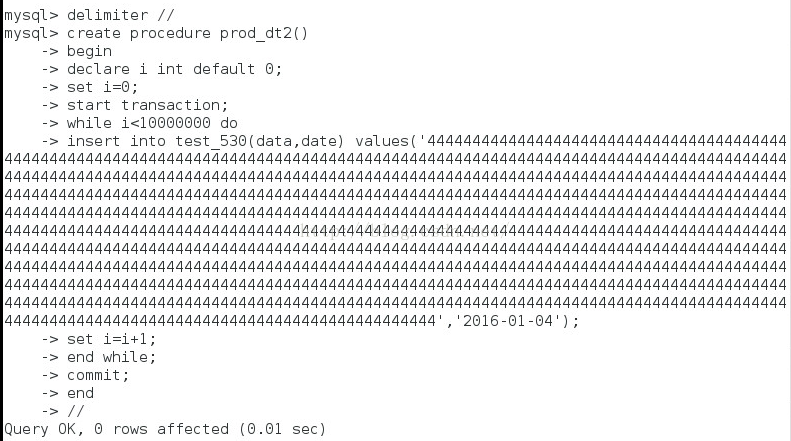

可以看到用时33min 51s月(约2031秒),即(4900row/s),速度下降很多,字符长度看来是用影响的。
varchar字段
字段的限制在字段定义的时候有以下规则:
a) 存储限制
varchar 字段是将实际内容单独存储在聚簇索引之外,内容开头用1到2个字节表示实际长度(长度超过255时需要2个字节),因此最大长度不能超过65535。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











