







我们在阅读PDF文件时,由于内容比较多,一下找不到我们想要查看的内容,这时我们就会使用PDF阅读软件中的查找功能来快速定位到指定的文本。在这篇文章中,我将介绍如何使用C#和免费Spire.PDF组件来实现这一功能。
首先创建一个C#控制台应用程序,在NuGet Package Manager中搜索并安装Free Spire.PDF,如下图所示:
安装后,Free Spire.PDF dll就会自动引用到工程中。下面是实现的具体步骤:
步骤1:加载PDF文档。
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Input.pdf");步骤2:根据关键词查找PDF页面中匹配的文本,并为每个匹配文本设置背景颜色。
PdfTextFind[] AllMatchedText = null;
//遍历页面
foreach (PdfPageBase page in pdf.Pages)
{
//根据关键词查找页面中匹配的文本
AllMatchedText = page.FindText("绣球花").Finds;
foreach (PdfTextFind text in AllMatchedText)
{
//给匹配的文本设置背景颜色
text.ApplyHighLight();
}
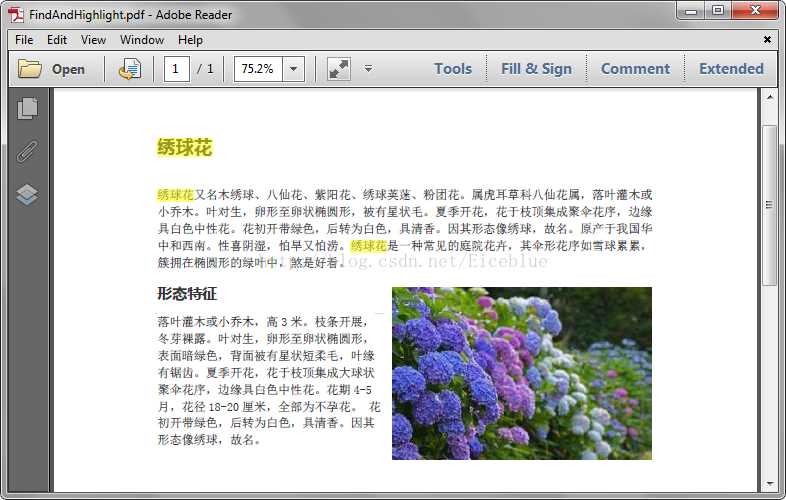
}text.ApplyHighLight(Color.Green);pdf.SaveToFile("FindAndHighlight.pdf");效果:
完整代码:
using Spire.Pdf;
using Spire.Pdf.General.Find;
namespace FindText
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = newPdfDocument();
pdf.LoadFromFile("Input.pdf");
PdfTextFind[] AllMatchedText = null;
foreach (PdfPageBase page in pdf.Pages)
{
AllMatchedText = page.FindText("绣球花").Finds;
foreach (PdfTextFindtext in AllMatchedText)
{
text.ApplyHighLight();//默认设置背景色为黄色
//text.ApplyHighLight(Color.Green); //设置自定义背景颜色
}
}
pdf.SaveToFile("FindAndHighlight.pdf");
}
}
}除了查找文本以外,Free Spire.PDF还支持读取PDF文档中的文本和图片,如果有需要,可以参考 从PDF文档提取文本和图片这篇文章。希望我的文章能对你有所帮助。














 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









