






f=urllib.urlopen("xxxxxx")
print f.getcode() #这就是获取返回的状态码 404 200等
python 服务器状态探测3种方法
1、
关键字分析
import os
#https网站加-k
cmd = ''' (curl --no-keepalive --connect-timeout 18 --stderr - '''+urls[i]+''' | grep '''+urls[i+1]+''' >/dev/null) && echo 'ok' '''
os.popen3(cmd)
2、 http head状态测试
import urllib2
3、端口探测
2、 http head状态测试
import urllib2
try:
urllib2.urlopen(urls[i],context=context)
except Exception, e:
...
3、端口探测
import os
cmd="nmap -sT -n -p 80,3389 --max-rtt-timeout 1 --max-scan-delay 1ms --host-timeout 2 " + server
(si, so, se) = os.popen3(cmd)
t=so.readlines()
if line.find('80')>=0 and line.find('open')>=0:
...
Python中获取网页状态码的两个方法
第一种是用urllib模块,下面是例示代码:
复制代码 代码如下:
import urllib
status=urllib.urlopen("http://www.jb51.net").code
print status
第二章是用requests模块,下面是例示代码:
复制代码 代码如下:
import requests
code=requests.get("http://www.jb51.net").status_code
print code
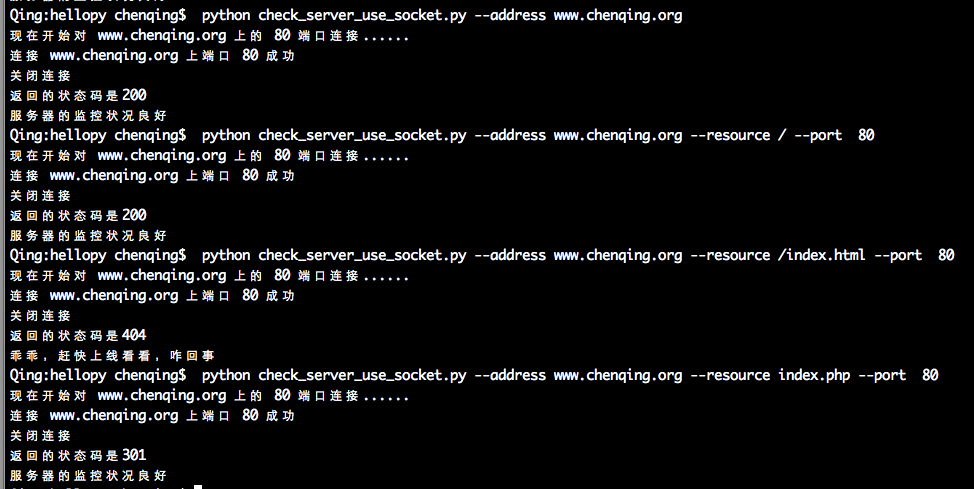














 2200
2200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









