







 本文介绍如何使用C语言解析LRC歌词文件,重点处理单行存在多个时间轴的复杂情况。通过找到每行最后一个时间轴,将其转换为毫秒,并删除多余信息,重构歌词行。最终,所有歌词按时间轴排序,实现同步播放和按条导出的功能。注意,此代码目前仅支持ANSI编码的lrc文件。
本文介绍如何使用C语言解析LRC歌词文件,重点处理单行存在多个时间轴的复杂情况。通过找到每行最后一个时间轴,将其转换为毫秒,并删除多余信息,重构歌词行。最终,所有歌词按时间轴排序,实现同步播放和按条导出的功能。注意,此代码目前仅支持ANSI编码的lrc文件。
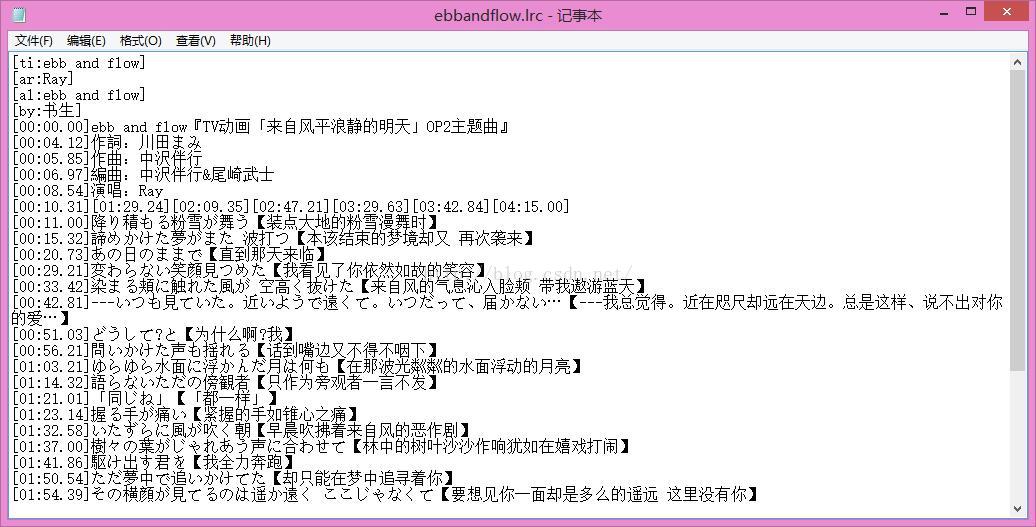
LRC文件如上图所示。
格式为 [mm:ss.ms]歌词
但是也有单行多个时间轴的情况,即 [mm:ss.ms][mm:ss.ms]歌词
对于解析来说,比较困难的正是单行多个时间轴的情况。我的解决方法是:
- 对单独一行检索]后没有[的位置,即该行最后一个[]框,将指针指向下一元素,就是这行歌词的第一个字。
- 编写函数将最后一个[]里面mm:ss.ms格式的时间轴化为long的ms。
- 删除最后一个[]及里面的内容,将后面的歌词并上来重新构成该行(整个算法的亮点就在这里)
- 重新检索该行最右边的[],直到没有[]为止
- 开始检索下一行,重复(1)的操作,直到下一行也没有[]为止。
- 整个歌词用链表储存,获取所有时间轴和歌词之后,按时间轴对链表进行排序。
我还只是初学者,代码可能不太规范,请见谅。
// .lrc Analysis
// Copyright (c) 2016 Equim. All rights reserved.
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<time.h>
#include<windows.h>
#incl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2546
2546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









