







LinkedHashMap可认为是哈希表和链接列表综合实现,并允许使用null值和null键。LinkedHashMap实现与HashMap的不同之处在于,LinkedHashMap维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。 LinkedHashMap的实现不是同步的。如果多个线程同时访问LinkedHashMap,而其中至少一个线程从结构上修改了该映射,则它必须 保持外部同步。
1.LinkedHashMap的存储结构
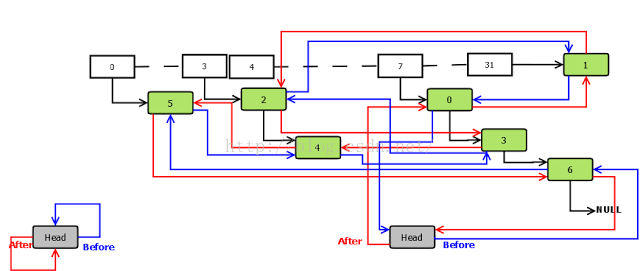
LinkedHashMap中加入了一个head头结点,将所有插入到该LinkedHashMap中的Entry按照插入的先后顺序(accessOrder标志位默认为false)依次加入到以head为头结点的双向循环链表的尾部。
LinkedHashMap实际上就是HashMap和LinkedList两个集合类的存储结构的结合。在LinkedHashMapMap中,所有put进来的Entry都保存在 如图所示的哈希表中,但它又额外定义了一个以head为头结点的空的双向循环链表,每次put进来Entry,除了将其保存到对哈希表中对应的位置上外,还要将其插入到双向循环链表的尾部。
下面我们来分析LinkedHashMap的源代码。
2.LinkedHashMap成员变量
LinkedHashMap采用的hash算法和HashMap相同,但它重新定义了数组中保存的元素Entry,该Entry除了保存当前对象的引用外,还保 存了其上一个元素before和下一个元素after的引用,从而在哈希表的基础上又构成了双向链接列表。
//双向循环链表的头结点,整个LinkedHashMap中只有一个header,
//(此链表不同于HashMap里面的那个next链表)
//它将哈希表中所有的Entry贯穿起来,header中不保存key-value对,只保存前后节点的引用
private transient Entry<K,V> header;
//双向链表中元素排序规则的标志位。
//accessOrder为false,表示按插入顺序排序
//accessOrder为true,表示按访问顺序排序
private final boolean accessOrder;
/**
* LinkedHashMap的Entry元素。
* 继承HashMap的Entry元素,又保存了其上一个元素before和下一个元素after的引用。
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
Entry<K,V> before, after;
…… //Entry类涉及到的方法,下面会继续分析
}3.构造函数
LinkedList一共提供了五个构造方法。
// 构造方法1,构造一个指定初始容量和加载因子的、按照插入顺序的LinkedList
//加载因子取默认的0.75f
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 构造方法2,构造一个指定初始容量的LinkedHashMap,取得键值对的顺序是插入顺序
//加载因子取默认的0.75f
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 构造方法3,用默认的初始化容量和加载因子创建一个LinkedHashMap,取得键值对的顺序是插入顺序
//加载因子取默认的0.75f
public LinkedHashMap() {
super();
accessOrder = false;
}
// 构造方法4,通过传入的map创建一个LinkedHashMap,容量为默认容量(16)和
//(map.zise()/DEFAULT_LOAD_FACTORY)+1的较大者,加载因子为默认值0.75
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
// 构造方法5,根据指定容量、加载因子和指定链表中的元素排序的规则 创建一个LinkedHashMap
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
}4.元素存储
LinkedHashMap重写了父类HashMap的put方法调用的子方法void addEntry(int hash, K key, V value, int bucketIndex) 和void createEntry(int hash, K key, V value, int bucketIndex),提供了自己特有的双向链接列表的实现。
//覆写HashMap中的addEntry方法,LinkedHashmap并没有覆写HashMap中的put方法,
//而是覆写了put方法所调用的addEntry方法和recordAccess方法,
//put方法在插入的key已存在的情况下,会调用recordAccess方法,
//在插入的key不存在的情况下,要调用addEntry插入新的Entry
void addEntry(int hash, K key, V value, int bucketIndex) {
//创建新的Entry,并插入到LinkedHashMap中
createEntry(hash, key, value, bucketIndex);
//双向链表的第一个有效节点(header后的那个节点)为近期最少使用的节点
Entry<K,V> eldest = header.after;
//如果有必要,则删除掉该近期最少使用的节点,
//这要看对removeEldestEntry的覆写,由于默认为false,因此默认是不做任何处理的。
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
//超过阈值,扩容到原来的2倍
if (size >= threshold)
resize(2 * table.length);
}
}
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
// 调用元素的addBrefore方法,将元素加入到哈希、双向链接列表。
//每次插入Entry时,都将其移到双向链表的尾部,
//这便会按照Entry插入LinkedHashMap的先后顺序来迭代元素,
//同时,新put进来的Entry是最近访问的Entry,把其放在链表末尾,符合LRU算法的实现
e.addBefore(header);
size++;
}
//双向循环立链表中,将当前的Entry插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
//该方法默认返回false,我们一般在用LinkedHashMap实现LRU算法时,
//要覆写该方法,一般的实现是,当设定的内存(这里指节点个数)达到最大值时,返回true,
//这样put新的Entry(该Entry的key在哈希表中没有已经存在)时,
//就会调用removeEntryForKey方法,将最近最少使用的节点删除(head后面的那个节点,实际上是最近没有使用)。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
}5.元素读取
LinkedHashMap重写了父类HashMap的get方法。由于的链表的增加、删除操作是常量级的,性能不会带来较大损失。LinkedHashMap 最牛逼的地方在于recordAccess()方法
//覆写HashMap中的get方法,通过getEntry方法获取Entry对象。
//注意这里的recordAccess方法,
//如果链表中元素的排序规则是按照插入的先后顺序排序的话,该方法什么也不做,
//如果链表中元素的排序规则是按照访问的先后顺序排序的话,则将e移到链表的末尾处。
public V get(Object key) {
// 调用父类HashMap的getEntry()方法,取得要查找的元素。
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
// 记录访问顺序。
e.recordAccess(this);
return e.value;
}
//覆写HashMap中的recordAccess方法(HashMap中该方法为空),
//当调用父类的put方法,在发现插入的key已经存在时,会调用该方法,
//调用LinkedHashmap覆写的get方法时,也会调用到该方法,
//该方法提供了LRU算法的实现,它将最近使用的Entry放到双向循环链表的尾部,
//accessOrder为true时,get方法会调用recordAccess方法
//put方法在覆盖key-value对时也会调用recordAccess方法
//它们导致Entry最近使用,因此将其移到双向链表的末尾
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//如果链表中元素按照访问顺序排序,则将当前访问的Entry移到双向循环链表的尾部,
//如果是按照插入的先后顺序排序,则不做任何事情。
if (lm.accessOrder) {
lm.modCount++;
remove();//移除当前访问的Entry
addBefore(lm.header);//将当前访问的Entry插入到链表的尾部
}
}6.元素删除
LinkedHashMap没有重写remove(Object key)方法,重写了被remove调用的recordRemoval方法,再一次感叹模板方法模式的精妙!
HahsMap remove(Object key)把数据从横向数组 * 竖向next链表里面移除之后(就已经完成工作了,所以HashMap里面recordRemoval是空的实现调用了此方法
但在LinkedHashMap里面,还需要移除header链表里面Entry的after和before关系。
// 继承了HashMap.Entry
private static class Entry<K, V> extends HashMap.Entry<K, V> {
void recordRemoval(HashMap<K, V> m) {
remove();
}
//让当前Entry从header链表中消失
private void remove() {
before.after = after;
after.before = before;
}
}7.元素遍历
//迭代器
private abstract class LinkedHashIterator<T> implements Iterator<T> {
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
int expectedModCount = modCount;
public boolean hasNext() {
return nextEntry != header;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
//从head的下一个节点开始迭代
Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
//key迭代器
//看出这三个类都很简单,只有一个next()方法,next()方法也只是去调用LinkedHashIterator类中相应的方法
private class KeyIterator extends LinkedHashIterator<K> {
public K next() { return nextEntry().getKey(); }
}
//value迭代器
private class ValueIterator extends LinkedHashIterator<V> {
public V next() { return nextEntry().value; }
}
//Entry迭代器
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() { return nextEntry(); }
}8.基于LinkedHashMap实现LRU Cache
用LinkedHashmap实现LRU算法,就要覆写方法removeEldestEntry。该方法默认返回false,我们一般在用LinkedHashMap实现LRU算法时,要覆写该方法,一般的实现是,当设定的内存(这里指节点个数)达到最大值时,返回true,这样put新的Entry(该Entry的key在哈希表中没有已经存在)时,就会调用removeEntryForKey方法,将最近最少使用的节点删除(head后面的那个节点,实际上是最近没有使用)。
LinkedHashMap是如何实现LRU的。首先,当accessOrder为true时,才会开启按访问顺序排序的模式,才能用来实现LRU算法。我们 可以看到,无论是put方法还是get方法,都会导致目标Entry成为最近访问的Entry,因此便把该Entry加入到了双向链表的末尾( get方法通过调用recordAccess方法来实现,put方法在覆盖已有key的情况下,也是通过调用recordAccess方法来实现,在插入新的Entry时,则是通过createEntry中的addBefore方法来实现),这样便把最近使用了的Entry放入到了双向链表的后面,多次操作后, 双向链表前面的Entry便是最近没有使用的,这样当节点个数满的时候,删除的最前面的Entry(head后面的那个Entry)便是最近最少使用的Entry。
/*LRU是Least Recently Used 近期最少使用算法。
*通过HashLiekedMap实现LRU的算法的关键是,如果map里面的元素个数大于了缓存最大容量,则删除链表头元素
*/
/*public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder)
*LRU参数参数:
*initialCapacity - 初始容量。
*loadFactor - 加载因子(需要是按该因子扩充容量)。
*accessOrder - 排序模式( true) - 对于访问顺序(get一个元素后,这个元素被加到最后,使用了LRU 最近最少被使用的调度算法),对于插入顺序,则为 false,可以不断加入元素。
*/
/*相关思路介绍:
* 当有一个新的元素加入到链表里面时,程序会调用LinkedHahMap类中Entry的addEntry方法,
*而该方法又会 会调用removeEldestEntry方法,这里就是实现LRU元素过期机制的地方,
* 默认的情况下removeEldestEntry方法只返回false,表示可以一直表链表里面增加元素,在这个里 *修改一下就好了。
*
*/
/*
测试数据:
11
7 0 7 1 0 1 2 1 2 6
*/
import java.util.*;
public class LRULinkedHashMap<K,V> extends LinkedHashMap<K,V>{
private int capacity; //初始内存容量
LRULinkedHashMap(int capacity){ //构造方法,传入一个参数
super(16,0.75f,true); //调用LinkedHashMap,传入参数
this.capacity=capacity; //传递指定的最大内存容量
}
@Override
public boolean removeEldestEntry(Map.Entry<K, V> eldest){
//,每加入一个元素,就判断是size是否超过了已定的容量
System.out.println("此时的size大小="+size());
if((size()>capacity))
{
System.out.println("超出已定的内存容量,把链表顶端元素移除:"+eldest.getValue());
}
return size()>capacity;
}
public static void main(String[] args) throws Exception{//方便实例,直接将异常抛出
Scanner cin = new Scanner(System.in);
System.out.println("请输入总共内存页面数: ");
int n = cin.nextInt();
Map<Integer,Integer> map=new LRULinkedHashMap<Integer, Integer>(n);
System.out.println("请输入按顺序输入要访问内存的总共页面数: ");
int y = cin.nextInt();
System.out.println("请输入按顺序输入访问内存的页面序列: ");
for(int i=1;i<=y;i++)
{
int x = cin.nextInt();
map.put(x, x);
}
System.out.println("此时内存中包含的页面数是有:");
//遍历此时内存中的页面并输出
for(java.util.Map.Entry<Integer, Integer> entry: map.entrySet()){
System.out.println(entry.getValue());
}
}
}9.总结
-
LinkedHashMap继承自HashMap,具有HashMap的大部分特性,比如支持null键和值,默认容量为16,装载因子为0.75,非线程安全等等;
-
LinkedHashMap通过设置accessOrder控制遍历顺序是按照插入顺序还是按照访问顺序。当accessOrder为true时,可以利用其完成LRU缓存的功能;
-
LinkedHashMap内部维护了一个双向循环链表,并且其迭代操作时通过链表完成的,而不是去遍历hash表。














 6664
6664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









