







摘要:在hadoop中,一个job需要另一个job的输出结果作为输入源。本文写了一个例子来设置4个不同Job的依赖实例
工程源码下载:https://github.com/appleappleapple/BigDataLearning/tree/master/Hadoop-Demo
在文章中
Hadoop实战演练:搜索数据分析----TopK计算(2)
Hadoop实战演练:搜索数据分析----计算结果存储到Mysql(3)
上面加起来总共有4个job。而且都是有上下依赖关系(文章1的结果输给文章2做为输入,文章2的结果输出给文章3作为输入),照之前笔者的作法都是分开的,下面将对4个job进行串连。
1、代码编写
package com.lin.keyword;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob;
import org.apache.hadoop.mapreduce.lib.jobcontrol.JobControl;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import com.lin.common.Constrants;
import com.lin.keyword.SaveResult.StudentMapper;
import com.lin.keyword.SaveResult.StudentReducer;
import com.lin.keyword.TopK.KMap;
import com.lin.keyword.TopK.KReduce;
/**
* 功能概要:四个Job汇总依次运行
*
* @author linbingwen
*/
public class Test {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
DBConfiguration.configureDB(conf, Constrants.JDBC_DRIVE,Constrants.JDBC_URL,Constrants.JDBC_USER, Constrants.JDBC_PASSWORD);
//设置hadoop的机器、端口
conf.set(Constrants.CONF_NAME, Constrants.CONF_VALUE);
//设置输入输出文件目录
String[] ioArgs = new String[] { Constrants.HDFS_PATH +"data_in", Constrants.HDFS_PATH + "cleanSame_out" , Constrants.HDFS_PATH +"wordCount_out",Constrants.HDFS_PATH +"result_out" };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 4) {
System.err.println("Usage: <in> <out>");
System.exit(2);
}
/***********************************去除重复数据作业***********************************/
// 设置一个job
Job job0 = Job.getInstance(conf, "clean same data");
job0.setJarByClass(CleanSameData.class);
// 设置Map、Combine和Reduce处理类
job0.setMapperClass(CleanSameData.Map.class);
job0.setCombinerClass(CleanSameData.Reduce.class);
job0.setReducerClass(CleanSameData.Reduce.class);
// 设置输出类型
job0.setOutputKeyClass(Text.class);
job0.setOutputValueClass(Text.class);
// 将输入的数据集分割成小数据块splites,提供一个RecordReder的实现
job0.setInputFormatClass(TextInputFormat.class);
// 提供一个RecordWriter的实现,负责数据输出
job0.setOutputFormatClass(TextOutputFormat.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job0, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job0, new Path(otherArgs[1]));
//加入控制容器
ControlledJob ctrljob0=new ControlledJob(conf);
ctrljob0.setJob(job0);
/***********************************统计搜索词次数作业***********************************/
//设置一个job
Job job1 = Job.getInstance(conf, "key Word count");
job1.setJarByClass(KeyWordCount.class);
// 设置Map、Combine和Reduce处理类
job1.setMapperClass(KeyWordCount.Map.class);
job1.setCombinerClass(KeyWordCount.Reduce.class);
job1.setReducerClass(KeyWordCount.Reduce.class);
// 设置输出类型
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(IntWritable.class);
// 将输入的数据集分割成小数据块splites,提供一个RecordReder的实现
job1.setInputFormatClass(TextInputFormat.class);
// 提供一个RecordWriter的实现,负责数据输出
job1.setOutputFormatClass(TextOutputFormat.class);
//加入控制容器
ControlledJob ctrljob1=new ControlledJob(conf);
ctrljob1.setJob(job1);
//设置多个作业直接的依赖关系
ctrljob1.addDependingJob(ctrljob0);
// 设置job1输入和输出目录
FileInputFormat.addInputPath(job1, new Path(otherArgs[1]));
FileOutputFormat.setOutputPath(job1, new Path(otherArgs[2]));
/***********************************统计top k作业***********************************/
//设置一个job
Job job2 = Job.getInstance(conf, "top K");
job2.setJarByClass(TopK.class);
// 设置Map、Combine和Reduce处理类
job2.setMapperClass(KMap.class);
job2.setCombinerClass(KReduce.class);
job2.setReducerClass(KReduce.class);
// 设置输出类型
job2.setOutputKeyClass(IntWritable.class);
job2.setOutputValueClass(Text.class);
// 将输入的数据集分割成小数据块splites,提供一个RecordReder的实现
job2.setInputFormatClass(TextInputFormat.class);
// 提供一个RecordWriter的实现,负责数据输出
job2.setOutputFormatClass(TextOutputFormat.class);
//job2.setOutputFormatClass(DBOutputFormat.class);
//作业2加入控制容器
ControlledJob ctrljob2=new ControlledJob(conf);
ctrljob2.setJob(job2);
//设置多个作业直接的依赖关系
ctrljob2.addDependingJob(ctrljob1);
//输入路径是上一个作业的输出路径,因此这里填args[2],要和上面对应好
FileInputFormat.addInputPath(job2, new Path(otherArgs[2]));
//输出路径从新传入一个参数,这里需要注意,因为我们最后的输出文件一定要是没有出现过得
//因此我们在这里new Path(args[3])因为args[3]在上面没有用过,只要和上面不同就可以了
FileOutputFormat.setOutputPath(job2,new Path(otherArgs[3]));
/***********************************保存到数据库作业***********************************/
//第四个作业,将结果保存到mysql
Job job3 = Job.getInstance(conf, "SaveResult");
job3.setJarByClass(SaveResult.class);
// 输入路径
FileInputFormat.addInputPath(job3, new Path(otherArgs[3]));
// Mapper
job3.setMapperClass(StudentMapper.class);
// Reducer
job3.setReducerClass(StudentReducer.class);
// mapper输出格式
job3.setOutputKeyClass(LongWritable.class);
job3.setOutputValueClass(Text.class);
// 输入格式,默认就是TextInputFormat
job3.setOutputFormatClass(DBOutputFormat.class);
// 输出到哪些表、字段
DBOutputFormat.setOutput(job3, "key_word", "word", "total");
//作业2加入控制容器
ControlledJob ctrljob3=new ControlledJob(conf);
ctrljob3.setJob(job3);
//设置多个作业直接的依赖关系
ctrljob3.addDependingJob(ctrljob2);
//主的控制容器,控制上面的总的两个子作业
JobControl jobCtrl=new JobControl("myctrl");
//添加到总的JobControl里,进行控制
jobCtrl.addJob(ctrljob0);
jobCtrl.addJob(ctrljob1);
jobCtrl.addJob(ctrljob2);
jobCtrl.addJob(ctrljob3);
//在线程启动,记住一定要有这个
Thread t=new Thread(jobCtrl);
t.start();
while(true) {
if(jobCtrl.allFinished()){//如果作业成功完成,就打印成功作业的信息
System.out.println(jobCtrl.getSuccessfulJobList());
jobCtrl.stop();
break;
}
}
}
}这里是一些常量定义:
package com.lin.common;
/**
* 功能概要:
*
* @author linbingwen
* @since 2016年7月31日
*/
public class Constrants {
public static String JDBC_DRIVE = "com.mysql.cj.jdbc.Driver";
public static String JDBC_URL = "jdbc:mysql://localhost:3306/learning?serverTimezone=UTC";
public static String JDBC_USER = "root";
public static String JDBC_PASSWORD = "linlin";
public static String CONF_NAME = "mapred.job.tracker";
public static String CONF_VALUE = "10.75.201.125:9000";
public static String HDFS_PATH = "hdfs://hmaster:9000/";
}
输出结果:
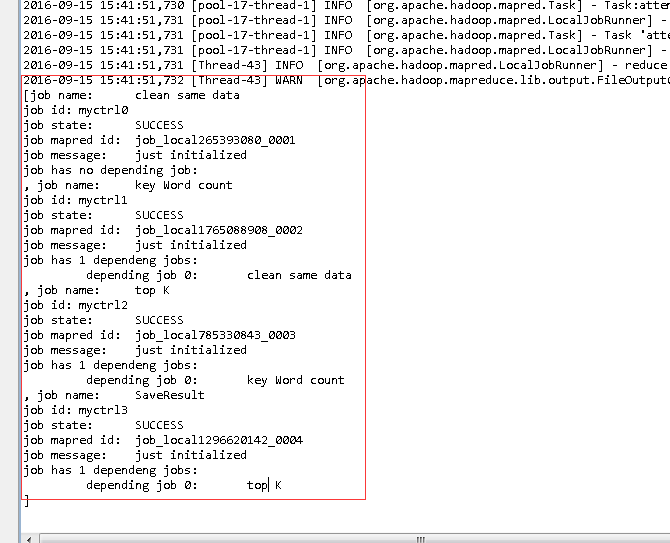
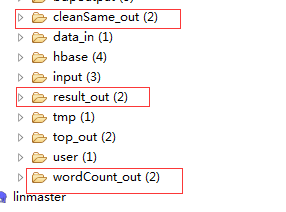
总共有3个输出目录:
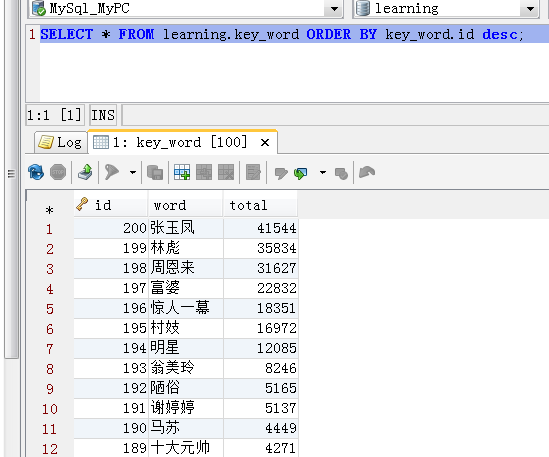
数据库保存结果:














 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









