







工欲善其事,必先利其器。我们要进行数据挖掘,就必须先获取数据,获取数据的方法有很多种,其中一种就是爬虫。下面我们利用Python2.7,写一个爬虫,专门爬取中新网http://www.chinanews.com/scroll-news/news1.html滚动新闻列表内的新闻,并将新闻正文保存在以新闻类别命名的文件夹下的以该新闻的发布日期和顺序命名的文本中。具体代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import os
import re
import urllib2
import sys
reload(sys)
sys.setdefaultencoding('utf8')
# 得到页面全部内容
def askURL(url):
html = ''
request = urllib2.Request(url) # 发送请求
try:
response = urllib2.urlopen(request) # 取得响应
html = response.read() # 获取网页内容
# print html
html = html.decode('gbk', 'ignore') # 将gbk编码转为unicode编码
html = html.encode('utf-8', 'ignore') # 将unicode编码转为utf-8编码
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
if hasattr(e, "reason"):
print e.reason
return html
# 得到正文
def getContent(url):
html = askURL(url)
text = ''
# 找到新闻主体所在的标签
findDiv = re.compile(r'<div class="left_zw" style="position:relative">'
r'(.*)<div id="function_code_page">', re.S)
div = re.findall(findDiv, html)
if len(div) != 0:
content = div[0]
labels = re.compile(r'[/]*<.*?>', re.S)
text = re.sub(labels, '', content) # 去掉各种标签
text = re.sub(r'\s|中新社.*?电|\(完\)|\(记者.*?\)', '', text) # 去掉空行和换行符,无关内容
text = re.sub(r' ', '\n', text) # 将缩进符替换成换行符
# print text
return text
# 根据类别按顺序命名文件
def saveFile(labelName, date, fileNum):
dirname = "news"
# 若目录不存在,就新建
# 文件保存在程序的当前目录下
if (not os.path.exists(dirname)):
os.mkdir(dirname)
labelName = labelName.encode('gbk', 'ignore')
labelpath = dirname + '\\' + labelName
if (not os.path.exists(labelpath)):
os.mkdir(labelpath)
path = labelpath + "\\" + date + "-0" + str(fileNum) + ".txt" # w文本保存路径
print "正在下载" + path
# path=path.encode('gbk','utf-8')#转换编码
f = open(path, 'w+')
return f
# 得到正文的URL,读取正文,并保存
def getURL(nurl, labelName):
html = askURL(nurl)
findDiv = re.compile(r'<div class="dd_lm">.*</div>')
findTime = re.compile(r'<div class="dd_time">(.*)</div>')
# 旧的格式为findTitle=re.compile(r'<div class="dd_bt"><a href="http://www.chinanews.com/.*\.shtml">(.*)</a></div>')
findTitle = re.compile(r'<div class="dd_bt"><a href="//www.chinanews.com/.*\.shtml">(.*)</a></div>')
findURL = re.compile(r'<div class="dd_bt"><a href="(//www.chinanews.com/.*\.shtml)">.*</a></div>')
findLabel = re.compile(r'<div class="dd_lm">\[<a href=//www.chinanews.com/.*\.shtml>(.*)</a>\]</div>')
fileNum = 0
for info in re.findall(findDiv, html):
# print info
time = re.findall(findTime, info)[0]
date = re.findall(r'\d?-\d*', time)[0] # 获取新闻发布日期
title = re.findall(findTitle, info)[0]
# 添加上http头部
url = 'http:' + re.findall(findURL, info)[0] # 获取新闻正文的链接
label = re.findall(findLabel, info)[0] # 获取新闻所属类别
if (label == "I T"): # 网页为I T
label = "IT"
if (labelName == label):
text = getContent(url)
# 如果新闻内容长度大于1000,保存新闻标题和正文
if (len(text) > 1000):
fileNum = fileNum + 1
f = saveFile(labelName, date, fileNum)
f.write(title)
f.write(text)
f.close()
# 抓取新闻标题、类别、发布时间、url,并建立相应的文件,存到相应的类别文件夹中
def getNews(url, begin_page, end_page, labelName):
for i in range(begin_page, end_page + 1):
nurl = url + str(i) + ".html"
# print nurl
# 获取网页内容
getURL(nurl, labelName)
# 接收输入类别、起始页数、终止页数
def main():
url = 'http://www.chinanews.com/scroll-news/news'
ch = int(raw_input(u'请输入类别的对应的数字(IT=1、财经=2、地方=3、国际=4、国内=5、健康=6、军事=7、'
u'社会=8、体育=9、文化=10),输入-1退出,输入0表示全选:\n'))
labels = ('IT', '财经', '地方', "国际", "国内", "健康", "军事", "社会", "体育", "文化")
while (ch != -1):
begin_page = int(raw_input(u'请输入开始的页数(1,):\n'))
end_page = int(raw_input(u'请输入终点的页数(1,):\n'))
if (ch >= 1 and ch <= 10):
getNews(url, begin_page, end_page, labels[ch - 1])
elif (ch == 0):
for label in labels:
getNews(url, begin_page, end_page, label)
else:
print "输入错误,请重新输入!"
ch = int(raw_input(u'请输入类别的对应的数字(IT=1、财经=2、地方=3、国际=4、国内=5、健康=6、军事=7、'
u'社会=8、体育=9、文化=10),输入-1退出,输入0表示全选:\n'))
# 调用主函数
# 一页有125条新闻
main()
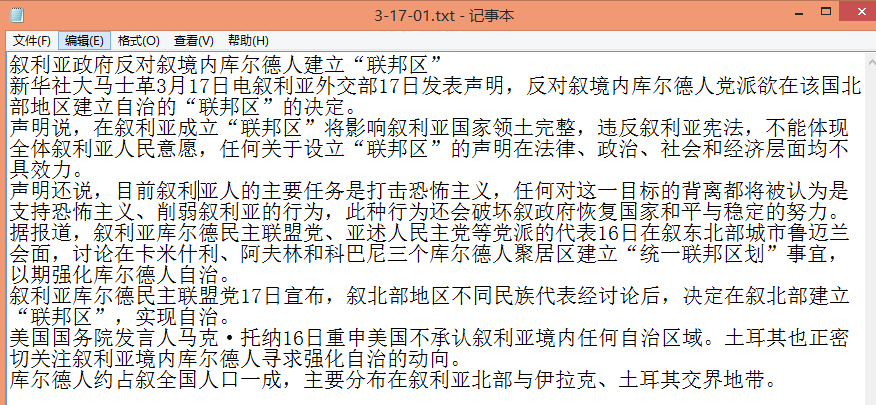
爬取的新闻内容(标题+长度大于1000的正文)如下:














 4632
4632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









