






原文链接:MobileFaceNets: Efficient CNNs for Accurate Real-time Face Verification on Mobile Devices
MobileNet
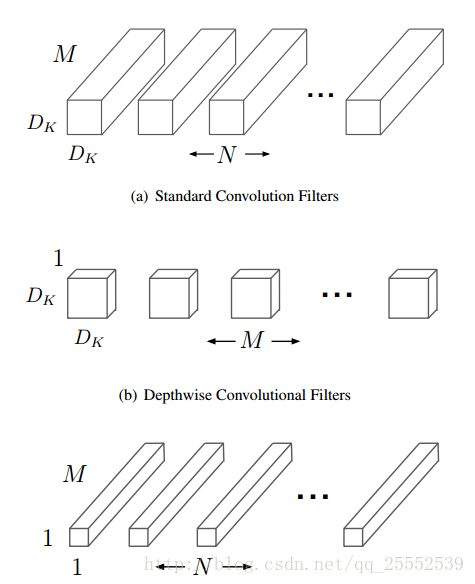
可分离卷积(Depthwise separable conv):
可分离卷积可以减少参数量与计算量:
例如输入是100*100*3,普通卷积采用3*3*3*52的卷积核,输出为100*100*52,参数量为3*3*3*52=1404
使用深度分离卷积,第一步是采用3*3*3的卷积核,输出各个通道不相加,仍然为3通道,第二步采用1*1*3*52的卷积核,输出相同,参数量为27+156=183,参数量减少
MobileNetV2
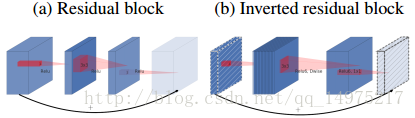

使用反残差模块,“反”体现在原来的模块会使用1*1的卷积和降维,再用3*3卷积核去卷积,现先使用1*1的卷积核升维,再使用大卷积核卷积。
那有人会问,这样不是会增加计算量吗?
其实,减少计算量体现在第二层是只有一个卷积核,即使用了可分离卷积的方式,因此计算量会减少。
举个例子:
假设不使用可分离卷积,设输入通道数为20,输出通道数同样要20,那么第二层需要3*3*20*20个参数,
使用了可分离卷积,第二层则只需要3*3*20*1个参数,每个通道的卷积结果不相加,因此输出通道数不变,但是减少了计算量。
MobileNetV2网络结构
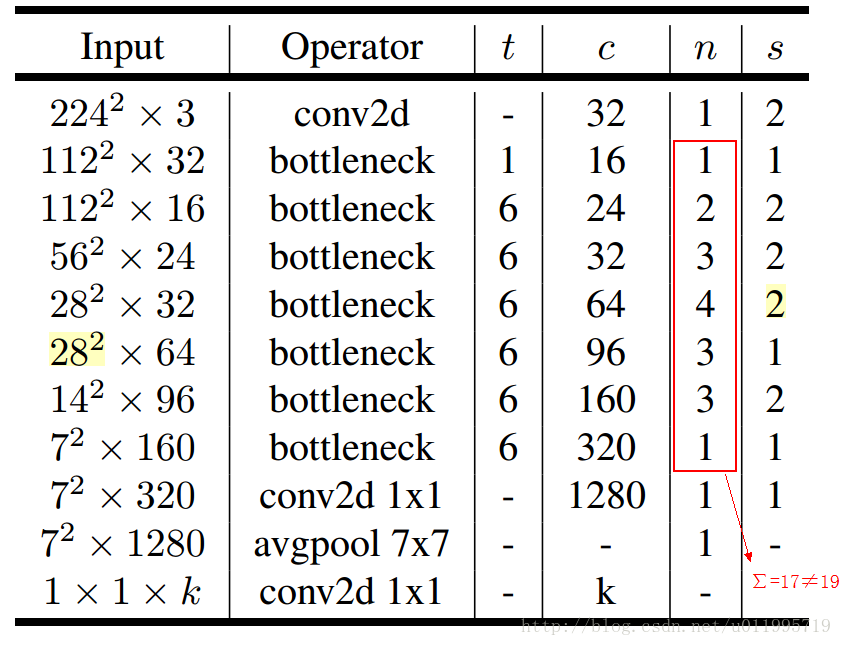
其中:t表示通道“扩张”倍数,c表示输出通道数,n表示重复次数,s表示步长stride。
MobileFaceNet
mobilefacenet其实是mobilenetV2的改进版本,主要改进之处有以下几个地方:
1.针对平均池化层,许多研究表明,使用平均池化层会使得网络表现下降,但是一直没有理论说明,因此作者在文中给出了一个理论解释:
在最后一个7*7特征图中,虽然中心点的感知域和边角点的感知域是一样的,但是中心点的感知域包括了完整的图片,边角点的感知域却只有部分的图片,因此每个点的权重应该不一样,但是平均池化层却把他们当作一样的权重去考虑了,因此网络表现会下降,如图:

因此,作者在此处使用了可分离卷积代替平均池化层,即使用一个7*7*512(512表示输入特征图通道数目)的可分离卷积层代替了全局平均池化,这样可以让网络自己不同点的学习权重。
此处的可分离卷积层使用的英文名是global depthwise convolution,global表示全局,depthwise表示逐深度,即逐通道的卷积,其实就是之前描述的那种可分离卷积的方式:使用7*7*512的卷积核代替7*7*512*512的卷积核。
其实这里我们可以发现,后者其实是全卷积[1]。
2.采用Insightface的损失函数进行训练。
3.一些小细节:通道扩张倍数变小;使用Prelu代替relu;使用batch Normalization。
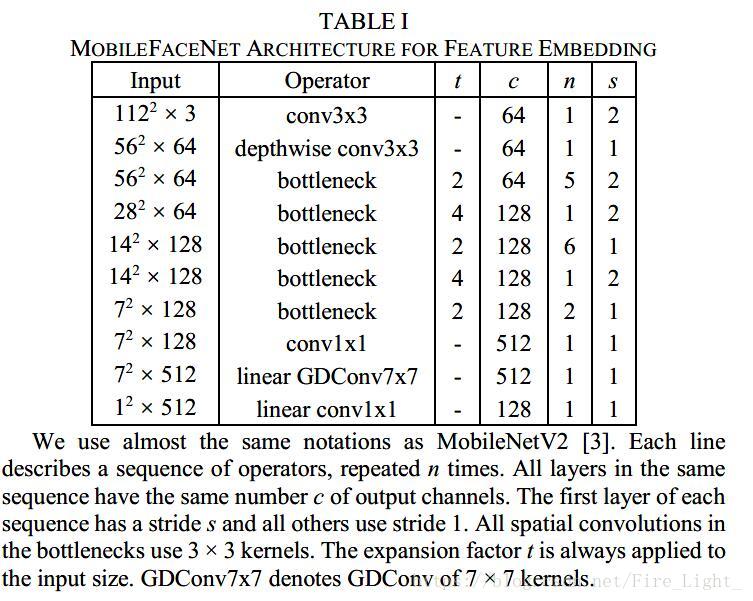
网络整体结构如下:
实验及结果
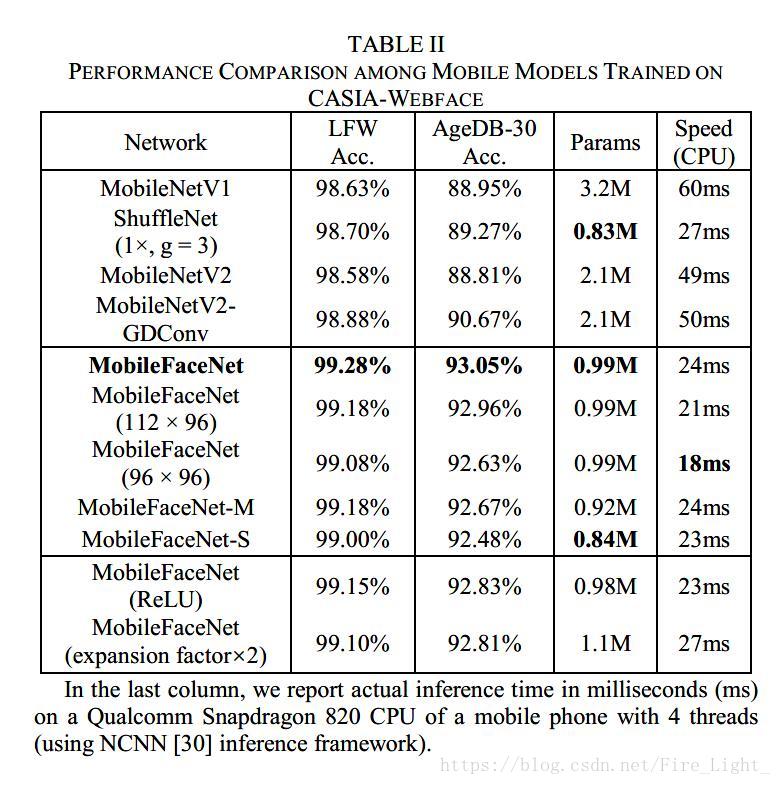
和MobileNet、ShuffleNet的对比
此处训练集采用CASIA-Webface,损失采用Insightface的损失
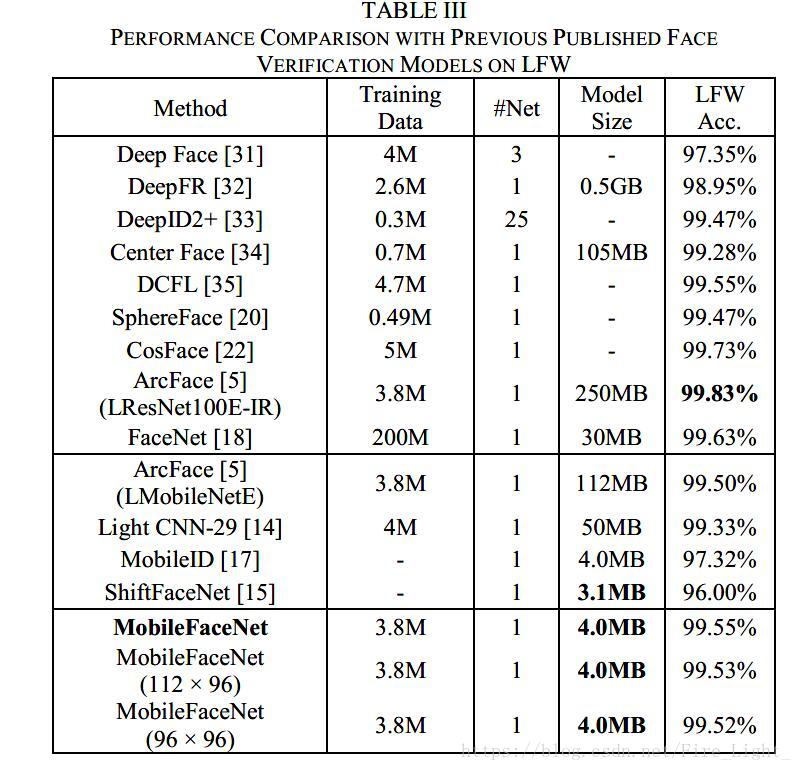
和其他算法的对比
此处训练集采用清理过的MS-Celeb-1M,损失采用Insightface的损失。
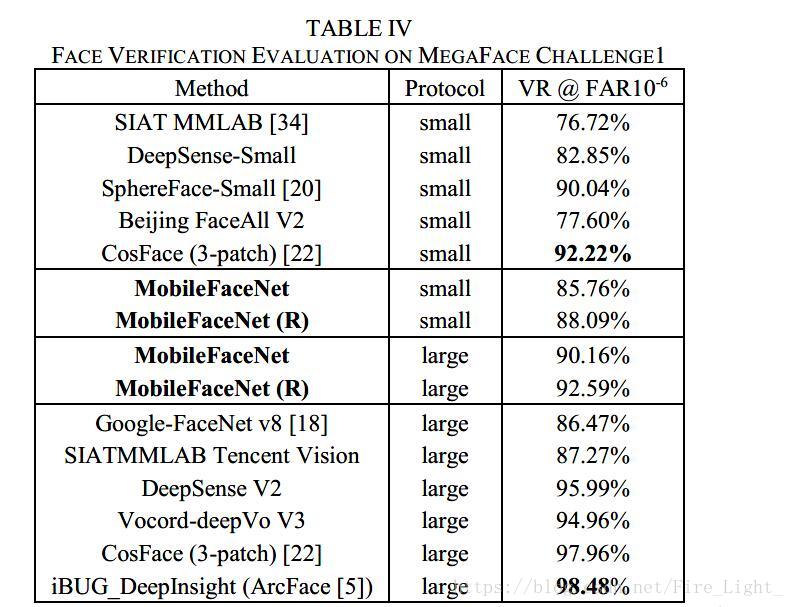
Megaface
文中引用
[1] Evan Shelhamer, Jonathan Long, Trevor Darrell.Fully Convolutional Networks for Semantic Segmentation .arXiv:1605.06211,2016.














 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









