







下载spark源码
从spark官网下载spark源码的选择如下图:
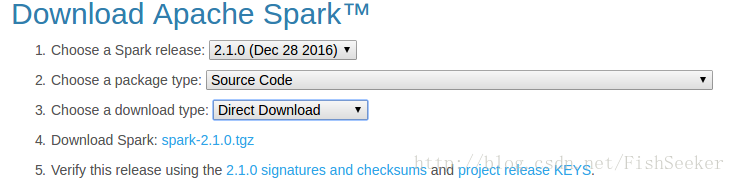
重点就是第二个选择source code然后点击第四个下载tgz包。
下载之后解压到你想要的目录下,这样你就获得了spark的源码。
安装maven
这里是使用maven对spark进行编译,当然要下载maven:点这里下载maven。
老规矩下载只有解压到你需要的目录。
然后配置maven的环境变量如下:
export MAVEN_HOME=/home/ubuntu/maven
export MAVEN=$MAVEN_HOME/bin
export MAVEN_OPTS="Xms256m -Xmx512m"
export PATH=$MAVEN:$PATH之后可以通过mvn –version来查看maven版本,如果出现版本信息说明安装成功。
编译spark源码
这里我们使用源码包中自带的make-distribution.sh文件进行编译。当然在编译之前你可以试着修改一些源代码。
在spark源码目录下运行
./make-distribution.sh --tgz -Phadoop-2.6 -Pyarn -DskipTests -Dhadoop.version=2.6.0 -Phive -Phive-thriftserver 参数解释:
-DskipTests,不执行测试用例,但编译测试用例类生成相应的class文件至target/test-classes下。
-Dhadoop.version 和-Phadoop: Hadoop 版本号,不加此参数时hadoop 版本为1.0.4 。
-Pyarn :是否支持Hadoop YARN ,不加参数时为不支持yarn 。
-Phive和-Phive-thriftserver:是否在Spark SQL 中支持hive ,不加此参数时为不支持hive 。
–with-tachyon :是否支持内存文件系统Tachyon ,不加此参数时不支持tachyon 。
–tgz :在根目录下生成 spark-$VERSION-bin.tgz ,不加此参数时不生成tgz 文件,只生成/dist 目录。
ps:以前的–with-hive –with-yarn都不再支持了
这样大概要等二十分钟到一个多小时不等,主要取决于网络环境,因为要下载一些依赖包之类的。之后你就可以获得一个spark编译好的包了,解压之后就可以部署到机器上了。
相关内容:
如何安装spark:
http://blog.csdn.net/fishseeker/article/details/61918138
如何在IDEA中调试spark程序:
http://blog.csdn.net/fishseeker/article/details/63741265














 702
702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









