







(1) 监督式学习(supervised learning) 和 非监督式学习(unsupervised learning)
监督学习:监督学习,简单来说就是给定一定的训练样本(这里一定要注意,这个样本是既有数据,也有数据相对应的结果),
利用这个样本进行训练得到一个模型(可以说就是一个函数),然后利用这个模型,将所有的输入映射为相应的输出,
之后对输出进行简单的判断从而达到了分类(或者说回归)的问题。简单做一个区分,分类就是离散的数据,回归就是连续的数据。
在视频中Andrew Ng举了一个breast cancer和垃圾邮件分类这两个例子来说明了分类问题。用房屋售价的例子来说明了回归问题。
非监督学习:同样,给了样本,但是这个样本是只有数据,但是没有其对应的结果,要求直接对数据进行分析建模。
Andrew Ng用google 新闻来说明了聚类这种非监督式学习的例子。
(2)线性回归模型
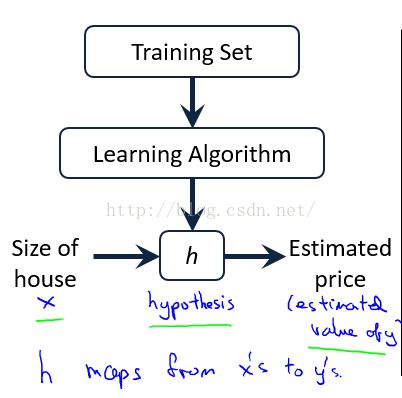
假设 房子间隔 price ,房子面积 x
price = h(x)= θ0 + θ1 × x
当取到合适的θ0和θ1时就可以预测房子的价格price,在这里Andrew引出了Cost function J(θ0,θ1)
挡代价函数J(θ0,θ1)的值最小时,即取得了最合适的θ0,θ1。

如图,用 测试数据中 实际面积代入函数h(θ)的值减去实际房子价格的平方来表示代价函数。
在求解 Cost function中,Andrew Ng讲解了2种方法。
方法一:梯度下降 (gradient descent)

梯度下降算法如上提所示,需要不断更新θ,更新公式如上图所示,每次跟新需要同步更新所有的θ。
梯度下降算法容易陷入局部最优的困境中,如下图看
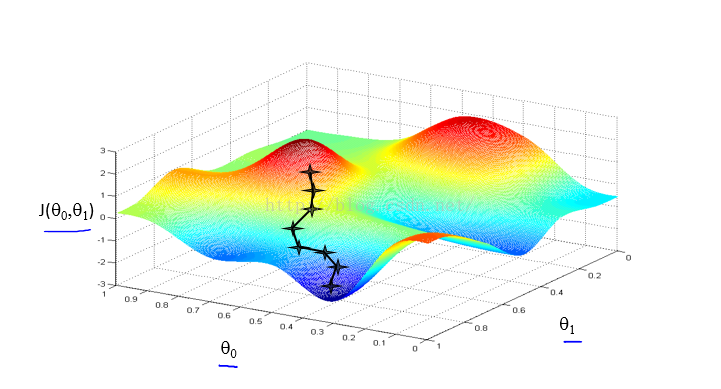
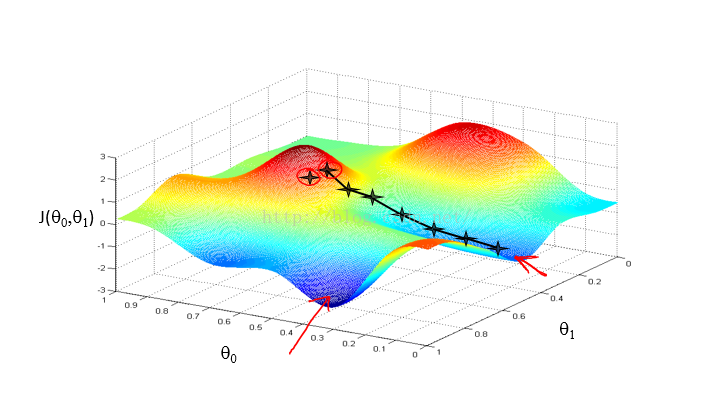
这两张图中可以看出来,初始点差一点,但是最终求得的结果却相差甚远。
在梯度下降中,下降速率 α很重要,
当α 过小时,梯度下降算法执行的效率低。
当α 过大时,会使得结果离最优点越来越远。
当变量数量多于1个时梯度下降:梯度下降的一般公式:

对J(θ)的θi求积分,会使的右边多乘以一个xi,公式可以由积分公式推导出来。
对特征值X进行 归一化,可以加快梯度下降的速度。
方法二:正规方程

正规方程即用矩阵方程的形式直接算出 θ 向量的值。正规方程相对于梯度下降算法的优点是:正规方程较梯度下降简单。但是同样的他也有自己的缺点:他要计算 X的转置乘以X。当特征值数量较大时,计算所需要的资源比较多。
在课上Andrew推荐 在特征值数量在20000以下时,可以使用正规方程。
在特征值数量超过20000时,使用梯度下降更好一些。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









