







我们在百度中搜索http://shixin.court.gov.cn/ ,会有一个内嵌的查询页面:
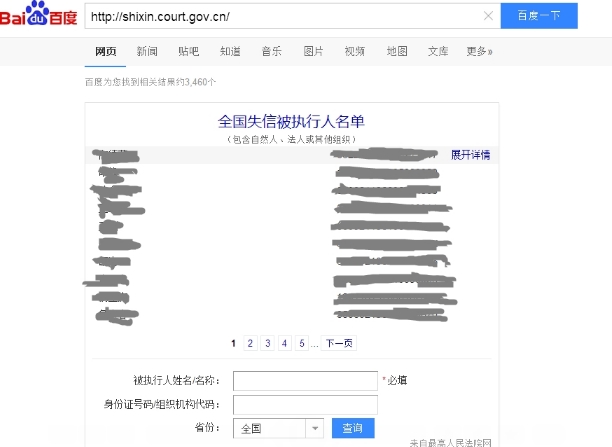
这个是通过ajax技术加载的,因为是js渲染,所以页面源代码中并不包含这些信息。
通过Firefox的Firebug监视网络请求,发现是向百度opendata请求的,结果返回一个包含100条数据的json
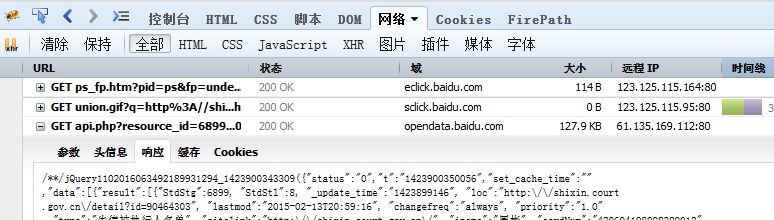
这样,通过分析请求字符串的参数,自定义请求,可以通过爬虫直接爬取的数据。
有了数据之后需要解析,每次请求会返回100条数据,现在需要把这100条数据全部解除出来并存入Mongodb数据库中。
爬虫使用webmagic:https://github.com/code4craft/webmagic
数据库Mongodb驱动使用 https://github.com/mongodb/mongo-java-driver
maven坐标:
<dependencies>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.5.2</version>
</dependency>
<dependency& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4570
4570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









