







近期在做一个图书推荐系统的项目,其中在登录模块涉及到了中文字符,这一直是个很烦人的问题,因为编码格式太多,且不同编码格式下相同的字符的长度也不一样,所以在字符编码,特别是中文编码这一块很让人头疼,但幸好这一次,解决了问题,下面我就简单的谈一谈我对他的理解
在廖学峰的博客上他对编码做了一个简答的介绍,但主要是试验部分,我主要是结合我自己做的项目对其进行解读
1:字符编码的来源和简单分类
我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。

因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
2:计算机内存和网页的编码转换
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
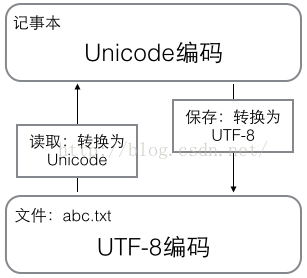
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
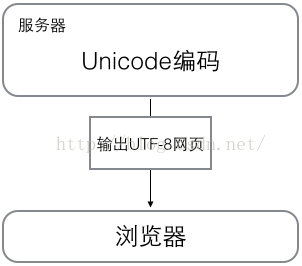
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
廖学峰的关于编码的博客:点击阅读
3:项目使用
项目环境说明:
Python2.7 + django 1.8.6 + MySQLdb + mysql 5.6
问题说明:解决中文字符的登录问题
代码片段:
<span style="font-family:Microsoft YaHei;">def login(request):
#提交表单时执行
if request.method=="POST":
#从表单获取username
name = request.POST.get("username")
#数据库连接
db,cursor = connect()
#定义sql语句,并查询
# print len(name.encode('gbk'))
sql = "select username from user"
cursor.execute(sql)
# print cursor.execute(sql)
for row in cursor.fetchall():
# print len(row[0])
#如果存在则返回主界面
if <strong>name.encode('gbk')</strong>==row[0]:
return HttpResponseRedirect("/index/index/%s" % name)
#不存在fanhuilogin并提sta示错误
return render_to_response("login.html",{
'error':"你输入的用户不存在,请重新输入",
})
#浏览器访问时执行
else:
return render_to_response("login.html",{ })</span>上边的代码是我解决问题之后的代码
首先我们看一个unicode,gbk,utf-8三种编码对于同一个汉字的显示长度
>>> len(u'我') #unicode
1
>>> len(u'我'.encode('gbk')) #gbk
2
>>> len('我') #utf-8
2
前台显示指定了UTF-8编码,但是数据传到后台后便成了unicode编码,这是因为python默认使用的是unicode编码,所以在这里我们要对传进来的参数进行编码转换
我执行的修改是: name.encode('gbk')
把传进来的参数name编程功能gbk编码,然后查询数据库进行对比就OK了
原因分析:我数据库已经修改为utf8编码了,然后建立表的时候也指定为utf-8编码,但是为什么?
这是因为我把数据从csv导入数据库时,没有指定连接的编码格式,但是一旦我置顶charset=“utf-8“时,遇到中文就会报错
网上有一种解决办法是:URL

但是我没有那样尝试,所以暂时只能在程序里传进来的参数进行gbk编码转换了
但愿以上讲的能帮到你...........














 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









