







1:Spark的运行模式
2:Spark中的一些名词解释
3:Spark的运行基本流程
4:RDD的运行基本流程
一:Spark的运行模式
Spark的运行模式多种多样,灵活多变,部署在单机上时,既可以用本地模式运行,也可以用伪分布模式运行,而当以分布式集群的方式部署时,也有众多的运行模式可供选择,这取决于集群的实际情况,底层的资源调度即可以依赖外部资源调度框架,也可以使用Spark内建的Standalone模式。对于外部资源调度框架的支持,目前的实现包括相对稳定的Mesos模式,以及还在持续开发更新中的hadoop YARN模式。
在实际应用中,Spark应用程序的运行模式取决于传递给SparkContext 的Master环境变量的值,个别模式还需要依赖辅助的程序接口来配合使用,目前所支持的Master环境变量由特定的字符串或URL组成,如下:
Local[N]:本地模式,使用N个线程
Local cluster[worker,core,Memory]:伪分布模式,可以配置所需要启动的虚拟工作节点的数量,以及每个工作节点所管理的CPU数量和内存尺寸
Spark://hostname:port :Standalone模式,需要部署Spark到相关节点,URL为Spark Master主机地址和端口
Mesos://hostname:port:Mesos模式,需要部署Spark和Mesos到相关节点,URL为Mesos主机地址和端口
YARN standalone/YARN cluster:YARN模式之一,主程序逻辑和任务都运行在YARN集群中
YARN client:YARN模式二,主程序逻辑运行在本地,具体任务运行在YARN集群中
Spark ON YARN模式图解(详细解释参考点击阅读):
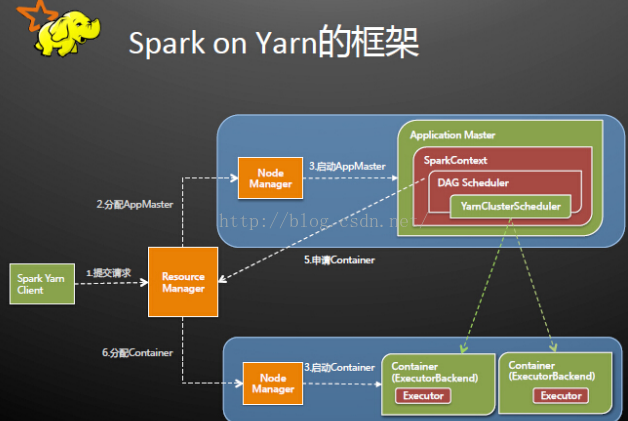
二:Spark的一些名词解释
Application:Spark中的Application和Hadoop MapReduce中的概念是相似的,指的是用户编写的Spark应用程序,内含了一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
Driver Program:Spark中的Driver即运行上述Application的main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Driver
通用的形式应该是这样的
package thinkgamer
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.SparkContext._
object WordCount{
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: WordCount <file1>")
System.exit(1)
}
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
.....//此处写你编写的Spark代码
sc.stop()
}
}Executor:Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor。在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutorBackend,类似于Hadoop MapReduce中的YarnChild。一个CoarseGrainedExecutorBackend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task。每个CoarseGrainedExecutorBackend能并行运行Task的数量就取决于分配给它的CPU的个数了
Cluster Mananger:指的是在集群上获取资源的外部服务,目前有:
Ø Standalone:Spark原生的资源管理,由Master负责资源的分配;
Ø Hadoop Yarn:由YARN中的ResourceManager负责资源的分配;
Worker:集群中任何可以运行Application代码的节点,类似于YARN中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点
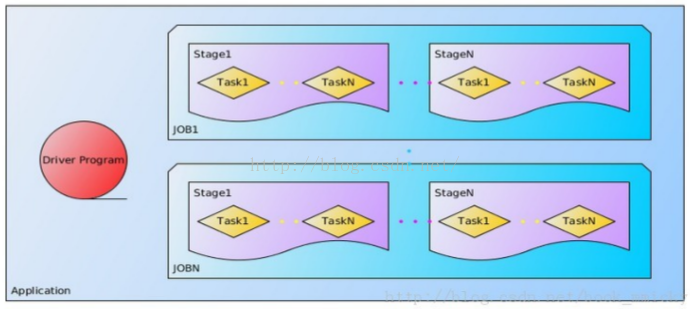
Job:包含多个Task组成的并行计算,往往由Spark Action催生,一个JOB包含多个RDD及作用于相应RDD上的各种Operation
Starge:每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段
Task:被送到某个Executor上的工作任务
三:Spark的基本运行流程
1:Spark的基本运行流程如下图:
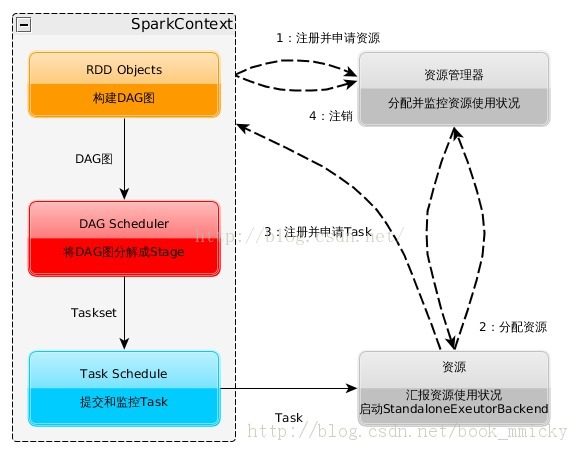
(1):构建Spark Application的运行环境,启动SparkContext
(2):SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend,Executor向SparkContext申请Task
(3):SparkContext将应用程序分发给Executor
(4):SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
(5):Task在Executor上运行,运行完释放所有资源
2:Spark运行架构的特点
(1):每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行Task。这种Application隔离机制是有优势的,无论是从调度角度看(每个Driver调度他自己的任务),还是从运行角度看(来自不同Application的Task运行在不同JVM中),当然这样意味着Spark Application不能跨应用程序共享数据,除非将数据写入外部存储系统
(2):Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了
(3):提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换,如果在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext
(4)Task采用了数据本地性和推测执行的优化机制
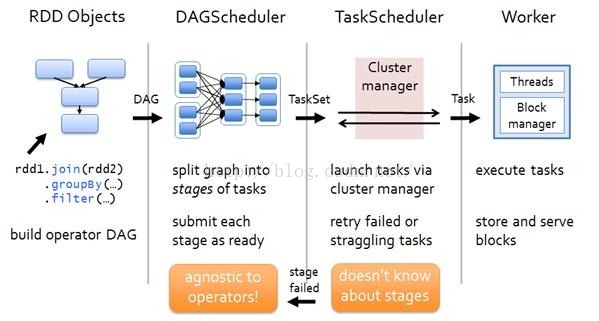
3:DAGscheduler
DAGScheduler把一个Spark作业转换成Stage的DAG(Directed Acyclic Graph有向无环图),根据RDD和Stage之间的关系找出开销最小的调度方法,然后把Stage以TaskSet的形式提交给TaskScheduler,下图展示了DAGScheduler的作用:

4:TaskScheduler
DAGScheduler决定了Task的理想位置,并把这些信息传递给下层的TaskScheduler。此外,DAGScheduler还处理由于Shuffle数据丢失导致的失败,还有可能需要重新提交运行之前的Stage(非Shuffle数据丢失导致的Task失败由TaskScheduler处理)
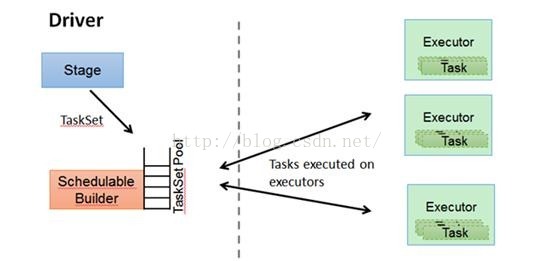
在不同运行模式中任务调度器具体为:
(1):Spark on Standalone模式为TaskScheduler;
(2):YARN-Client模式为YarnClientClusterScheduler
(3):YARN-Cluster模式为YarnClusterScheduler
四:RDD的运行基本流程
那么RDD在Spark中怎么运行的?大概分为以下三步:
1:创建RDD对象
2:DAGScheduler模块介入运算,计算RDD之间的依赖关系,RDD之间的依赖关系就形成了DAG
3:每一个Job被分为多个Stage。划分Stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个Stage,避免多个Stage之间的消息传递开销。
以下面一个按 A-Z 首字母分类,查找相同首字母下不同姓名总个数的例子来看一下 RDD 是如何运行起来的
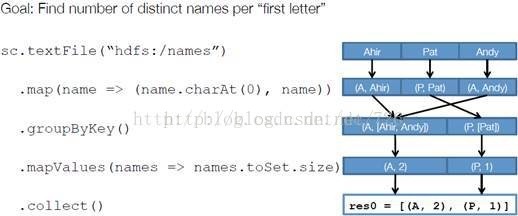
步骤 1 :创建 RDD 上面的例子除去最后一个 collect 是个动作,不会创建 RDD 之外,前面四个转换都会创建出新的 RDD 。因此第一步就是创建好所有 RDD( 内部的五项信息 ) 。
步骤 2 :创建执行计划 Spark 会尽可能地管道化,并基于是否要重新组织数据来划分 阶段 (stage) ,例如本例中的 groupBy() 转换就会将整个执行计划划分成两阶段执行。最终会产生一个 DAG(directed acyclic graph ,有向无环图 ) 作为逻辑执行计划。
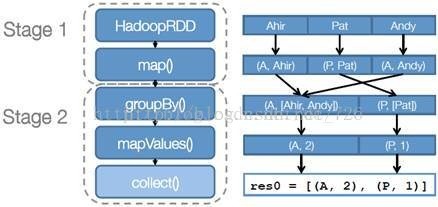
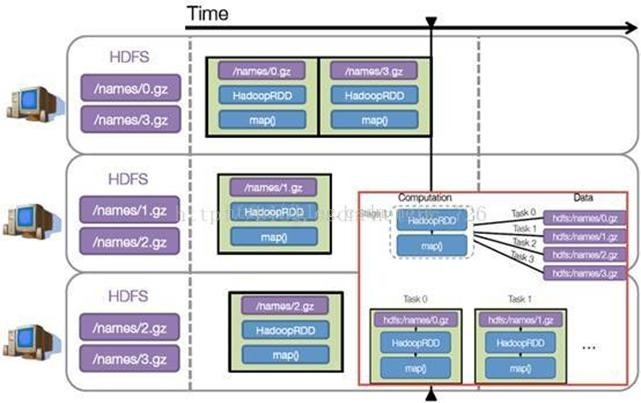
步骤 3 :调度任务 将各阶段划分成不同的 任务 (task) ,每个任务都是数据和计算的合体。在进行下一阶段前,当前阶段的所有任务都要执行完成。因为下一阶段的第一个转换一定是重新组织数据的,所以必须等当前阶段所有结果数据都计算出来了才能继续。
假设本例中的 hdfs://names 下有四个文件块,那么 HadoopRDD 中 partitions 就会有四个分区对应这四个块数据,同时 preferedLocations会指明这四个块的最佳位置。现在,就可以创建出四个任务,并调度到合适的集群结点上。














 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









