







降维系列:
---------------------
前一篇文章中介绍了主成分分析。PCA的降维原则是最小化投影损失,或者是最大化保留投影后数据的方差。在谈到其缺点的时候,我们说这一目标并不一定有助于数据的分类,换句话说,原本在高维空间中属于两类的样本,降维后可能反而不可分了。这时一种经典的降维方法是LDA,其原理是使降维后的数据间类内距离尽可能小,类间距离尽可能大。
使用LDA有个条件,就是要知道降维前数据分别属于哪一类,而且还要知道数据完整的高维信息。然而在Data Mining的很多应用下,我们是不知道数据的具体特征的(也就是高维信息),而仅仅知道数据与数据之间的相似程度。比如,在文本聚类的时候我们可以轻松知道两句话之间多么相似,但是却不一定设计出每句话应抽取什么样的特征形式。在这种应用场景下,我们要对数据进行降维,必然要尽可能保证原本相似的数据在降维后的空间中依然相似,而不相似的数据尽可能还是距离很远。解决这一问题可以采用的方法是MDS,LE,LLE等。这里我就总结总结LE(Laplacian Eigenmaps)。
还要强调一次,不是说后面每一个算法都比前面的好,而是每一种算法的降维目标都不一样,都是从不同角度去看问题。
Laplacian Eigenmaps看问题的角度和LLE十分相似。它们都用图的角度去构建数据之间的关系。图中的每个顶点代表一个数据,每一条边权重代表数据之间的相似程度,越相似则权值越大。并且它们还都假设数据具有局部结构性质。LE假设每一点只与它距离最近的一些点相似,再远一些的数据相似程度为0,降维后相近的点尽可能保持相近。而LLE假设每一个点都能通过周围邻域数据的线性组合来描述,并且降维后这一线性关系尽可能保持不变。不过这里我不主要介绍LLE,主要介绍LE,因为它在spectral clustering中被使用。
首先要构建图的权值矩阵。构建方法为:
-
1)通过设置一个阈值,相似度在阈值以下的都直接置为零,这相当于在一个 -领域内考虑局部性;
-
2)对每个点选取 k 个最接近的点作为邻居,与其他的点的相似性则置为零。这里需要注意的是 LE 要求相似度矩阵具有对称性,因此,我们通常会在 属于 的 k 个最接近的邻居且/或反之的时候,就保留 的值,否则置为零;
-
3)全连通。
以上三种方法构成的矩阵W都是对称的。按理说3会更让大家接受,但是1)和2)能够保证矩阵的稀疏性,而稀疏的矩阵对求特征值是十分方便的。不小心剧透了一下,LE的求解最终还是一个特征值分解问题。不过它和PCA不一样。怎么不一样,后面慢慢说。
LE同样把降维考虑为一种高维到低维的映射,则一个好的映射应该使连通的点靠的更近(作者注:不连通的点按理应该靠远点)。设xi映射后的点为yi,则LE的目标就是最小化以下函数:
如果采用1)和2)的方法构造矩阵,不连通的两点Wij为0,所以降维对它们没有影响。感觉有点不太合理,这不是容忍他们胡作非为么?!按理来说3)应该是更合理一些,但是3)构成的矩阵不是稀疏的╮(╯▽╰)╭。这就是一个trade-off了。而另一方面,靠的近的两个点对应的Wij大,如果降维后他们距离远了,受到的惩罚就会很大。
聪明的话你会一眼看出来:不对啊,降维后如果所有的y都等于同一个值,目标函数显然是最小的,那还搞个屁啊?当然,我们会在后面求解的时候加上这一限制条件,不允许y为一个各维相同的常量。
我们快速对目标函数进行一下整理:
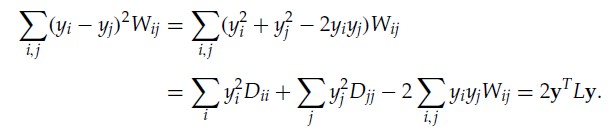
其中 ,L=D-W,L就叫做Laplacian Matrix。
于是,我们的最小化问题可以等效为:
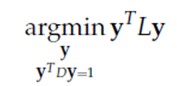
这个公式是不是就似曾相识了?和PCA的目标函数十分相似,只不过现在的目标函数是求最小值,而PCA是求最大值,约束条件也小小地变形了一下。这个目标的求解就是一个广义特征值分解问题:
说到这里,还有一个问题没有解决,就是刚才提到的“y为一个各维相同的常量”的情况。我们看,L和D都个半正定矩阵,因此特征值都应该大于等于0。可以很快证明,特征值为0时,y的取值(如果有之一的话)是一个全1的向量(可以把矩阵乘积展开来计算一下,左边因为L=D-W的减号作用,结果显然也是0的),也就是我们刚才怀疑到的这种情况。
因此,对于,我们将特征值从小到大排序后,选择第二小的特征值到第m+1小的特征值对应的特征向量(共m个),组成一个Nxm的矩阵,矩阵的每一行就是原来的数据降维后得到的m维特征。你会不会觉得很神奇,原本我们只知道数据与数据之间的相似程度,结果竟然把降维后的特征求出来了!其实求出的特征不过是个相对特征罢了,他们之间相对的距离的远近才是实际重要的,慢慢体会目标函数你就会理解了。
还要再说说这里的特征值。如果仅有一个特征值为0,那么这个graph一定是全通的。关于这个结论我们可以这样证明:
假设f是特征值0对应的特征向量,那么:
如果两个顶点是连通的,那么wij>0,为了满足上式只要让fi=fj。如果graph是连通的话,就能找到一系列w1i,wij,wjk……大于0(其中ijk….分别属于234…N中的一个数),这样就成立了f1=fj=fk=…..。换句话说,f是一个全为一个数的向量,与全1的向量是同一个向量。又因为仅有这一个向量满足条件,所以仅有一个特征值0满足全通的假设。就证明好了。
将这个结论做点推广,就是如果一个graph可以分为k个连通区域,那么特征值分解后就有k个为0的特征值。
Laplacian Eigenmap具有区分数据点的特性,可以从下面的例子看出:
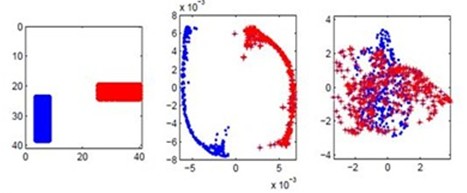
Laplacian Eigenmap实验结果。左边的图表示有两类数据点(数据是图片),中间图表示采用Laplacian Eigenmap降维后每个数据点在二维空间中的位置,右边的图表示采用PCA并取前两个主要方向投影后的结果,可以清楚地看到,在此分类问题上,Laplacian Eigenmap的结果明显优于PCA。
事实上,LE和LLE都假设数据分布在一个嵌套在高维空间中的低维流形上。Laplacian Matrix其实是流形的 Laplace Beltrami operator的一个离散近似。关于流型和Laplace Beltrami operator我也没有怎么研究过,这里就给这么一个结论给大家。大家可以参考下面给出的两篇参考文献做进一步阅读。
Further Readings:
1. Laplacian Eigenmaps for Dimensionality Reduction and Data Representation
2. A Tutorial on Spectral Clustering
-----------------
jiang1st2010
原文地址:http://blog.csdn.net/jiang1st2010/article/details/8945083
from: http://blog.csdn.net/jwh_bupt/article/details/8945083














 1435
1435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









