







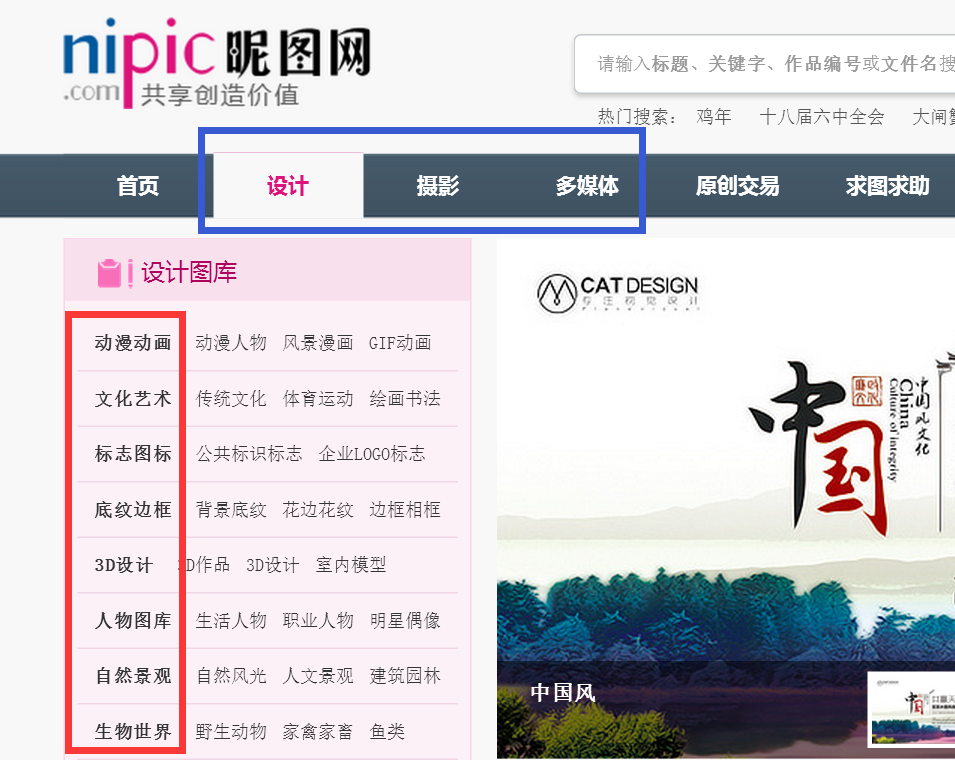
 本文介绍了使用Scrapy框架构建爬虫爬取昵图网设计、摄影、多媒体三个栏目下的高清图片的过程。涉及创建项目、定义items、编写爬虫文件、配置pipelines与settings,以及应对网站的反爬策略。通过该项目,可以学习到如何处理全站图片爬取和反爬挑战。
本文介绍了使用Scrapy框架构建爬虫爬取昵图网设计、摄影、多媒体三个栏目下的高清图片的过程。涉及创建项目、定义items、编写爬虫文件、配置pipelines与settings,以及应对网站的反爬策略。通过该项目,可以学习到如何处理全站图片爬取和反爬挑战。
Scrapy 图片爬虫构建思路为:
1. 分析网站
2. 选择爬取方式和策略
3. 创建爬虫项目--》定义items
4. 编写爬虫文件
5. 调试pipelines与settings
6. 调试
该项目的难点有:
1. 要爬取全站图片
2. 要爬取高清图片
3. 相应的反爬机制(不遵循robots协议,模拟成浏览器,不记录cookie等)
下面开始正题:
1. 创建一个爬虫项目,并定义一个spider:
cmd文件路径下使用命令:scrapy startproject nipic
路径进入刚建的nipic使用命令:scrapy genspider -t basic f1 nipic.com(定义了一个name为f1的spider)

items.py内为项目创建一个存储容器
class NipicItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()2. 分析网站,编写爬虫文件f1.py:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









