







简介
Logstash是一个开源的服务器端数据处理管道,可以同时从多个源获取数据。面对海量的日志量,rsyslog和sed,awk等日志收集,处理工具已经显的力不从心。logstash是一个整合型的框架,可以用以日志的收集,存储,索引构建(一般这个功能被ES取代)。
工作机制
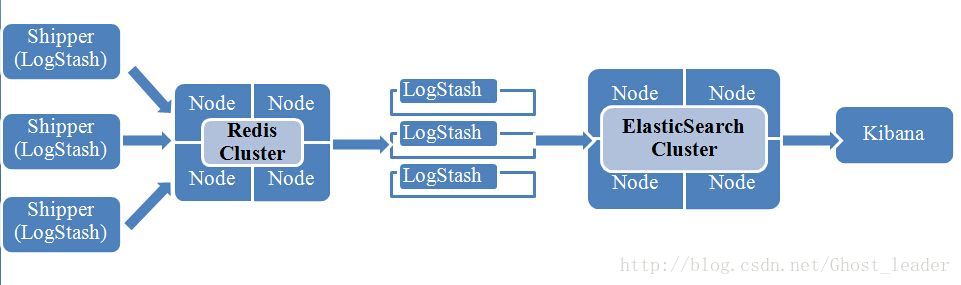
logstash 的服务器端从redis/kafka/rabbitmq等(broker)消息队列获取数据。一条数据一条数据的清洗。清洗完成后发送给elasticsearch集群。再在kibana上显示。
对于logstash而言,他的所有功能都是基于插件来完成的。input,filter,output等等都是这样。
输入插件:
提取所有的数据。 数据通常以多种格式散布或分布在各个系统上。logstash支持各种输入。可以从常见的各类源中获取事件。轻松从日志,指标,web应用程序和各种AWS服务中进行采集,所有的这些都是以连续流的方式进行。
过滤器:
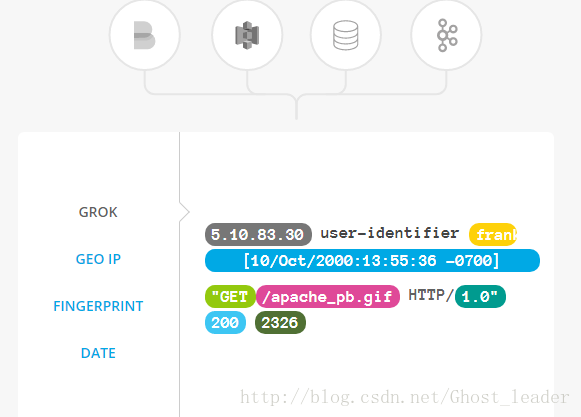
随着数据传输而来。logstash过滤器解析每一个事件,识别命名字段以构建结构。将它们转换为通用格式,从而更轻松,更快捷的分析。常用的过滤数据手段。(1)、用grok从非结构化数据导出结构。(2)、从IP地址解读地理坐标。(3)、匿名PII数据,完全排除敏感字段。 (4)、简化数据源,格式或模式。
产出:
当然,elasticsearch是首选的输出对象,但是还有很多的选项。可根据需要路由。
安装
由于Logstash使用Jruby研发,所以需要JVM。也就是需要安装java环境。其工作与agent/server模型下。
这里也简单的演示一下JAVA的环境配置。首先准备好jdk的tar包。
# mkdir /usr/java
# tar xf jdk-8u151-linux-i586.tar.gz -C /usr/java
# vim /etc/profile JAVA_HOME=/usr/java/jdk1.8.0_151
export JRE_HOME=/usr/java/jdk1.8.0_151/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH # update-alternatives --install /usr/bin/java java /usr/java/jdk1.8.0_151/bin/java 300
# update-alternatives --install /usr/bin/javac javac /usr/java/jdk1.8.0_151/bin/javac 300
# update-alternatives --config java
共有 3 个程序提供“java”。
选择 命令
-----------------------------------------------
*+ 1 /usr/lib/jvm/jre-1.7.0-openjdk.x86_64/bin/java
2 /usr/lib/jvm/jre-1.6.0-openjdk.x86_64/bin/java
3 /usr/java/jdk1.8.0_151/bin/java
按 Enter 来保存当前选择[+],或键入选择号码:3 安装logstash。在logstash官网上去下载rpm包。
# yum -y install logstash-6.1.2.rpm插件介绍
常见的插件。在诸多的input插件当中有file,udp,http,kafka,rabbitmq,beats等等
file:
文件流事件。类似与 tail -n 1 -f 开始阅读。当然也可以从头开始阅读。利用了sincedb记录文件的状态,包括文件的inode号,主设备号,从设备号,文件内字节偏移量。所以文件不能改名字。一改名字就会使用新的sincedb。
input {
file {
path => ["/var/log/messages"]
type => "system"
start_position => "beginning"
}
}
通过udp将消息作为事件通过网络读取。唯一需要的配置项是
演示一下。
port,它指定udp端口logstash将监听事件流。演示一下。
先安装 collectd(epel源中) yum -y install collectd collectd是一个性能监控程序。
编辑配置文件 /etc/collectd.conf
将想要监控的内容取消注释。 (一定要取消 network)
Hostname "node-1"
LoadPlugin syslog
LoadPlugin battery
LoadPlugin cpu
LoadPlugin df
LoadPlugin disk
LoadPlugin interface
LoadPlugin load
LoadPlugin memory
LoadPlugin network
<Plugin network>
<Server "192.168.40.133" "25826"> #192.168.40.133 是logstash监听的地址,25826 是logstash监听端口
</Server>
</Plugin>
Include "/etc/collectd.d"
启动即可。
systemctl start collectd
接下来写一个udp.conf
input {
udp {
port => 25826
codec => collectd {}
type => "collectd"
}
}
output {
stdout {
codec => rubydebug
}
}
# logstash -f udp.conf
开始收集,内容如下
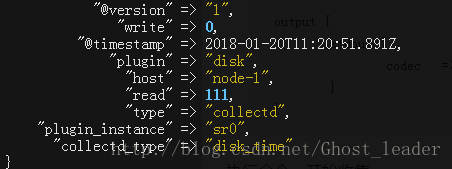
Filter插件:
用于在将event发往output之前,对其实现一定的处理功能。
grok:
用于分析并结构化文本数据。目前是logstash中非结构化数据转化为结构化数据的不二之选。可处理 syslog,Apache,nginx格式的日志。
80.91.33.133 - - [17/May/2015:08:05:41 +0000] "GET /downloads/product_1 HTTP/1.1" 304 0 "-" "Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.16)"
上面是一段nginx的访问日志。
%remote_ip 自动替换
80.91.33.133 以此类推。
%{IPORHOST:remote_ip} - %{DATA:user_name} \[%{HTTPDATE:time}\] "%{WORD:request_action} %{DATA:request} HTTP/%{NUMBER:http_version}" %{NUMBER:response} %{NUMBER:bytes} "%{DATA:referrer}" "%{DATA:agent}"
相关的预定义 语法的查阅文件,在rpm包有安装
# vim /usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns
USERNAME [a-zA-Z0-9._-]+
USER %{USERNAME}
EMAILLOCALPART [a-zA-Z][a-zA-Z0-9_.+-=:]+
EMAILADDRESS %{EMAILLOCALPART}@%{HOSTNAME}
INT (?:[+-]?(?:[0-9]+))
BASE10NUM (?<![0-9.+-])(?>[+-]?(?:(?:[0-9]+(?:\.[0-9]+)?)|(?:\.[0-9]+)))
NUMBER (?:%{BASE10NUM})
BASE16NUM (?<![0-9A-Fa-f])(?:[+-]?(?:0x)?(?:[0-9A-Fa-f]+))
BASE16FLOAT \b(?<![0-9A-Fa-f.])(?:[+-]?(?:0x)?(?:(?:[0-9A-Fa-f]+(?:\.[0-9A-Fa-f]*)?)|(?:\.[0-9A-Fa-f]+)))\b
...
%{SYNTAX:SEMANTIC}
SYNTAX : 预定义模式名称(在grok-patterns文件中定义的)
SEMANTIC:匹配到的文本的自定义标示符(匹配到后,赋值给该变量)
beats家族是很常见的。

Filebeat:
Filebeat是ELK的一部分。可以使Logstash,Elasticsearch和Kibana无缝协作。filebeat的功能是转发和汇总日志与文件。 filebeat可以读取并转发日志行,如果出现中断,还会在一切恢复正常后,从中断的位置继续开始。
beat插件(这是一个input插件)
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => "localhost:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
这一般是把数据存储下来的,有email,csv。当然还有大名鼎鼎的 Elasticsearch。这就不详细介绍了。官网上有很多的例子。
logstash指导教程














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









