







本文来自作者 来 在 GitChat 上分享 「MyBatis 源码解析:通过源码深入理解 SQL 的执行过程」,「阅读原文」查看交流实录。
「文末高能」
编辑 | 哈比
本文篇幅有点长,希望你能耐心读下去,相信不会让你失望。下面我们来开启 mybatis 的学习之旅吧。
一、目录
前言;
配置文件加载;
配置文件解析;
SQL 执行;
结果集映射;
Mybatis 中的设计模式;
总结。
二、前言
2.1 mybatis 框架图
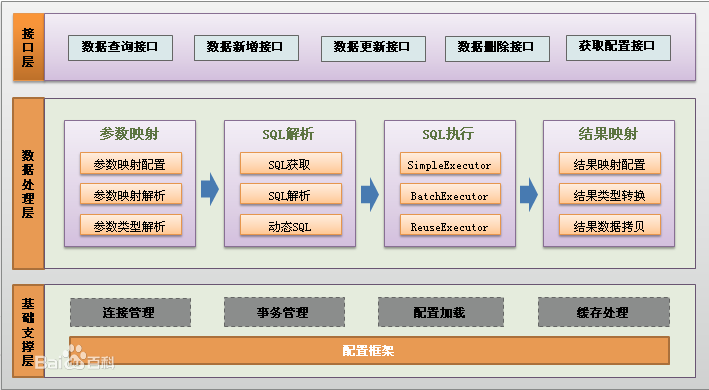
上图为 mybatis 的框架图,在这篇文章中将通过源码的方式来重点说明数据处理层中的参数映射,SQL 解析,SQL 执行,结果映射。
2.2 配置使用
<dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.4.0</version> </dependency>
获取 mapper 并操作数据库代码如下:
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml"); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder(). build(inputStream); SqlSession sqlSession = sqlSessionFactory.openSession(); LiveCourseMapper mapper = sqlSession.getMapper(LiveCourseMapper.class); List<LiveCourse> liveCourseList = mapper.getLiveCourseList();
三、配置文件加载
配置文件加载最终还是通过 ClassLoader.getResourceAsStream 来加载文件,关键代码如下:
public static InputStream getResourceAsStream(ClassLoader loader, String resource) throws IOException { InputStream in = classLoaderWrapper.getResourceAsStream(resource, loader); if (in == null) { throw new IOException("Could not find resource " + resource); } return in; } InputStream getResourceAsStream(String resource, ClassLoader[] classLoader) { for (ClassLoader cl : classLoader) { if (null != cl) { // try to find the resource as passed InputStream returnValue = cl.getResourceAsStream(resource); // now, some class loaders want this leading "/", so we'll add it and try again if we didn't find the resource if (null == returnValue) { returnValue = cl.getResourceAsStream("/" + resource); } if (null != returnValue) { return returnValue; } } } return null; }
四、配置文件解析
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
我们以 SqlSessionFactoryBuilder 为入口,看下 mybatis 是如何解析配置文件,并创建 SqlSessionFactory 的,SqlSessionFactoryBuilder.build 方法实现如下:
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties); // 解析出 configuration 对象,并创建 SqlSessionFactory return build(parser.parse());
重点为解析 configuration 对象,然后根据 configuration 创建 DefualtSqlSessionFactory。
4.1 解析 configuration
private void parseConfiguration(XNode root) { try { Properties settings = settingsAsPropertiess(root.evalNode("settings")); //issue #117 read properties first propertiesElement(root.evalNode("properties")); loadCustomVfs(settings); typeAliasesElement(root.evalNode("typeAliases")); pluginElement(root.evalNode("plugins")); objectFactoryElement(root.evalNode("objectFactory")); objectWrapperFactoryElement(root.evalNode("objectWrapperFactory")); reflectionFactoryElement(root.evalNode("reflectionFactory")); settingsElement(settings); // read it after objectFactory and objectWrapperFactory issue #631 environmentsElement(root.evalNode("environments")); databaseIdProviderElement(root.evalNode("databaseIdProvider")); typeHandlerElement(root.evalNode("typeHandlers")); mapperElement(root.evalNode("mappers")); } catch (Exception e) { throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e); } }
通过 XPathParser 解析 configuration 节点下的 properties,settings,typeAliases,plugins,objectFactory,objectWrapperFactory,reflectionFactory,environments,databaseIdProvider,typeHandlers,mappers 等节点。
解析过程大体相同,都是通过 XPathParser 解析相关属性、子节点,然后创建相关对象,并保存到 configuration 对象中。
(1)解析 properties
解析 properties,并设置到 configuration 对象下的 variables 属性,protected Properties variables = new Properties()。
(2)解析 settings
解析 settings 配置,如 lazyLoadingEnabled(默认 false),defaultExecutorType(默认 SIMPLE),jdbcTypeForNull(默认 OTHER),callSettersOnNulls(默认 false)。
(3)解析 typeAliases
通过 typeAliasRegistry 来注册别名,别名通过 key,value 的方式来进行存储,mybatis 默认会创建一些基础类型的别名。
比如 string->String.class,int->Integer.class,map->Map.class,hashmap->HashMap.class,list->List.class。别名和 class 关系通过 HashMap 来存储。
private final Map<String, Class<?>> TYPE_ALIASES = new HashMap<String, Class<?>>();
(4)解析 plugins
解析插件,然后设置 Configuration 的 InterceptorChain。
Configuration:
protected final InterceptorChain interceptorChain = new InterceptorChain();
InterceptorChain:
private final List<Interceptor> interceptors = new ArrayList<Interceptor>(); public void addInterceptor(Interceptor interceptor) { interceptors.add(interceptor); }
在创建的时候构造了拦截器链,在执行的时候也会经过拦截器链,此处为典型的责任链模式
(5)解析 objectFactory
可以自定义 ObjectFactory,对象工厂,默认为 DefaultObjectFactory。
(6)解析 objectWrapperFactory
默认为 DefaultObjectWrapperFactory。
(7)reflectionFactory
反射工厂,在通过反射创建对象时(如结果集对象),可以通过自定义的反射工厂来创建对象。objectFactory,objectWrapperFactory,reflectionFactory 这又是典型的工厂模式,将对象的创建交由相应的工厂来创建。
(8)databaseIdProvider
用来支持不同的数据库,很少在项目中用到。
(9)解析 typeHandlers
解析 TypeHandler 并通过 typeHandlerRegistry 注册到 configuration 中,通过 TYPE_HANDLER_MAP 保存 typeHandler:
private final Map<Type, Map<JdbcType, TypeHandler<?>>> TYPE_HANDLER_MAP = new HashMap<Type, Map<JdbcType, TypeHandler<?>>>();
(10)解析 mappers
读取通过 url 指定的配置文件,然后通过 XmlMapperBuilder 进行解析。
4.2 解析 mapper
解析 mapper 的入口为 XmlMapperBuilder.parse 方法,在解析的时候会解析 cache-ref,cache,parameterMap,resultMap,sql,select|insert|update|delete。
cache-ref,cache 和缓存相关,parameterMap 目前已很少使用,这里就不再说明了。
4.2.1 解析 resultMap
入口方法为 XmlMapperBuilder.resultMapElement,解析 resultMap 主要包含如下步骤:
(1)解析 resultMap 属性
解析 id,type,autoMapping 属性,type 取值的优先级为 type -> ofType -> resultType -> javaType。
String type = resultMapNode.getStringAttribute("type", resultMapNode.getStringAttribute("ofType", resultMapNode.getStringAttribute("resultType", resultMapNode.getStringAttribute("javaType"))));
(2)解析 resultMap 下的 result 子节点,创建 ResultMapping 对象。
resultMappings.add(buildResultMappingFromContext(resultChild, typeClass, flags));
解析 result 节点的 property,column,javaType,jdbcType,select,resultMap,notNullColumn,typeHandler,resultSet,foreignColumn,lazy 属性。
此处需要注意的点为:解析 select 属性与 resultMap 属性,因为这块涉及嵌套查询与嵌套映射(后面在结果集映射时会讲下这块)。如果 result 节点中存在 select 属性则认为是嵌套查询,而嵌套映射的判断条件如下:
String nestedResultMap = context.getStringAttribute("resultMap", processNestedResultMappings(context, Collections.<ResultMapping> emptyList()));
如果 result 节点存在 resultMap 则肯定是嵌套映射:
private String processNestedResultMappings(XNode context, List<ResultMapping> resultMappings) throws Exception { if ("association".equals(context.getName()) || "collection".equals(context.getName()) || "case".equals(context.getName())) { if (context.getStringAttribute("select") == null) { ResultMap resultMap = resultMapElement(context, resultMappings); return resultMap.getId(); } } return null; }
如果是 association,collection,case 这些节点,并且 select 属性为空的话,则认为是嵌套映射
(3)注册 ResultMap
通过 resultMapResolver.resolve() 来解析 resultMap 属性,然后创建 ResultMap 对象,并保存到 resultMaps 属性中。
protected final Map<String, ResultMap> resultMaps = new StrictMap<ResultMap>("Result Maps collection");
4.2.2 解析 sql
sql 解析相对简单,主要是解析 sql 节点,然后保存到 sqlFragments。
4.2.3 解析 select|insert|update|delete
入口方法为 XMLStatementBuilder.parseStatementNode,解析 statementNode 主要包含如下步骤:
(1)解析 statementNode 属性
属性主要包括 id,parameterMap,parameterType,resultMap,resultType,statementType(默认为 PREPARED,预处理的 statement)。
(2)解析 include
将 include 替换为 sql 片段,然后移除 include 节点。
(3)解析 selectKey
Parse selectKey after includes and remove them。
(4)创建 sqlSource
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
langDriver 默认为 XMLLanguageDriver,此处很重要,请允许我多列点代码:
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) { XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType); return builder.parseScriptNode(); }
XMLScriptBuilder.parseScriptNode:
public SqlSource parseScriptNode() { List<SqlNode> contents = parseDynamicTags(context); MixedSqlNode rootSqlNode = new MixedSqlNode(contents); SqlSource sqlSource = null; if (isDynamic) { sqlSource = new DynamicSqlSource(configuration, rootSqlNode); } else { sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType); } return sqlSource; }
解析动态节点:
List<SqlNode> parseDynamicTags(XNode node) { List<SqlNode> contents = new ArrayList<SqlNode>(); NodeList children = node.getNode().getChildNodes(); for (int i = 0; i < children.getLength(); i++) { XNode child = node.newXNode(children.item(i)); if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) { String data = child.getStringBody(""); TextSqlNode textSqlNode = new TextSqlNode(data); // 如果包含 ${}的话则认为是动态节点 if (textSqlNode.isDynamic()) { contents.add(textSqlNode); isDynamic = true; } else { contents.add(new StaticTextSqlNode(data)); } } else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628 String nodeName = child.getNode().getNodeName(); NodeHandler handler = nodeHandlers(nodeName); if (handler == null) { throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement."); } handler.handleNode(child, contents); isDynamic = true; } } return contents; }
如果 statement 节点下存在子节点,如 trim,if,where,那么 statement 肯定是动态节点;如果 statement 节点下不存在子节点,但是文本中包含 ${},那么也认为是动态节点。
创建 SqlSource:如果包含动态节点创建 DynamicSqlSource,否则创建 RawSqlSource。
(5)创建 MappedStatement 并注册
根据解析出的属性创建 MappedStatement 对象,然后注册到 configuration 对象中:
protected final Map<String, MappedStatement> mappedStatements = new StrictMap<MappedStatement>("Mapped Statements collection");
五、SQL 执行
在配置文件解析这一节,我们解析了 configuration,mapper 等节点,并创建了 SqlSessionFactory,下面我们就来分析下 SQL 执行的过程。
(1)创建 SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession(); final Environment environment = configuration.getEnvironment(); final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment); tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit); final Executor executor = configuration.newExecutor(tx, execType); return new DefaultSqlSession(configuration, executor, autoCommit);
因为没有和 spring 进行整合,事务为 JdbcTransaction,executor 为默认的 SimpleExecutor,autoCommit 为 false。
(2)创建 mapper 代理类
我们顺着 DefaultSqlSession.getMapper 方法来看下 mybatis 是如何创建 mapper 代理类的。
public <T> T getMapper(Class<T> type) { return configuration.<T>getMapper(type, this); } public <T> T getMapper(Class<T> type, SqlSession sqlSession) { return mapperRegistry.getMapper(type, sqlSession); } public <T> T getMapper(Class<T> type, SqlSession sqlSession) { final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type); if (mapperProxyFactory == null) { throw new BindingException("Type " + type + " is not known to the MapperRegistry."); } try { return mapperProxyFactory.newInstance(sqlSession); } catch (Exception e) { throw new BindingException("Error getting mapper instance. Cause: " + e, e); } }
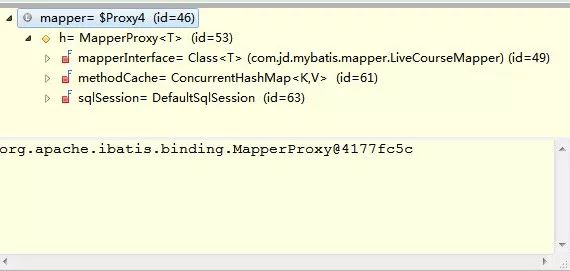
可以看到最终是会通过 mapperProxyFactory 来创建 MapperProxy 代理类,实现代码如下:
public T newInstance(SqlSession sqlSession) { final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache); return newInstance(mapperProxy); } protected T newInstance(MapperProxy<T> mapperProxy) { return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy); }
通过 jdk 动态代理来创建最终的 Proxy 代理类,最终类结构如下图所示:
(3)调用 mapper 方法
MapperProxy.invoke 方法实现如下:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { if (Object.class.equals(method.getDeclaringClass())) { try { return method.invoke(this, args); } catch (Throwable t) { throw ExceptionUtil.unwrapThrowable(t); } } final MapperMethod mapperMethod = cachedMapperMethod(method); return mapperMethod.execute(sqlSession, args); }
如果执行的是 Object 类的方法,那么直接执行方法即可;其它方法的话通过 MapperMethod 来执行。实现如下:
如果是 insert 命令,则调用 sqlSession.insert 方法;
如果是 update 命令,则调用 sqlSession.update 方法;
如果是 delete 命令,则调用 sqlSession.delete 方法;
如果是 select 命令,相对 insert,update,delete 命令来说稍微复杂些,要区分方法的返回值,如果返回 List 集合的话则调用 executeForMany,如果返回单个对象的话则调用 selectOne,返回 map 的话则调用 executeForMap。
insert,update,delete,select 命令它们实现原理都差不多,select 只是比它们多了结果集映射这一步。
我们就以 select 命令的 executeForMany 方法为例来说明 sql 的执行过程。
MapperMethod.executeMany 会调用 DefaultSqlSession.selectList,而 selectList 方法实现如下:
// 获取 MappedStatement,在 mapper 解析的时候注册到 configuration 对象中的 MappedStatement ms = configuration.getMappedStatement(statement); // 默认为 SimpleExecutor,sql 的执行类 return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
Executor.query:
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { // 获取 BoundSql,在此处处理 if,where,choose 动态节点,很重要 BoundSql boundSql = ms.getBoundSql(parameter); CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); return query(ms, parameter, rowBounds, resultHandler, key, boundSql); }
5.1 getBoundSql
public class BoundSql { private String sql; private List<ParameterMapping> parameterMappings; private Object parameterObject; private Map<String, Object> additionalParameters; private MetaObject metaParameters;
BoundSql 为最终执行的 sql,为处理完动态节点后的 sql。通过 SqlSource 来获取 BoundSql,通过前面我们了解到存在两种 SqlSource:DynamicSqlSource,RawSqlSource。
5.1.1 DynamicSqlSource.getBoundSql
public BoundSql getBoundSql(Object parameterObject) { DynamicContext context = new DynamicContext(configuration, parameterObject); rootSqlNode.apply(context); SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration); Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass(); SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings()); BoundSql boundSql = sqlSource.getBoundSql(parameterObject); for (Map.Entry<String, Object> entry : context.getBindings().entrySet()) { boundSql.setAdditionalParameter(entry.getKey(), entry.getValue()); } return boundSql; }
在 getBoundSql 时主要包含如下几个步骤:
(1)SqlNode.apply
public boolean apply(DynamicContext context) { for (SqlNode sqlNode : contents) { sqlNode.apply(context); } return true; }
在此处处理 IfSqlNode,MixedSqlNode,ForEachSqlNode,TrimSqlNode 这些动态节点。
(2)sqlSourceParser.parse
public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) { ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters); GenericTokenParser parser = new GenericTokenParser("#{", "}", handler); // 将#{}替换为 ?,解析出 ParameterMappings String sql = parser.parse(originalSql); return new StaticSqlSource(configuration, sql, handler.getParameterMappings()); }
解析 SqlSource,将#{}替换为 ?,解析出 ParameterMappings,最终生成静态的 StaticSqlSource。
public String handleToken(String content) { parameterMappings.add(buildParameterMapping(content)); return "?"; }
ParameterMapping 主要包括 property 名称,jdbcType,javaType,typeHandler。如果未指定 javaType 的话默认取得是传递的参数对象中属性的类型。
StaticSqlSource.getBoundSql 最终返回结果如下:
public BoundSql getBoundSql(Object parameterObject) { return new BoundSql(configuration, sql, parameterMappings, parameterObject); }
5.1.2 RawSqlSource.getBoundSql
RawSqlSource 相比 DynamicSqlSource 就简单多了,在创建 RawSqlSource 时直接就将 sql 解析了,getBoundSql 时直接创建 BoundSql 返回即可:
public RawSqlSource(Configuration configuration, SqlNode rootSqlNode, Class<?> parameterType) { this(configuration, getSql(configuration, rootSqlNode), parameterType); } public RawSqlSource(Configuration configuration, String sql, Class<?> parameterType) { SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration); Class<?> clazz = parameterType == null ? Object.class : parameterType; sqlSource = sqlSourceParser.parse(sql, clazz, new HashMap<String, Object>()); } private static String getSql(Configuration configuration, SqlNode rootSqlNode) { DynamicContext context = new DynamicContext(configuration, null); rootSqlNode.apply(context); return context.getSql(); } public BoundSql getBoundSql(Object parameterObject) { return sqlSource.getBoundSql(parameterObject); }
5.2 query
在上面的小节中生成了最终的 sql,下面就可以执行 sql 了。我们以 SimpleExecutor 为例来看下 sql 的执行过程:
Configuration configuration = ms.getConfiguration(); // 创建 StatementHandler,默认为 PreparedStatementHandler StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); stmt = prepareStatement(handler, ms.getStatementLog()); return handler.<E>query(stmt, resultHandler);
(1)prepareStatement
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { Statement stmt; Connection connection = getConnection(statementLog); // 设置 fetchSize,timeout stmt = handler.prepare(connection, transaction.getTimeout()); //statement.setParameter sql 实际执行参数设置 handler.parameterize(stmt); return stmt; } public void parameterize(Statement statement) throws SQLException { parameterHandler.setParameters((PreparedStatement) statement); }
最终通过 typeHandler.setParameter(ps, i + 1, value, jdbcType);来设置参数。
(2)query
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException { PreparedStatement ps = (PreparedStatement) statement; ps.execute(); //sql 执行 return resultSetHandler.<E> handleResultSets(ps); // 处理结果集 }
处理结果集也块相对也比较重要,我们单独来讲下。
六、结果集映射
方法入口为 DefaultResultSetHandler.handleResultSets,关键代码如下:
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException { if (resultMap.hasNestedResultMaps()) { ensureNoRowBounds(); checkResultHandler(); handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping); } else { handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping); } }
在处理结果集行值时分为两部分,处理简单 resultMap 对应的行值和处理嵌套 resultMap 对应的行值,是否嵌套映射在解析 mapper resultMap 的时候已经解释过了,这里不再重复。
处理简单 resultMap 对应的行值稍微简单些,我们先从简单的看起吧。
6.1 简单映射
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException { DefaultResultContext<Object> resultContext = new DefaultResultContext<Object>(); // 处理分页,跳过指定的行,如果 rs 类型不是 TYPE_FORWARD_ONLY,直接 absolute,否则的话循环 rs.next skipRows(rsw.getResultSet(), rowBounds); // 循环处理结果集,获取下一行值 while (shouldProcessMoreRows(resultContext, rowBounds) && rsw.getResultSet().next()) { ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rsw.getResultSet(), resultMap, null); // 处理行值,重点分析 Object rowValue = getRowValue(rsw, discriminatedResultMap); // 保存对象,通过 list 保存生成的对象 Object storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet()); } }
6.1.1 getRowValue
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap) throws SQLException { final ResultLoaderMap lazyLoader = new ResultLoaderMap(); Object resultObject = createResultObject(rsw, resultMap, lazyLoader, null); if (resultObject != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) { final MetaObject metaObject = configuration.newMetaObject(resultObject); boolean foundValues = !resultMap.getConstructorResultMappings().isEmpty(); if (shouldApplyAutomaticMappings(resultMap, false)) { foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, null) || foundValues; } foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, null) || foundValues; foundValues = lazyLoader.size() > 0 || foundValues; resultObject = foundValues ? resultObject : null; return resultObject; } return resultObject; }
获取行值主要包含如下 3 个步骤:
(1)createResultObject 创建结果集对象
根据 resultType,通过 ObjectFactory.create 来创建对象,其实现原理还是通过反射来创建对象。在创建对象时如果 resultMap 未配置 constructor,通过默认构造方法来创建对象,否则通过有参的构造方法来创建对象。
(2)自动映射属性
如果 ResultMap 配置了 autoMapping=”true”,或者 AutoMappingBehavior 为 PARTIAL 会自动映射在 resultSet 查询列中存在但是未在 resultMap 中配置的列。
(3)人工映射属性
映射在 resultMap 中配置的列,主要包括两步:获取属性的值和设置属性的值。
// 获取属性的值 Object value = getPropertyMappingValue(rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix); // 设置属性的值 , 通过反射来设置 metaObject.setValue(property, value);
获取属性的值:
private Object getPropertyMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException { // 获取嵌套查询对应的属性值,最终还是通过 Executor.query 来获取属性值 if (propertyMapping.getNestedQueryId() != null) { return getNestedQueryMappingValue(rs, metaResultObject, propertyMapping, lazyLoader, columnPrefix); } else if (propertyMapping.getResultSet() != null) { addPendingChildRelation(rs, metaResultObject, propertyMapping); // TODO is that OK? return DEFERED; } else { final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler(); final String column = prependPrefix(propertyMapping.getColumn(), columnPrefix); // 通过 typeHandler 来获取属性的值,如 StringTypeHandler 获取属性值:rs.getString(columnName) return typeHandler.getResult(rs, column); } }
6.2 嵌套映射
嵌套 resultMap 主要用来处理 collection,association 属性,并且 select 属性为空,如:
<resultMap id="liveCourseMap" type="com.jd.mybatis.entity.LiveCourse"> <result column="id" property="id"></result> <result column="course_name" property="courseName"></result> <!-- 通过嵌套映射来获取关联属性的值 --> <collection property="users" ofType="com.jd.mybatis.entity.LiveCourseUser"> <result column="uid" property="id"></result> <result column="user_name" property="userName"></result> <result column="id" property="liveCourseId"></result> </collection> </resultMap>
处理嵌套映射主要包括如下几个步骤:
(1)skipRows(rsw.getResultSet(), rowBounds); 同简单映射。
(2)createRowKey,根据 resultMap 下的列创建 rowKey,很有用。
在如上 liveCourseMap 配置中,mybatis 将会根据 id 列和 course_name 列的值来创建 rowKey,类似于类似于:
-1421739516:769980325:com.jd.mybatis.mapper.LiveCourseMapper.liveCourseMap:id:121:course_name:j2ee
(3)getRowValue
这块代码稍微有点绕,我通过例子来说明吧。
select l.id,course_name,u.id uid,u.user_name from jdams_school_live l left join jdams_school_live_users u on l.id = u.live_id where l.yn =1 and l.id = 121 order by course_start_time
我的 sql 很简单,查询出课程和参加课程的用户,结果集如下:
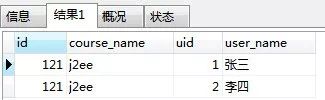
mybatis 的处理过程为:
处理第一行的值,创建 LiveCourse 对象(id=121,courseName=j2ee),同时创建 User 对象(id=1,userName= 张三),并放到 List 中,然后设置 LiveCourse 的 users 属性;
处理第二行的值,因为在第一行已经创建了 LiveCourse 对象,所以这一次不会再创建 LiveCourse 对象,根据 rowKey 来判断创没创建 LiveCourse 对象(创建完对象会保存);
创建 User 对象(id=2,userName= 李四),然后放到 List 中。
大体过程如上所述,我们再来看下相应的源码:
// 创建 rowKey,根据 rowKey 判断对应创建没创建 final CacheKey rowKey = createRowKey(discriminatedResultMap, rsw, null); // 创建的 LiveCourse 对象会保存到 nestedResultObjects Object partialObject = nestedResultObjects.get(rowKey); rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, null, partialObject); // 只有是第一次创建 LiveCourse 时才会进行保存 if (partialObject == null) { storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet()); }
getRowValue:
Object resultObject = partialObject; // 如果已经创建 LiveCoure 对象 if (resultObject != null) { final MetaObject metaObject = configuration.newMetaObject(resultObject); putAncestor(resultObject, resultMapId, columnPrefix); // 不用创建 LiveCouse 对象,直接处理嵌套映射即可 applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, false); ancestorObjects.remove(resultMapId); } else { final ResultLoaderMap lazyLoader = new ResultLoaderMap(); // 创建 LiveCoure 对象,同简单映射 resultObject = createResultObject(rsw, resultMap, lazyLoader, columnPrefix); if (resultObject != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) { final MetaObject metaObject = configuration.newMetaObject(resultObject); boolean foundValues = !resultMap.getConstructorResultMappings().isEmpty(); // 自动映射,同简单映射 if (shouldApplyAutomaticMappings(resultMap, true)) { foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues; } // 人工映射,同简单映射 foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues; putAncestor(resultObject, resultMapId, columnPrefix); // 处理嵌套映射 foundValues = applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, true) || foundValues; ancestorObjects.remove(resultMapId); foundValues = lazyLoader.size() > 0 || foundValues; resultObject = foundValues ? resultObject : null; } if (combinedKey != CacheKey.NULL_CACHE_KEY) { nestedResultObjects.put(combinedKey, resultObject); } }
在处理嵌套映射属性时,主要是创建对象,设置属性值,然后添加到外层对象的 colletion 属性中。
private void linkObjects(MetaObject metaObject, ResultMapping resultMapping, Object rowValue) { final Object collectionProperty = instantiateCollectionPropertyIfAppropriate(resultMapping, metaObject); // 如果外层对象已经有集合属性值时,直接将创建的对象添加到集合中 if (collectionProperty != null) { final MetaObject targetMetaObject = configuration.newMetaObject(collectionProperty); targetMetaObject.add(rowValue); } else { // 创建集合,然后设置属性值 metaObject.setValue(resultMapping.getProperty(), rowValue); } }
(4)storeObject
保存创建的对象,同简单映射。
七、Mybatis 中的设计模式
(1)工厂模式
SqlSessionFactory,MapperProxyFactory。
(2)动态代理
MapperProxy。
(3)组合模式
在解析 SqlNode 时使用了组合模式,MixSqlNode 相当于树枝节点,具体的 SqlNode,像 IfSqlNode,WhereSqlNode 为叶子节点。
(4)模板方法
Executor,BaseExecutor 封装了 update,select 的骨架,具体的实现交由不同的子类来实现,如 SimpleExecutor,ResumeExecutor,BatchExecutor。
(5)建造者模式
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示,建造者模式又可以称为生成器模式。XMLConfigBuilder,XMLMapperBuilder,XMLStatementBuilder。
(6)责任链模式
plugins 插件处理。
上面这几个设计模式只是 mybatis 中比较常见的设计模式,mybatis 中肯定还存在其它的设计模式,期待你的发现。
八、总结
mybatis 源码相对来说比较简单,只要抓住主脉络(mapper 解析,sql 执行,结果集映射这几大块),然后通过 debug 一步步跟下来,你也可以深入了解和理解 mybatis 中 sql 的执行过程。
由于个人时间、精力、水平有限,难免有一些遗漏和错误的地方,还请大家多多指教,谢谢。
近期热文
《修改订单金额!?0.01 元购买 iPhoneX?| Web谈逻辑漏洞》

「阅读原文」看交流实录,你想知道的都在这里














 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









