







Indexes and Index-Organized Tables(索引及索引组织表)
本章讨论index(索引),它是schema object,它能加快访问行的速度
还讨论了index-organized table(索引组织表),它是一个按照索引内部结构存放的表。
本章包含下面小节:
·索引的概述
·索引组织表(IOT)的概述
Overview of Indexes索引的概述
索引是一个可选的结构,和表或者table cluster相关联。它大部分情况可以提升数据访问的速度。
通过在表的一个或多个列上创建索引,可以增加速度(返回结果少时)。
索引也是减少磁盘I/O的手段之一。
如果堆表(普通表)没有索引,那么数据库只能执行全表扫描来获取数据。
举个例子:如果没有索引,那么在departments表查询location_id等于2700的行,数据库需要扫描这个表中每个块中的每行。然后找到该值。这种方法,数据量越大,越不合适。
打个比方,假设HR 经理有一个放着纸盒的架子。有文件夹中包含了 雇员的信息,这些文件夹随意的插在盒子里面。有一个叫Whalen(id200)的雇员信息,在盒子1的倒数第十个文件夹,而 King(id100)的文件夹则在盒子3的最后一个(杂乱无章),这时候 HR经理想找到某个人的信息怎么找呢,从盒子1 开始一个文件夹一个文件夹的看,看完再看盒子2 ,3,4…… 最后到文件夹被找到。为了加速这个访问过程,经理可以创建一个索引,这个索引根据雇员ID顺序的列出,以及附有它们的位置:
ID 100:Box 3,position 1(最后一个)
ID 101:Box7,position 8
ID 200:Box1,position 10
同样,这个经理也可以根据 雇员的名字,或者部门ID,或者其他什么的,创建索引。
普遍情况下,在下面所有情况中,可以考虑创建一个索引:
·被索引的列经常查询,而且返回表中比例非常小的值。比如返回全表5%的数据
·外键列,要创建索引。如果你DML父表的主键列,那么如果引用该父表的子表的外键列没有索引,将会发生全表lock。
·有唯一约束时,你希望手动指定索引,以及索引的选项。
Index Characteristics 索引的特征
索引是schema object,它是物理和逻辑上都独立于与它相关的表或者视图的。因此,一个索引的删除和创建,在物理上对表并没有什么影响。
提示:如果你删了索引,应用一样可以工作,但是 之前是通过索引访问表的sql,则会变慢
索引存在与否,对sql字面上并没影响。索引是快速访问单行数据的access path(访问路径).
它的作用仅仅是加速执行。
如果给与的值 是已经有索引的,则索引将直接指向包含这个值的行的物理位置。
索引在创建以后,由数据库自动维护和使用。如对于数据的修改自动响应。比如添加,更新或者删除行,索引的维护又数据库自动完成.
如果表上存在很多索引,会降低DML操作的性能,因为数据库必须对相关索引进行更新.
索引有下面的属性:
·Usability 可用性
索引可以是 可用的(默认) 也可以是 unusable(不可用的).一个不可用的索引 对于DML操作将不会维护,而且优化器也会忽略掉它.一个不可用的索引对于大块的载入数据 有加速作用.
修改索引为unusable可以省得先删了索引,载入数据,再添加索引,这个过程.(改为,设为unusable,插入数据,rebuild 这个索引)。
一个unusable的索引和其索引的分区,是不会消耗空间的。当你将一个usable的索引改为unusable时,数据库将删除它的segment。
·Visibility 可见性
索引默认是visible的。可以修改为invisible(不可见)的。一个invisible(不可见)的索引,DML操作,还是会维护它的。只不过对于优化器来说,它是不可见的,优化器默认不会使用它。
设置一个索引为invisible的作用是专门为了测试删除一个索引 对于生产的影响。如果有很大影响,再把它改回visible。如果确定没什么影响 是个多余索引,再去drop掉它。
Keys and Columns 键 and 列
索引中的 key 可以是一堆列的组合,或者一个表达式 ,虽然术语常常混着用。但是索引 和 key 简直是完全不同的。索引是一个存储在数据库中的结构,用户通过sql管理它。Key 是一个逻辑概念.
下面这个语句创建一个索引在orders表的customer_id列上:
CREATEINDEX ord_customer_ix ON orders(customer_id);
在上面的语句中,customer_id列就是索引的key。而索引自己叫ord_customer_ix.
注意:主键和唯一键自动会创建索引,但是外键上的索引需要你自己创建。
Composite Indexes组合索引
compositeindex(组合索引),也叫concatenated index,是 一个索引 在多个列上。
组合索引中的列们 按照先后顺序进行排列,它使得最合适的查询语句查询相应的数据,而且不需要回表.
组合索引可以加速SELECT 在SSELECT有where条件,这个条件相关的列 要么是 组合索引的leading列,或者 就是和组合索引所有相关的列.因此,组合索引中定义列的顺序是非常重要的.正常情况下,最常用的列放在第一位!
举个例子,假设应用经常查询 employees表中last_name,job_id 以及salary列。同样假设last_name选择性(全部行/唯一值)够高(比如主键).
你创建了索引,根据如下的列顺序
CREATEINDEX employees_id
ON employees(last_name,job_id,salary);
查询可以在三种情况下用到这个索引:1,三个列都查。2,查last_name列。3,查last_name,job_id列。 在这个案例中,如果一个查询没有last_name,那么就不会用到这个索引。
注意:在一些案例中,比如leading 列(如上面的last_name)选择性非常低,如果一个查询中没有指定leading 列,数据库也可能会使用这个索引(通过skip scan)
在一个表上,可以有多个索引。这些索引 负责不同的列。如果组合索引的话 负责相同的列,但是不同的排列顺序,也可以。
举例说明:下面俩个索引可以同时存在。
CREATEINDEX employee_idx1 ON employees(last_name,job_id);
CREATEINDEX employee_idx2 ON employees(job_id,last_name);
Unique and Nonunique Indexes(唯一索引,非唯一索引)
索引可以按照唯一,非唯一 分为两种.
唯一索引保证它相关列无法插入相同值.
举个例子:
两个雇员,不可能拥有相同的雇员ID.
因此,在唯一索引,一个值对应一个rowid。在叶子块中的数据也只按照key(一个列或者组合的列)来排序。
非唯一索引 允许相同的值存在索引
举个例子:employees.first_name列可能有多个Mike。
非唯一索引中,排序时,rowid也包含在key中进行排序。所以非唯一索引是按照key和rowid进行排序的(升序)
Oracle 数据库对于 key (一列或多列)都是空的行,不进行索引(也就是索引中不包含)
除非是bitmap索引,或者是cluster key 列的值是null时(还记得cluster table吧)
Types of Indexes(索引的类型)
Oracle 数据库提供了一些索引方法.索引可以分类为:
·B-tree indexes (B树索引)
这种索引是标准的索引类型,它们在主键列或者选择性高的列 表现非常优秀。当为组合索引事,Btree索引可以对 根据列们排序好的数据进行检索。Btree索引有以下子类型:
o Index-organized tables(索引组织表)
IOT 和堆表(普通表)是不同的,表数据自己本身就是索引好的。(按照B TREE结构)
o Reverse key indexes(反向索引)
在这种类型中,索引的key是反向的,举个例子:103存储到索引后就成301
这种类型,会把103 104 这种连续的值插入到不同的块(避免热块争用)
o Descending indexes
这种类型的索引,是按照降序进行排序的
CREATE INDEX emp_name_dpt_ix ONhr.employees(last_name ASC, department_id DESC);
类似这种用法。如果用户查last_name是按照顺序查,但是department_id却用倒序
就可以用这种索引。减少排序的步骤。
o B tree cluster indexes (cluster 索引)
这种类型的索引用在 table cluster key上。索引在这里不是指向某行,
而是指向了 值相关的块。
·Bitmap and bitmap join indexes(位图索引)
在位图索引中,一个索引条目是一个位图。这个位图指向了多行.
和b-tree索引比较,Btree中的一个索引条目则是指向了一行。
bitmap join index是一个位图索引在 好几个join的表上。
·Fuction_based indexes(函数索引)
这种类型的索引,里面的key是经过函数转化后的。比如UPPER函数
B-tree或者bitmap索引都可以成为这种类型
·Application domain indexes(应用域索引)
这种类型的索引,是创建在应用指定的域,这种物理索引,不需要使用传统的索引架构,
而且既可以存在数据库中像一个表,也可以存在 外面像一个文件。
B-Tree Indexs(Btree索引)
B-trees,balancedtrees(平衡树)的缩写。是最常见的索引。一个b-tree索引是将排好序的值分区域存放.
通过 索引key来关联一行数据或者一组数据(table cluster),B-tree索引对于查询性能有极大的提升,包括精准查询和范围查询。
下面图解了B-tree索引的架构,这个例子显示一个在department_id列上的索引,它是employees表上的外键列
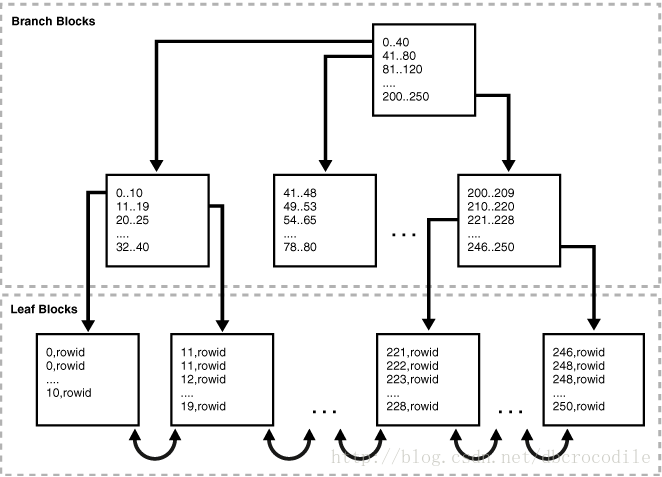
Branch Blocks and Leaf Blocks(枝干块 和 叶子块)
Btree索引有两种类型的块:branch blocks(枝干块)用来定位leaf blocks(叶子块),而叶子块存着数据..
高级别的枝干块 中包含的信息是指向低级别块的指针
如上面的图,root branch block(跟枝干块)有一个信息 0-40 , 这条信息指向的就是下一级别的枝干的最左边的块.这个最左边的块有 条目 类似与 0-10 以及 11-19 .每个条目都各自指向一个叶块.这个叶块包含的key值完全在这个范围内(0-10 或者11-19等等)
Btree索引是平衡的。因为所有的叶块都会自动的放在统一深度。因此,通过索引检索任何条目,大概时间都是一样的。
而索引的高度就是通过 root块到叶子块之间需要查询的块数。而branch level(枝干块级别)则是高度减1.
在上图中 索引的高度是3,而枝干块级别是2。
枝干块存储存储着所需的最小key前缀,用来对两个 key之间的值做转移判断。这种技术使得数据库可以在每个枝干块上尽可能多的存放entry。
枝干块包含指向叶块的指针。而叶块则包含真正的数据(key)。
包含key的数量,或者 pointer(指针)的数量 受限于block size。
叶子块包含排序后的列数据和对应的rowid,rowid用来定位到相应的行。
每个entry(条目) 根据(key,rowid)排序.在一个叶子块中,每个条目(key+rowid)都和它左边以及右边的兄弟条目连接着。叶块之间也有双向连接。
在之前的图中。最左边的叶子块(0-10)和第二个块(11-19)之间就是互相连接的!
注意:在字符类型列上的索引,排序是根据字符的二进制数据(根据数据库字符集转换)
Index scans(索引的扫描方式)
索引扫描,数据库通过扫描索引返回数据。如果数据库通过索引找到 1个列值。则它找到这个列值的I/O数等于B-tree索引的高度。这是索引背后的基本原理。
如果SQL语句只用到了索引列的值,则数据库直接从索引中读取这些值,不需要再回表。
如果语句需要的列 不光只有索引列时,则数据通过rowid找到表中的此行.基本上来说,数据库读取表中的数据是先读索引块,再通过索引块读表数据块.
Full Index Scan(扫描方式的一种)
fullindex scan方式,数据库会按照 顺序 把整个索引都读出来。 full index scan 会出现在当索引列出现在where条件中,有些情况下 不出现在where条件中也会出现。
fullindex scan 读出后不需要再排序,因为是按照顺序读出的(而索引是有序的)。
假设 一个应用运行如下的查询:
SELECT department_id,last_name,salary
FROM employees
WHERE salary >5000
ORDER BY department_id,last_name;
再假设 department_id,last_name,salary组成了一个组合索引。
Oracle数据库执行对这个索引执行index full scan,oracle会按照顺(department_id,last_name)把索引中的数据都读出,然后再根据salary进行过滤(where).
在这种情况下,直接扫描索引,不需要回表。这样数据库扫描的体积明显小于直接扫employees表,这种索引包含较多的列,并且避免的数据排序
看下面事例,full index scan读取整个索引 像下面这样:
50,Atkinson,2800,rowid
60,Austin,4800,rowid
70,Baer,10000,rowid
80,Abel,11000,rowid
80,Ande,6400,rowid
110,Austin,7200,rowid
.
.
.
Fast Full Index Scan(扫描方式的一种)
fast full index scan 是数据库读取整个索引,但不是顺序的把索引读进来(和上面的区别)
fast full index scan 是full table scan的一种变种,如果下面条件符合,则出现:
·查询中用到的列,这个索引必须都包含
·null值必须不能出现在要返回的结果集。(单列则是null,组合列则是组合起来不为null)
为了保证这个结果。必须有下面二者之一:
o NOT NULL 约束
o 查询的谓词可以保证返回的结果不包含空。
举个例子,一个应用执行了下面的查询,它没有ORDER BY 子句:
SELECT last_name,salary
FROM employees;
last_name列有not null约束,如果last name 和salary 有组合索引,那么就可以通过fast full index scan来读取整个索引 并获得上面需要的信息;
Baida,2900,rowid
Zlotkey,10500,rowid
Austin,7200,rowid
Baer,10000,rowid
Atkinson,2800,rowid
Austin,4800,rowid
.
.
.
Index Range Scan(索引扫描方式的一种)
index range scan 索引范围扫描。索引的顺序化扫描,它有以下特征:
·where子句中有索引中的列(组合索引则为一个或多个leading columns)
·0,1或更多的值可能是索引key
数据库普遍使用index range scan去访问所查询的数据。
选择率(selectivity)是指要查询的在这个表全部行的占的比例。0表示没返回行。1表示返回全部的行。选择率的概念是基于谓词的,比如 WHERE last_name LIKE 'A%',或者组合谓词(多几个条件)
谓词具有更多选择性 则返回的比例接近0,选择性不足,则返回的比例接近1
举个例子,一个用户查询雇员中 谁的last_name 由A开始。这里假设last_name列已经索引好了,索引条目如下面:
Abel,rowid
Ande,rowid
Atkinson,rowid
Austin,rowid
Austin,rowid
Baer,rowid
.
.
.
这时数据库可以选择使用index range scan 。因为last_name列在谓词中(where条件)而且多行rowid可能对应一个index key,比如 上面 有两个雇员的last_name都是Austin,Austin这个值则与两个rowid关联。
index range scan必须是一个界限范围内。可以有两个边界,比如 一个查询,department_id between 10 and 40。或者有一个边界 department_id >=10,通过 叶节点之间的双向链条扫描,直到值大于40时则停止(10 between 40时).
Index Unique Scan(索引扫描方式的一种)
和index range scan比较,index unique scan必须是一个index key 和一个rowid进行关联。
当语句谓词中涉及到的所有的列,都属于一个唯一(unique)索引,而且使用的是=号。则数据库执行unique scan 。
Index unique scan 的处理过程是,在很快找到第一条符合的记录后停止,因为不可能存在第二条记录。
像下面的这个例子,假设一个用户执行下面查询:
SELECT *
FROM employees
WHERE employee_id = 5;
假设employee_id列是主键,索引的条目如下:
1,rowid
2,rowid
4,rowid
5,rowid
6,rowid
.
.
.
在这个案例中,数据库可以使用index unique scan定位employees_id等于5的rowid。
Index Skip Scan(索引扫描方式的一种)
index skip scan是使用了 一个组合索引中的逻辑子索引(逻辑上的)。数据库的"skips",通过一个扫描一个单独的组合索引,好像它在扫描 每个列单独的索引。
Skip scanning的方式适用于,一个组合索引的leading(第一列)列 至于很少的几个唯一值,而后面的列有很多很多唯一值的时候。
当一个查询中,谓词中的列 没有包括leading列,但包含后面的列时,Oracle可能会选择index skip scan。
举个例子,假设你执行下面的查询:
SELECT * FROM sh.customers WHERE cust_email ='Abbey@company.com';
customers表有一列 cust_gender 它的值除了M 就是F。
假设有一个组合索引建立在(cust_gender,cust_email),下面是这个索引的条目
F,Wolf@company.com,rowid
F,Wolsey@company.com,rowid
F,Wood@company.com,rowid
F,Woodman@company.com,rowid
F,Yang@company.com,rowid
F,Zimmerman@company.com,rowid
M,Abbassi@company.com,rowid
M,Abbey@company.com,rowid
这时数据库使用这个索引,哪怕cust_gender这个leading列没有在where条件中。使用skip scan。
在skip scan中,逻辑子索引的数量,由leading列的唯一值的数量决定。如上面的索引条目中,leading列只有两个唯一值(F,M),则数据库逻辑(注意是逻辑)的将这个索引分割为两个子索引。
当查询有哪些雇员的email是Abbey@company.com时,数据库查询F开头的子索引,然后再查询M开头的子索引。在理论上,数据库处理这个查询类似下面这样:
SELECT * FROM sh.customers WHERE cust_gender= 'F'
ANDcust_email = 'Abbey@company.com'
UNION ALL
SELECT * FROM sh.customers WHERE cust_gender= 'M'
ANDcust_email = 'Abbey@company.com';
Index Clustering Factor(集群因子)
集群因子是用来测量索引相关的列中 行原本的顺序。顺序越乱,则集群因子越低。
集群因子是用来粗略估量通过索引查整个表的行,需要多少I/O
·如果一个索引集群因子很高,则数据库通过这个索引执行 large(大)的range scan时 I/O数会很高.因为没有顺序,所以索引条目指向的表块很随机.这样的话 数据库通过索引回表时,可能会读某个块一遍又一遍.
·如果一个索引集群因子很低,则数据库通过这个索引执行large(大)的range scan时 I/O数会很低,索引key指向的块 往往都很连续,这样数据库就不需要一遍又一遍的重复读某些块
集群因子和index scans密切相关,因为它可以显示:
·数据库进行大的范围查询时,是否会选择索引
·根据这个索引的key,看你表的组织化程度
·如果你的行,必须根据这个index key排序,则是否你需要考虑使用 IOT(index-organized table),分区,或者table cluster。
举个例子:假设employees表总共有两个数据块。下表描述了 两个数据块中的行
| Data Block 1 | Data Block 2 |
| 100 Steven King SKING ... 156 Janette King JKING ... 115 Alexander Khoo AKHOO ... . . . 116 Shelli Baida SBAIDA ... 204 Hermann Baer HBAER ... 105 David Austin DAUSTIN ... 130 Mozhe Atkinson MATKINSO ... 166 Sundar Ande SANDE ... 174 Ellen Abel EABEL ... | 149 Eleni Zlotkey EZLOTKEY ... 200 Jennifer Whalen JWHALEN ... . . . 137 Renske Ladwig RLADWIG ... 173 Sundita Kumar SKUMAR ... 101 Neena Kochar NKOCHHAR ... |
存储在块中的行,是根据last_name排序的,中间这列。
举个例子.在block1的最下面一行,是Abel的信息.往上一行是Ande的信息,
按照字母顺序以此类推 直到block 1 的第一行,Steven King.
block 2的最下面一行是Kochar的信息,往上一行是Kumar的信息,按照字母顺序以此类推直到block的最上面一行,Zlotkey的信息。
假设last_name列上有索引,每个条目都关联一个rowid。理论上来说,索引的条目看起来像下面这样:
Abel,block1row1
Ande,block1row2
Atkinson,block1row3
Austin,block1row4
Baer,block1row5
.
.
.
假设employee_id列也有个索引,理论上来说,这个索引看起来像下面这样。ID 分布起来几乎是随机的:
100,block1row50
101,block2row1
102,block1row9
103,block2row19
104,block2row39
105,block1row4
.
.
.
下面的语句是通过ALL_INDEXES视图,查询到上面两个索引的集群因子,EMP_NAME_IX的集群因子是低的(last_name列),它意味着一个索引叶块中邻近的条目,指向的rowid,往往都在一个块中。
EMP_EMP_ID_PK的集群因子是高的,它意味着索引叶块中的临近条目,指向的rowid不太可能指向同一个块。

ReverseKey Indexes(反向索引)
反向索引是B-tree索引的一种类型,它对每个index key的bytes 物理的进行反转,然后按照顺序排列。
举个例子:如果一个索引key是20.如果在正常索引中,按照十六进制来存储这个key是C1,15。那么反向索引中,将把这个key存储为15,C1。
反向存储key解决了一个问题。就是叶块的争用问题。这个问题在RAC中 尤其明显,特别是多个instance重复的修改相同块。
举个例子:orders表的主键是连续的,一个instance在表中添加 order 20.而这时另外一个instance添加order 21.这时每个instance都要写它的key到索引的相同叶块中
在反向索引中,反向的key的16进制bytes。将顺序的值 不顺序的插入到一个块,而是插入到不同的块中。
举个例子:
keys 比如是20 和21,它们在普通索引中,是邻近的,存在一个块中。而现在则被远远的分开存放到不同的块,这样顺序值插入时的I/O就被平均分配了
因为反向索引中数据存储时 并没有根据key的顺序,所以反向key排序 的索引,不能进行正常的 range scan。
举个例子:如果用户查询 订单ID 大于20的。则数据库没办法先找到这个ID,然后水平扫过后面的所有叶块。(因为物理存放的顺序并不是这样的)
Ascending and DescendingIndexes(升序索引,降序索引)
升序索引中,数据是按照升序来存储的。默认情况下,字符数据是根据二进制数据排序的,
数值数据从最小到最大排序,日期是按照最前到最后排序。
举个升序索引的例子。研究下面的SQL语句:
CREATE INDEX emp_deptid_ix ONhr.employees(department_id);
Oracle数据库排序hr.employees上的department_id列。
数据库加载升序索引,按照升序的方式获得department_id值和相对应的rowid, 从0开始。
当数据库使用到索引,oracle数据库将查询 排序好的departmeent_id值,使用与之关联的rowid定位相应的行
如果在CREATE INDEX语句中指定了DESC关键字,这时创建的就是降序索引。
在这种情况下,索引中列值是按照降序排列的。如果列值中最大是250.最小是0
在降序索引中,250处于树的最左边叶块, 而0则在最右边叶块。
默认扫描降序索引的顺序是 从最大 到最小。
一个查询中,根据两列排序,第一列根据升序,第二列根据降序。这时使用降序索引。
举个例子:假设你创建一个组合索引在last_name,department_id列
CREATE INDEX emp_name_dpt_ix ON hr.employees(last_nameASC,department_idDESC);
如果用户查询hr.employees,根据last_name升序,以及department_id降序排列。则数据库可以选择使用这个索引去检索数据 避免了再去排序的这么一步。
Key Compression(键压缩)
Oracle数据库可以使用 键压缩 去压缩主键列(可以是组合主键中的某列,也可以是全部列)在索引中的值,或者在IOT中的值
键压缩 可以极大的减少索引占用的存储。
通常情况下,索引keys 有两个片,grouping piece 和 unique piece。键压缩将索引key分裂成两部分,一部分变成 prefix entry(前缀条目,也就是grouping piece),一部分变成 suffix entry(后缀条目,也就是unique piece,或者接近unique piece)
数据库完成压缩的方式是,一个索引块中的所有 后缀条目,全都共享一个前缀条目
注意:如果一个key没有 unique piece,那么数据库将提供一个(追加一个rowid到
默认情况下,唯一索引的prefix(前缀),除了最后一列的value,其他列的都包括。
而非唯一索引的prefix(前缀),则把所有列值都包含进去。
举个例子:
假设你创建一个组合索引
CREATE INDEX orders_mod_stat_ix ON orders(order_mode,order_status);
order_mode,order_stats列中有很多重复的值,这个索引的索引条目如下:
online,0,AAAPvCAAFAAAAFaAAa
online,0,AAAPvCAAFAAAAFaAAg
online,0,AAAPvCAAFAAAAFaAAl
online,2,AAAPvCAAFAAAAFaAAm
online,3,AAAPvCAAFAAAAFaAAq
online,3,AAAPvCAAFAAAAFaAAt
看上面,key prefix(键前缀)会包括 order_mode 和order_status列的组合值。
如果这个索引根据默认 键压缩的方式创建,则重复值 prefix 将被压缩。在理论上,数据库完成压缩后,像下面这种:
online,0
AAAPvCAAFAAAAFaAAa
AAAPvCAAFAAAAFaAAg
AAAPvCAAFAAAAFaAAl
online,2
AAAPvCAAFAAAAFaAAm
online,3
AAAPvCAAFAAAAFaAAq
AAAPvCAAFAAAAFaAAt
上面的rowid就是 suffix(后缀)压缩后的样子。每个后缀关联着一个前缀,前缀和后缀存放在一个index 块中。
或者,你可以指定在创建 键压缩索引的时候指定前缀长度
举个例子:如果你指定前缀长度为1,则这里的前缀 将变成order_mode,而后缀将编程order_stats,rowid. 如下:
online
0,AAAPvCAAFAAAAFaAAa
0,AAAPvCAAFAAAAFaAAg
0,AAAPvCAAFAAAAFaAAl
2,AAAPvCAAFAAAAFaAAm
3,AAAPvCAAFAAAAFaAAq
3,AAAPvCAAFAAAAFaAAt
这时只把 order_mode的重复值进行压缩了。
索引叶块中,一个前缀 最多只能存储一次。
只有B-TREE索引中 叶块中的键值可以被压缩,枝干块中的键值前缀可以被截断,但是不能被压缩
Bitmap Indexes(位图索引)
位图索引中,数据库会给每个index key 都会生成一个位图。在传统的B-tree索引中,一个索引条目指向的是 一行。 而在bitmap索引中,每个index key存着指针,指向多行。
Bitmap 索引主要为了 数据仓库类型设置,以及 有很多列进行合并查询的时候(特殊情况)
在下面情况下,可能会需要一个位图索引:
·索引列的cardinality很小,cardinality:列总唯一值 对比表中全部行数
·索引表是只读的,或是有很少的DML操作。
举一个数据仓库的例子:
sh.customer表有一个cust_gender列,这个列只有两种值:M或者F。
假设对于这个表的查询,基本都是查询指定 gender 雇员的数量。
这种情况下customer.cust_gender列就可以考虑使用bitmap index
bitmap上的每个bit,都指向一个可能的rowid.如果这个bit是1,那么相关rowid指向包含这个位图相应key的行.
有一个mapping 函数 用来将bitmap中bit的位置 转换 真正的rowid,
这样bitmap 索引就能提供和B-tree索引相同的功能(通过不同的内部过程实现)
如果bitmap索引列的 某一行被修改了,那么数据库将 对这个key相关的 索引条目(上面的bitmap)进行加锁. 而不是只锁这个bit.
因为一个索引条目指向很多行,DML操作将把这些行全部进行加锁.
正是因为这个原因,bitmap索引不适用于OLTP应用.
Bitmap Indexes on a SingleTable(在单表上的bitmap索引)
下面例子是一个查询(sh.customers表)。
这个表上的很多列都可以考虑加bitmap 索引。

cust_marital_status和cust_gender列 都是低cardinality(基数),而cust_id 和cust_last_name则不是这样。
因此,bitmap索引可以适用于cust_marital_status和cust_gender列。
而bitmap索引不适用于其他列,一个b-tree索引(唯一b-tree索引)在这些列可能会提供更好的检索速度和表现(比如不怕DML)。
下图描述了上面例子中 cust_gender列的bitmap 索引。它有两个bitmap。每个gender值对应一个:
简单的bitmap描述
| Value | Row 1 | Row 2 | Row 3 | Row 4 | Row 5 | Row 6 | Row 7 |
| M | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| F | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
bitmap中的bit 通过mapping函数转换为customers表的rowid。每个bit都和表上的一行相关联。
举个例子:M值的位图 第一个bit是1,这说明customers表中的第一行,gender是M。
而2,6,7都是0 则表示这些行的gender列不是M值。
注意:bitmap索引,null值可以被包含进来。这里就与B-tree索引不同.索引的这些null值对于一些sql语句还是有用的。比如使用count时。
一个分析员研究客户的人口结构变化趋势时可能会问:“有多少女客户的单身或者离婚的?”
这个问题对应下面的sql:
SELECT COUNT(*)
FROM customers
WHERE cust_gender = 'F'
AND cust_marital_status IN ('single', 'divorced');
bitmap索引可以非常效率的处理这个查询(把返回的bitmap中是1的计算一下就行了),像下面的图解释的一样。
如果要定义看哪些用户满足这些条件,Oracle数据库可以使用返回的bitmap去访问表中的数据。
| Value | Row 1 | Row 2 | Row 3 | Row 4 | Row 5 | Row 6 | Row 7 |
| M | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| F | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
| single | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| divorced | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| single or divorced, and F | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
bitmap 索引可以非常效率的合并WHERE中的几个条件。
比如有部分条件可以使用bitmap索引,这时这部分可以使用的条件 会在回表之前就被过滤掉了。这项技术显著的提升了响应时间。
Bitmap Join Indexes(位图join索引)
bitmap join 索引是一个bitmap索引,建立在两个或者多个表的join上。索引中key指向的是索引表的行(因为索引段没在索引表中),而标准的bitmap索引 只指向一个表。
在执行join时,bitmap join是有效减小执行时数据大小的手段。
举个例子:
当bitmap join 索引可用时,假设用户经常查询指定 join类型的雇员数量时
标准的语句看起来如下:
SELECT COUNT(*)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id
AND jobs.job_title = 'Accountant';
上面的查询会使用jobs.job_title的索引,检索Accountant的行,以及使用employees.job_id的索引去寻找匹配的行。
为了使得可以直接在索引本身检索数据,而不回表,你就可以创建一个 bitmap join索引:
CREATE BITMAP INDEX employees_bm_idx
ON employees (jobs.job_title)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id;
看下图。索引 key 是jobs.job_title 以及 索引表 是employees.
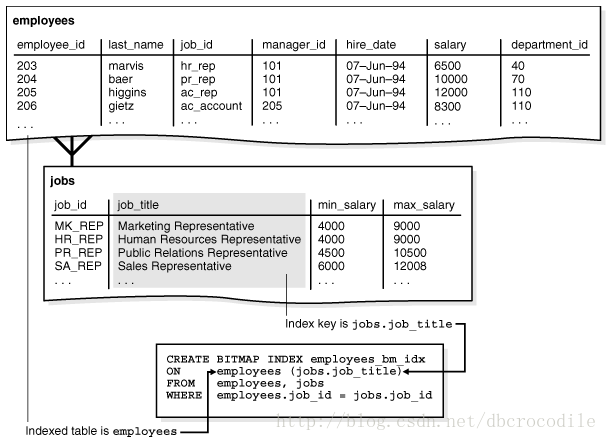
理论上,employees_bm_idx是jobs.title列的索引,像上面那个sql显示的。
索引中的job_title key指向了employees表的行
下面这个查询可以使用这个索引去避免回到employees和jobs表,因为索引本身已经包含了需要的信息。
SELECT jobs.job_title AS"jobs.job_title", employees.rowid AS "employees.rowid"
FROM employees, jobs
WHERE employees.job_id = jobs.job_id
ORDER BY job_title;

在数据仓库中,在dimension(维度)表的主键 和 fact(事实)表外键之间有 等式join.
这时bitmap join 往往比物化视图速度要快,也可以作为materializing(物化)连接的替代
Bitmap Storage Structure(bitmap 存储结构)
Oracle数据库使用B-tree索引结构 来存储每个key的bitmaps。
举个例子:如果jobs.job_title是bitmap 索引的key 列,那么索引的数据会存储成一个b-tree结构,而bitmaps将存储在叶块。
假设jobs.job_title列有唯一值 Shipping Cleark,Stock Clerk以及一些其他的。
则这个索引的索引条目将由以下几个部分组成:
·job_title的值是key
·一个rowids范围(从低到高)
·这个rowids范围的bitmap
理论上,这个索引中索引的叶块中的条目,长的如下:
Shipping Clerk,AAAPzRAAFAAAABSABQ,AAAPzRAAFAAAABSABZ,0010000100
ShippingClerk,AAAPzRAAFAAAABSABa,AAAPzRAAFAAAABSABh,010010
StockClerk,AAAPzRAAFAAAABSAAa,AAAPzRAAFAAAABSAAc,1001001100
StockClerk,AAAPzRAAFAAAABSAAd,AAAPzRAAFAAAABSAAt,0101001001
Stock Clerk,AAAPzRAAFAAAABSAAu,AAAPzRAAFAAAABSABz,100001
.
.
.
看,相同的job_title出现在多个条目中,它们的rowids指向的范围是不一样的。
假设一个用户更新一个雇员的job_id信息 从Shipping clerk 到Stock Clerk
在这种情况下,这个用户需要独占访问 这行所处的Shipping Clerk的位图范围,以及新值Stock Clerk的位图范围。
Oracle数据库将把这两个条目指向的所有行都上锁(这里可不是说Accountant指向的所有行都上锁,而是只有rowid所在的这个条目指向的行上锁),直到update结束。
bitmap索引的数据存放在一个segment中。Oracle数据库对每个bitmap都存放成一个或多个片。每片占用一个block的一部分。
Function-Based Indexes(函数索引)
你可以创建索引在一个或多个使用了函数或者表达式的列上。
函数索引将会把函数和表达式的值计算出来,然后存进索引。
函数索引可以是B-TREE 也可以是Bitmap
函数索引,既可以是使用了函数的列,也可以是使用了 算术符的列,或者是使用了算术符的函数列,可以是用户自定义的函数,举个例子:一个函数打算把两个列的值给加起来。
Uses of Function-BasedIndexes(函数索引的使用)
语句的where中使用了函数时,函数索引非常好用
函数索引,只在查询的时候使用。DML语句时不会使用,这时候使用还是要经过运算的。
举个例子,假设你创建了下面的函数索引:
CREATE INDEX emp_total_sal_idx
ONemployees (12 * salary * commission_pct, salary, commission_pct);
数据库在处理下面查询的时候会使用到
SELECT employee_id, last_name, first_name,
12*salary*commission_pct AS "ANNUAL SAL"
FROM employees
WHERE (12 * salary * commission_pct) < 30000
ORDER BY "ANNUAL SAL" DESC;

函数索引也可以定义在SQL函数UPPER(列名)或者LOWER(列名) 来优化大小写不敏感的查询。
举个例子:
假设employees表的first_name列是混合大小写字符串。
你创建了下面的函数索引:
CREATE INDEX emp_fname_uppercase_idx
ON employees(UPPER(first_name));
emp_fname_uppercase_idx索引可以加速 类似于如下的查询:
SELECT *
FROM employees
WHERE UPPER(first_name) = 'AUDREY';
函数索引同样可以用在 比如说 只对特定的行进行索引。
举个例子:
customers表的cust_valid列的值,不是I 就是A。
如果想只对A进行索引,你可以参见如下,把不是A的其他值都返回成NULL,这样就只对A进行索引了:
CREATE INDEX cust_valid_idx
ON customers(CASE cust_valid WHEN 'A' THEN 'A' END);
Optimization withFunction-Based Indexes(函数索引的优化)
优化器可以对函数索引使用 index range scan。
range scan访问路径 在谓词(where条件)过滤后返回结果集很少时 是非常有效的
在上面的查询中,优化器就可以使用index range scan(如果索引建立在12*salary*commission_pct)
virtual column(虚拟列)在使用时会衍生(用到才会计算出值)
举个例子:你可以使用12*salary*commission_pct 定义一个virtual column叫annual_sal,
然后在这个这个列上面创建索引。这个索引也是函数索引。
优化器执行表达式匹配时会先分析sql语句中的表达式,然后和函数索引中的表达式树进行比较。这个比较是大小写不敏感 以及会忽略空格的。
Application Domain Indexes(应用域索引)
应用域索引 是针对一个应用定制的索引。
Oracle 数据库提供 extensible indexing(可扩展的索引)执行以下操作:
·调节索引在定制的,复杂的数据类型建立,比如文档,空间数据,图片,音频等。
·利用专门的索引技术
你可以把 特定应用索引 管理程序封装成一个 indextype(索引类型)object。 以及定义一个域索引在表的字段上或者对象类型的属性上。
可扩展索引可以有效的处理应用特殊的operators(操作符)
应用软件,称为cartridge,控制着域索引的结构和内容。数据库和应用进行互动 去创建,维护以及扫描域索引。索引结构本身 可以作为一个IOT存在数据库中,或者作为文件存在操作系统上。
Index Storage(索引的存储)
Oracle数据库存储索引数据到 index segment。数据块中可用的空间是 块大小减去块头,每个条目的头部,rowid,以及1个byte的key宽度
Index segment可以存在默认的表空间,也可以在创建的时候指定一个表空间。
为了方便管理,你可以创建一个单独表空间,专门用来放索引
比如说,你可以选择不备份存放索引的这个表空间,因为索引可以重建。
这样可以减少备份存储的大小 以及备份的时间。
Overview of Index-OrganizedTables(索引组织表简介)
Index-organized table(IOT)是一个表,但数据 按照索引的结构存放。
在heap-organized table(普通堆表)中,如果插入数据,是哪里有空,它们就插在哪,没有顺序可言。
而在IOT中,行将存储在由表之间定义的索引中。这个B-TREE索引中的索引条目,除了key值外,还会存放其他列的值。因此IOT中,数据就是索引,索引就是数据。
应用程序 操作 IOT的时候 就像操作 普通表一样,用SQL语句。
举一个IOT的类似例子:
比如说 人力资源经理有一个 书架,上面放着一堆盒子。每个盒子都有标记,1,2,3,4等等。但是盒子并不是按照顺序排列防止的。代替它的是 每个盒子都有一个指针,指向下个盒子在书架上的位置。
每个盒子中的 每一个文件夹 都包含一个雇员的信息。文件夹按照雇员ID排列。
比如有个叫KING的雇员,它的雇员ID是100,这是最小的ID。所以它的文件夹放在第一个盒子的最底部。而id等于101的则在它上面。102的在101的上面,以此类推直到盒子1满了。则下一个文件夹将放到 第二个盒子的底部。
在这个例子中,因为文件夹本身就是按照雇员ID排序的,这就使得 可以不通过单独的一个索引,也能够快速的找到文件夹。假设用户需要雇员107,120 ,122的信息。
以前 第一步 先找目录,第二部 根据目录中的信息找到文件夹。通过IOT可以直接在表中找,省去了一步。
IOT提供了通过主键或者主键的前半部分来快速访问表的功能。而所有非key列也进入了叶块,这样减少一个回表的I/O。
举个例子:employee 100 的salary 也存在索引本身。同样的,因为行是根据主键的顺序排列的,index range scan 主键或者主键的前缀,I/O是最小的。其他优点就是避免了单独一个主键索引的开销。
IOT用在 相关的数据必须存在一起时,或者数据必须有序的存储起来
这种类型的表进程用在信息的检索,空间数据,OLAP时。
Index-Organized TableCharacteristics(IOT的特征)
数据库系统 执行在IOT表上的操作,都是在对B-tree 索引结构进行操作。
下面的表总结了IOT和普通表之间的区别。
| Heap-Organized Table | Index-Organized Table |
| The rowid uniquely identifies a row. Primary key constraint may optionally be defined. | Primary key uniquely identifies a row. Primary key constraint must be defined. |
| Physical rowid in ROWID pseudocolumn allows building secondary indexes. | Logical rowid in ROWID pseudocolumn allows building secondary indexes. |
| Individual rows may be accessed directly by rowid. | Access to individual rows may be achieved indirectly by primary key. |
| Sequential full table scan returns all rows in some order. | A full index scan or fast full index scan returns all rows in some order. |
| Can be stored in a table cluster with other tables. | Cannot be stored in a table cluster. |
| Can contain a column of the LONG data type and columns of LOB data types. | Can contain LOB columns but not LONG columns. |
| Can contain virtual columns (only relational heap tables are supported). | Cannot contain virtual columns. |
下图显示了IOT 表(departments)表的结构。叶块包含了整行,根据主键排序
举个例子
第一个叶块中的第一个行,显示了部门编号是20,部门名称叫Marketing,领导的编号是201
位置编号是1800.
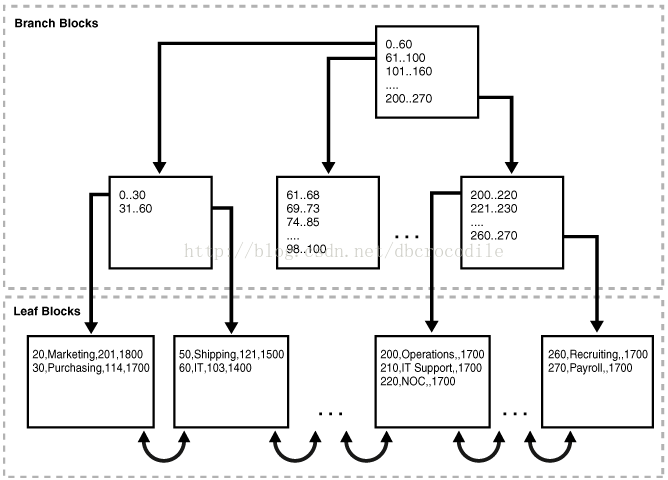
IOT 把数据按照统一结构进行存储。而且不需要存储rowid。
上面图显示了,块1在IOT中,包含的条目如下(按照主键排序):
20,Marketing,201,1800
30,Purchasing,114,1700
IOT中的叶块2包含条目如下:
50,Shipping,121,1500
60,IT,103,1400
扫描IOT中块的顺序,会按照如下顺序:
1. Block1
2. Block2
对比起来,看看普通表的访问,假设普通堆表departments块1显示如下:
50,Shipping,121,1500
20,Marketing,201,1800
块2包含的行显示如下:
30,Purchasing,114,1700
60,IT,103,1400
一个B-tree索引的叶块,包含如下条目,第一个值是主键,第二个值是rowid:
20,AAAPeXAAFAAAAAyAAD
30,AAAPeXAAFAAAAAyAAA
50,AAAPeXAAFAAAAAyAAC
60,AAAPeXAAFAAAAAyAAB
而通过这个主键进行索引扫描的顺序是这样的:
1. Block1
2. Block2
3. Block3
4. Block4
因此,在这个案例中,普通表通过主键访问的I/O数量是 IOT表的两倍!
Index-Organized Tables withRow Overflow Area(IOT和OverflowArea(溢出区))
当创建一个IOT,你可以指定单独指定出一个segment,叫row overfolw area(行溢出区)。
在IOT中,B-TREE 的条目可能很大,因为它们把整个行的内容都包含进去了,所以,可以有一个单独的segment专门用来存放这些条目,这样B-TREE条目就变小。
如果row overflow area被指定创建。数据库 会把IOT表中的一行,拆分成两个部分储存:
·The index entry(索引条目)
这一部分包含主键列的值,指向overflow部分的物理rowid,还可以选择存放进来一些非主键列的值(可选)
这一部分存放的类型是 index segment
·The overflow part(overflow 部分)
这一部分包含剩下的列,这部分存放在overflow storage area segment(table segment)
Secondary Indexes onIndex-Organized Tables(在IOT表上创建别的索引)
secondary index 就是在IOT上的另外创建了一个索引。在某种意义上来说,它是在索引上创建的索引。
secondary index是一个独立的schema object。它和IOT是分别独立存放的。
像在“Rowid Data Types”中解释的那样。IOT表中的rowid,叫逻辑ROWID
一个逻辑ROWID就是IOT表主键经过64位加密的一串代码。
逻辑ROWID的长度取决于主键的长度。
IOT中的行,不需要想普通堆表中行一样需要迁移,插入叶块中行可以在块内和块之间进行移动。因为IOT中的行没有一个永久的物理地址,而是使用基于主键的逻辑rowid。
举个例子:假设departments表是一个IOT。location_id列存储了每个部门的id。表存储的行如下,最后一列就是location_id:
10,Administration,200,1700
20,Marketing,201,1800
30,Purchasing,114,1700
40,Human Resources,203,2400
secondary index在location_id列,会有一下条目,紧跟着key的值就是逻辑rowid:
1700,*BAFAJqoCwR/+
1700,*BAFAJqoCwQv+
1800,*BAFAJqoCwRX+
2400,*BAFAJqoCwSn+
Secondary 索引的存在,在使用IOT 非主键列做条件时 也能快速访问了
举个例子:
查询department_id大于1700的部门名称。就可以使用这个secondary index了。
Logical Rowids and PhysicalGuesses(逻辑rowid和 物理guess)
Secondary索引使用逻辑rowid来定位IOT中的行。一个逻辑rowid包括了一个物理guess
物理guess,当这个索引第一次创建(或一个新的条目第一次插入)。oracle数据库可以使用物理guess去直接找到IOT表的叶块。不需要经过主键扫描。不过当行的物理地址发生变化时,物理guess将失效,不过逻辑rowid依然生效(哪怕物理guess已经失效了)。
在普通堆表中,通过索引访问 包括 扫描索引的I/O,以及一个附加的I/O(回表)。
在IOT中,通过索引访问情况是不同的,根据物理guess时候精确可用分下面几种:
·如果物理guess不可用,访问包括两个索引扫描 1.扫描索引。2.扫描IOT的主键
·如果物理guess可用,访问根据它们的精确度分下面几种情况:
o 如果物理guess精确,访问包括扫描索引的i/o 再附加一个回表I/O
o 如果物理guess不精确,则访问包括扫描索引的I/O,再加一个错误的回表I/O(通过不准确的guess回表),然后再加nique scan 扫描 IOT表的主键的I/O
Bitmap Indexes onIndex-Organized Tables(IOT上面的位图索引)
创建在IOT上的辅助索引可以是bitmap索引。
当bitmap 索引创建在IOT上时,所有的bitmap索引都是使用一个mapping table(堆表)。
mapping table存储这IOT表的逻辑rowid,每个mapping table 行 存储着一行逻辑rowid
数据库访问bitmap索引 通过搜索一个值,如果数据库找到这个值,那么bitmap 条目会转换成物理rowid。
在堆表(普通表)中,数据库通过物理rowid去访问表
在IOT中,数据库使用物理rowid去访问mapping table,它将转换成逻辑rowid ,然后去访问IOT。看下图:
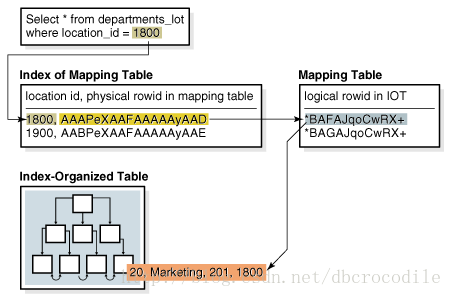
注意:IOT中行的移动,不会导致上面的bitmap索引失效。
---------------------------------------------------------------------------------------
勤学如春起之苗,不见其增日有所长。辍学如磨刀之石,不见其损日有所亏
Email: orahank.dai@gmail.com
QQ: 88285879














 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









