







recognition. 2014. (Citations: 1977).
1 Motivation
Handle detection as classification. However, it needs to test many positions and scales, and use a computationally demanding classifier (CNN). Therefore, we only look at a tiny subset of possible positions selected by region proposal methods.
Region proposals are like class-agnostic object detector. They find “blobby” image regions that are likely to contain objects. For example, selective search does bottom-up segmentation. It starts with raw image pixels, and in each step it merges adjacent pixels together if they have similar texture and color. The blobby-like regions are formed. At each scale, it converts regions to bounding boxes.
2 Pipeline
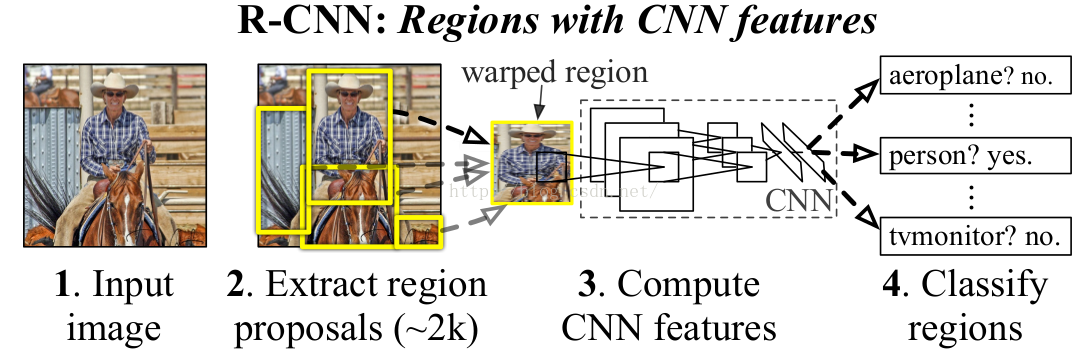
See Fig. The pipeline is as followings:
1. Fine-tuning. Download a ImageNet pre-trained model and throw away final fc layer. Reinitialize the final fc layer (20 + 1 output, 1 for background) from scratch and keep
training model using positive/negative regions from detection images. Positive regions are those which have ≥ 0.3 IoU overlap with a ground-truth box. Otherwise it is negative.
2. Extract features. Extract region proposals for all images (2 k category-independent region proposals per image). Then for each region proposal, warp it to the CNN input size, forward pass through CNN, save fc7 features to disk.
3. Classification. Train one binary linear SVM per class to classify region features.
4. Bounding box regression. For each class, train a linear regression model to map from cached features to offsets to gt boxes to make up for “slightly wrong” proposals.
5. NMS. Given all scored regions in an image, we apply a greedy non-maximum suppression (for each class independently) that rejects a region if it has an IoU overlap with a
higher scoring selected region larger than a learned threshold.
3 Function of Conv and FC Layers
Much of the CNN’s representational power comes from its convolutional layers, rather than from the much larger densely connected layers.
The pool5 features learned from ImageNet are general and that most of the improvement is gained from learning domain-specific fc layers on top of them.
4 Result
For VOC-07 dataset, compute mAP.
• R-CNN: 54.2%.
• R-CNN (with bounding box regression): 58.5%.
• R-CNN (use VGG-16 features): 66%.
5 References
[1]. http://techtalks.tv/talks/rich-feature-hierarchies-for-accurate-object-detection-and-semantic-segmentation/60254/.














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









