







SqlAlchemy版本:1.1.11
操作系统:Windows
Python:3.5
欢迎加入学习交流QQ群:657341423
数据持久化是常用的开发技术。具体有点请参考百度百科:请点击
Python的数据库ORM框架是数据持久层框架。这只是其中一种框架,还有其他的框架,请参考
总的来说,在实际开发中,需要不停的对数据库进行连接和操作,最基本的就是连接数据库,然后通过sql语句进行增删改,提交事务,关闭连接。这当然是最入门的做法。性能也是最差的。
这时候就引入了数据持久层的方法。
本文介绍python中最流行的SQLAlchemy框架的使用。
安装:直接用pip install SQLAlchemy即可
使用方法:
创建链接:
from sqlalchemy import create_engine
engine=create_engine('sqlite:MyDB.sqlite3',echo=True)
这里的创建是告诉SQLAlchemy你的数据库文件的路径。这里sqlite:MyDB.sqlite3,py文件和MyDB.sqlite3是同一个目录下,如果不同目录,需要写上路径。
echo=False(True),在运行py文件的时候是不显示(显示)Sql执行情况。这个可以自己试试。
这里列出一系列的数据库链接方式:
例:
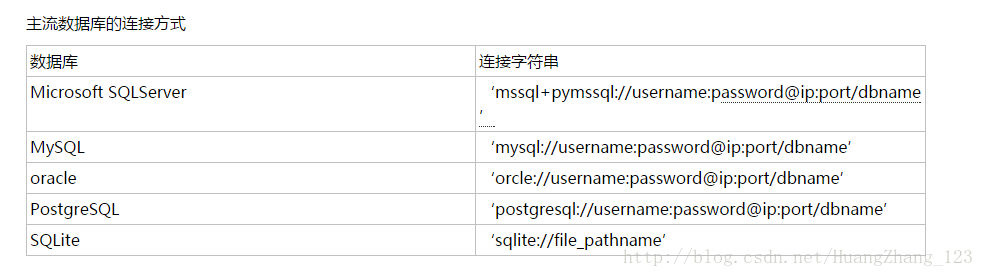
mysql://root:pass/test
root是用户名 pass密码 test数据库
明确了路径和相关的数据库名之后,就是建立会话。也可以理解为sql的游标
from sqlalchemy.orm import sessionmaker
DBSession = sessionmaker(bind=engine)
session = DBSession()
然后就是创建对象类
from sqlalchemy.ext.declarative import declarative_base
Base=declarative_base()
因为持久化都是将数据库的字段转化成代码里面类的属性来表示的。
创建表
from sqlalchemy import create_engine,Column,String,Integer
class Mybase(Base):
#表名
__tablename__ ='mycars'
#字段,属性
myid=Column(String(50), primary_key=True)
price=Column(String(50))
创建对象之后,但是在数据库里面还没生成该表。可以自定义一个方法:
def CreatDb():
#创建表
Base.metadata.create_all(engine)
def delDb():
#删除表
Base.metadata.drop_all(engine)
添加数据
dt=Mybase(myid='aaa',price="aaa")
session.add(dt)
session.commit()
修改数据
#根据新增后再修改
dt.price='aaaaa'
#提交数据库
session.commit()
#查找符合条件数据再修改,filter_by是一个list,first()表示第一个
ModifyDt=session.query(Mybase).filter_by(myid='asd').first()
#修改数据
ModifyDt.price='ccccc'
#提交数据库
session.commit()
查询数据
查询数据是用filter_by,上一代码就是查询后再修改数据。
如果多条件查询,使用多次filter_by即可
querydt=session.query(Mybase).filter(Mybase.myid == 'asd').filter(Mybase.price == 'bbbb')
for i in querydt:
print(i.myid)
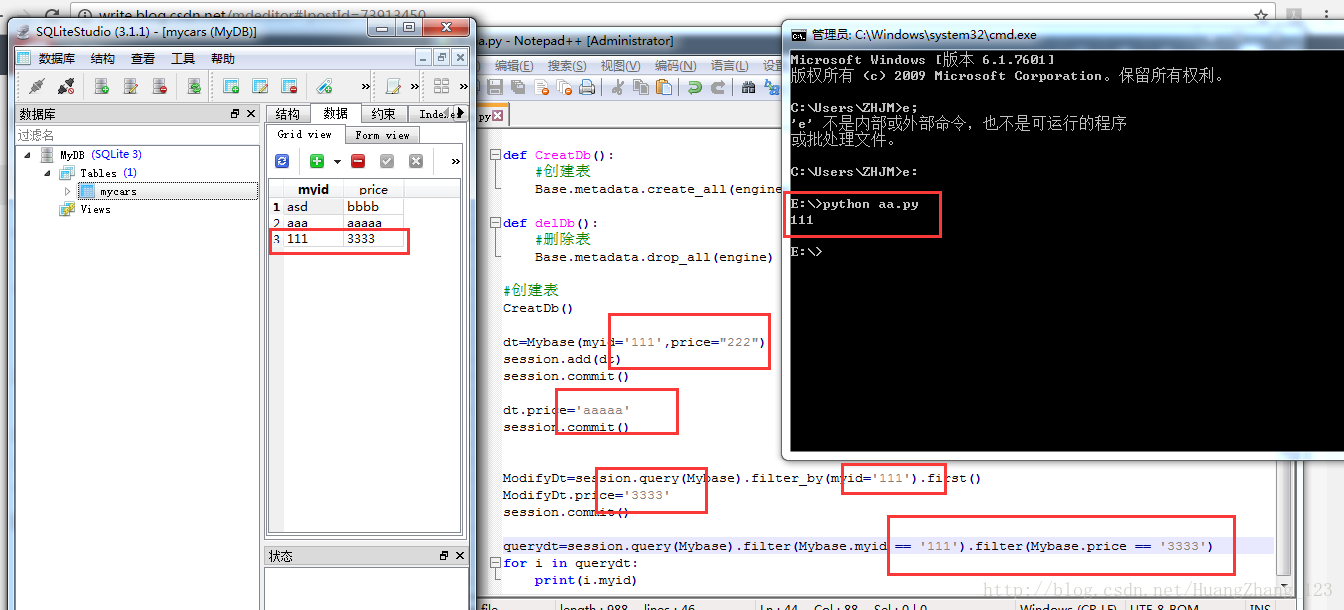
全部代码:
from sqlalchemy import create_engine,Column,String,Integer
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
#建立链接
engine=create_engine('sqlite:Mydb.sqlite3',echo=False)
#建立会话
DBSession = sessionmaker(bind=engine)
session = DBSession()
Base=declarative_base()
class Mybase(Base):
#表名
__tablename__ ='mycars'
#字段,属性
myid=Column(String(50), primary_key=True)
price=Column(String(50))
def CreatDb():
#创建表
Base.metadata.create_all(engine)
def delDb():
#删除表
Base.metadata.drop_all(engine)
#创建表
CreatDb()
#添加数据
dt=Mybase(myid='aaa',price="aaa")
session.add(dt)
session.commit()
#修改数据
dt.price='aaaaa'
session.commit()
#查询后修改
ModifyDt=session.query(Mybase).filter_by(myid='asd').first()
ModifyDt.price='bbbb'
session.commit()
#多条件查询,这里注意的是filter_by和filter的区别,filter可以多表查询。比较运算符也不一样。filter必需带表名
querydt=session.query(Mybase).filter(Mybase.myid == 'asd').filter(Mybase.price == 'bbbb')
for i in querydt:
print(i.myid)
运算结果:
此外还有很多数据库操作。这个可以参考官方文档:请点击
注意:不同SqlAlchemy版本而且版本相差较大的,在语法上会有不同的区别。















 1433
1433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











