







本文旨在在Windows上调试虚拟机的Hadoop伪分布式Map/Reduce任务。
本人是配置完之后写的总结,希望能给有需要的朋友一些帮助。
环境:
CentOS 5.5
VMWare WorkStation 9
Windows7
Hadoop 1.2.1
Eclipse-java-indigo-SR2
前提:
1、已经安装好虚拟机,并且虚拟机和宿主主机之间是可以ping通的,虚拟机的安装和配置不在本文的讨论范围。
一:搭建Hadoop环境
1、安装hadoop
以root权限解压hadoop-1.2.1.tar.gz
2、配置hadoop
①、找到hadoop目录下的config/hadoop-env.sh
配置上JAVA_HOME
②、配置core-site.xml,在<configuration>标签中添加
| <property> <name>fs.default.name</name> <value>hdfs://192.168.142.128:9000</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/temp</value> </property> |
③、配置mapred.xml,添加如下:
| <name>mapred.job.tracker</name> <value>192.168.142.128:9001</value> </property> |
3、配置ssh无密码登录
虚拟机中输入ssh,如果没有安装,可以使用命令: yum install ssh
如果ssh安装正常,使用命令: ssh-keygen -t rsa
需要确认信息的时候一直按回车就好了
然后找到目录:~/.ssh,如果没有这个目录,执行一次ssh localhost就可以了
修改.ssh目录的权限为700,将.ssh目录中的 authorized_keys的权限设置为600
将生成的公钥加入授权:cat id_rsa.pub >> authorized_keys
再次执行ssh localhost,会询问是否需要连接,输入yes即可
二:测试Hadoop环境
因为需要往hadoop_home的logs目录下写日志,所以,需要为
logs
添加写的权限
找到hadoop的bin目录,输入:hadoop namenode -format
运行start-all.sh
jps看看如下的Java进程是不是都起来了:
4309 SecondaryNameNode
4183 DataNode
4663 Jps
4525 TaskTracker
4397 JobTracker
4078 NameNode
在虚拟机的浏览器中测试这两个地址是否能正常访问:
JobTracker -
http://localhost:50030/
在物理机上访问这两个地址的时候,需要将虚拟机的fire wall关闭
service iptables stop
至此,Hadoop的环境已经搭建完毕,此处略过如下内容:
如何使用命令行往HDFS中创建文件,查看目录,上传下载文件,提交MR任务等等
三:搭建开发环境
1、打包(http://www.dataguru.cn/thread-287295-1-1.html)或者下载对应版本的hadoop plugin
在本地解压一份hadoop
2、安装好MapReduce的Eclipse插件
3、Eclipse中显示Project Explorer视图,显示Map/Reduce Location视图
4、取消hadoop的权限认证:
在Linux的hadoop中配置如下:
| <property> <name>dfs.permissions</name> <value>false</value> <description> If "true", enable permission checking in HDFS. If "false", permission checking is turned off, but all other behavior is unchanged. Switching from one parameter value to the other does not change the mode, owner or group of files or directories. </description> </property> |
5、Map/Reduce Location视图中右击新建Location
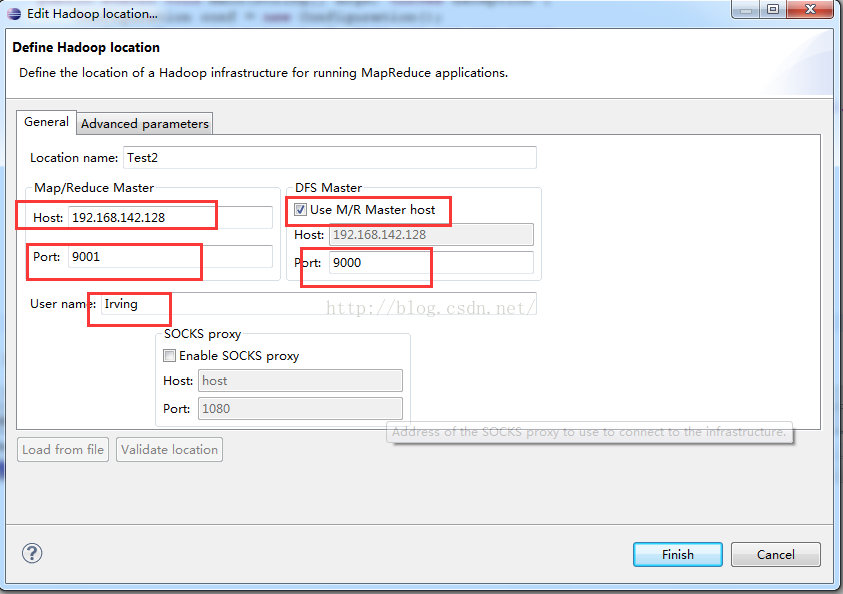
其中,User name指的是Linux用户名
接下来还需要选择Advanced parameters,将里面一些关于路径的配置改成和虚拟机上的正确路径
例如:dfs.name.dir等等
6、点击Finish之后,左侧的Project Expolorer视图的DFS Locations中将出现新的Location
如果之前在Linux中使用命令行添加过目录,这边就会有user目录,如果没有,执行一下添加目录的命令就可以了
类似如下的结构
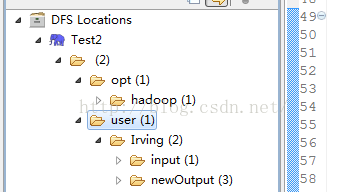
7、 新建项目,将WordCount.java放入其中,其中jar包支持来自于解压在本地的hadoop目录下的lib
8、main方法添加如下的修改:
|
conf.set(
"mapred.job.tracker"
,
"192.168.142.128:9001"
);
job.setJarByClass(Count.
class
);
args=
new
String[]{
"hdfs://192.168.142.128:9000/user/Irving/input"
,
"hdfs://192.168.142.128:9000/user/Irving/newOutput"
};
|
注意:假设读者已经在命令行执行过map reduce任务,所以此处略过了WordCount项目的编写,以及input和out文件目录的新建和管理部分。
9、点击运行Run on Hadoop,选择刚刚新建的location
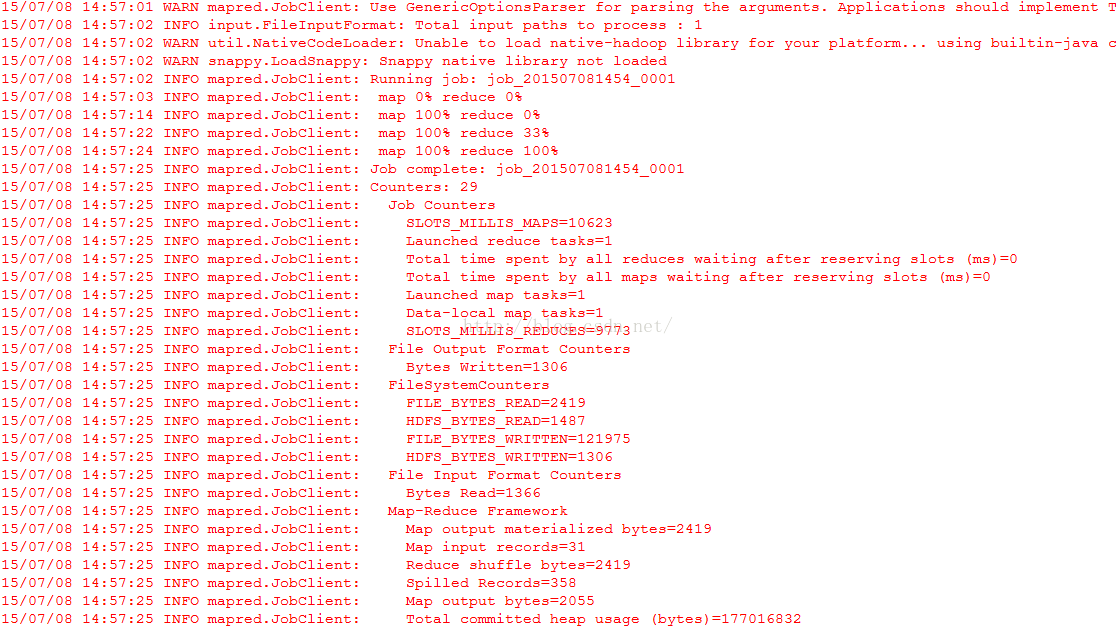
至此,已经能在eclipse中提交任务到远程的Hadoop上执行,并且返回结果了。
10、如何debug?
此处只讨论如何调试Map Reduce任务
①、修改mapred-site.xml文件,添加远程调试的监听端口:
|
<
property
>
<
name
>
mapred.child.java.opts
</
name
>
<
value
>
-agentlib:jdwp=transport=dt_socket,address=8883,server=y,suspend=y
</
value
>
</
property
>
<
property
>
<
name
>
mapred.tasktracker.map.tasks.maximum
</
name
>
<
value
>
1
</
value
>
</
property
>
<
property
>
<
name
>
mapred.tasktracker.reduce.tasks.maximum
</
name
>
<
value
>
1
</
value
>
</
property
>
<
property
>
<
name
>
mapred.job.reuse.jvm.num.tasks
</
name
>
<
value
>
-1
</
value
>
</
property
>
|
重启Hadoop服务
②、将该文件复制到项目的src目录下。
③、在Map任务中添加断点,在Eclipse中按照9中所描述的,运行word count程序,会发现程序在执行map任务的时候就暂停了:

此时,新建一个Debug - > remote Java appliction,
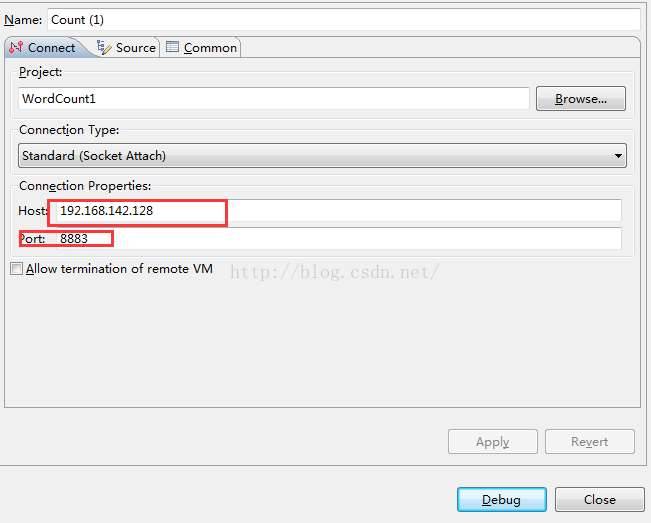
运行,将会进入debug模式:
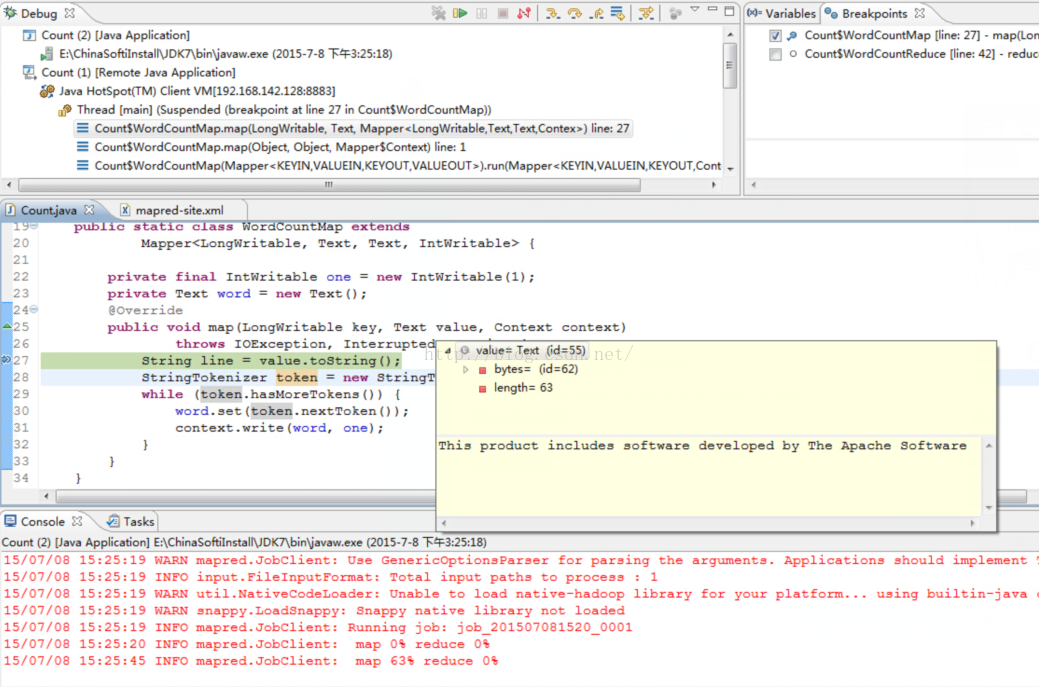
Map任务完成之后,程序将停在Reduce任务为0%的时候,

此时,再运行一次刚刚的remote Java appliction,将进入reduce任务的断点。
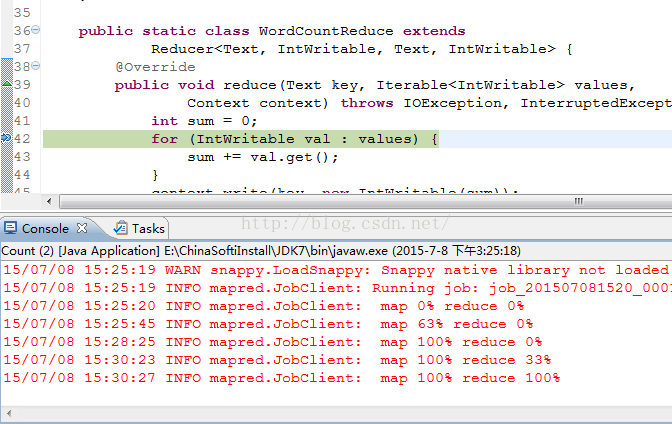
完毕。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









