










在上一篇End to end memory network中提到,在问答系统中加入KB(knowledge bases)能提高训练的效果。但是一些KB,如FreebaseKB有内在的局限性,即1、不完整;2、有固定的模式不能支持所有类型的答案。因此即使KB方式能够满足特定领域的问题,但是不能扩大规模,在任何所有领域都行得通。因此,本文Key-Value Memory Networks for Directly Reading Documents从阅读文档开始直接回答问题。
直接从文本中获取答案比从KB获得答案要困难得多,因为文本中信息的没有结构化,是一种间接含糊地表达,而且通常分散在多个文档中。这就解释了为什么使用一个好的KB(通常只在特定领域中可用)比原始文本更受欢迎。本文的亮点在于提出了一种基于Key-Value Memory Network的结构框架将阅读的信息编码记录下来,类似RNN的作用。这种框架可以通过以Key-Value 的形式提取文档中的信息作为KB,基于MemNNs model(《End-To-End Memory Networks》)的方式,训练出Key-Value 向量,去做Questions Answering任务。本文不仅在 WIKIQA 的数据集上做了实验,还构建了 WIKIMOVES 数据集。
本文主要参考neural_kbqa和key-value-memory-networks两篇代码,neural_kbqa使用了WIKIMOVES的数据,key-value-memory-networks使用了qa中常用的babi数据集,两段代码都写的很完善,因此不再自己实现,着重讲一下neural_kbqa的实现方式。分为数据处理,模型构建、模型训练等三个方面。
数据处理
首先看一下WIKIMOVES的数据集长什么样:
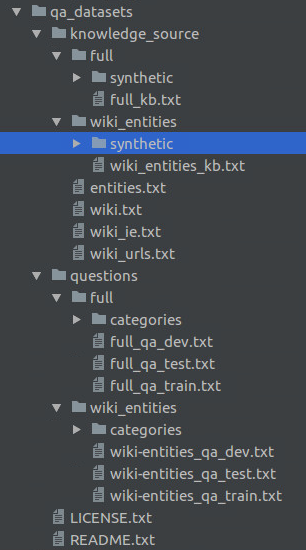
这是为key-value memory network构造的数据集,分为knowledge_source和question两个部分。每个部分下面都有full和wiki两个子文件夹,full代表的是完整的数据集,wiki代表的是一段数据集中的所有实体都在wiki中有提到,所以是full的一个子集。
代码中主要用的是wiki的部分,所以再来看一下wiki_entities_kb.txt和wiki-entities_qa_train.txt长什么样:
wiki_entities_kb.txt:
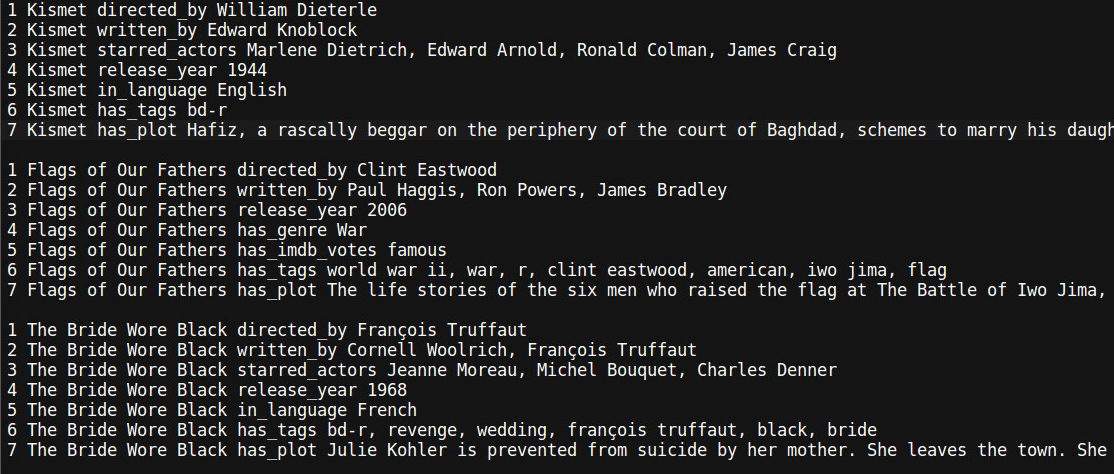
kv部分就是一个陈述句,包含source,relation和target三个部分,比如第一段第一句话
source为“Kismet”
ralation为“directed_by”
target为“William Dieterie”
通过一些简单的分割,就能构造出kv对,在key-value-memory-networks中,使用source和realtion作为key,使用target作为value,以此实现对文章的提取。
wiki-entities_qa_train.txt:
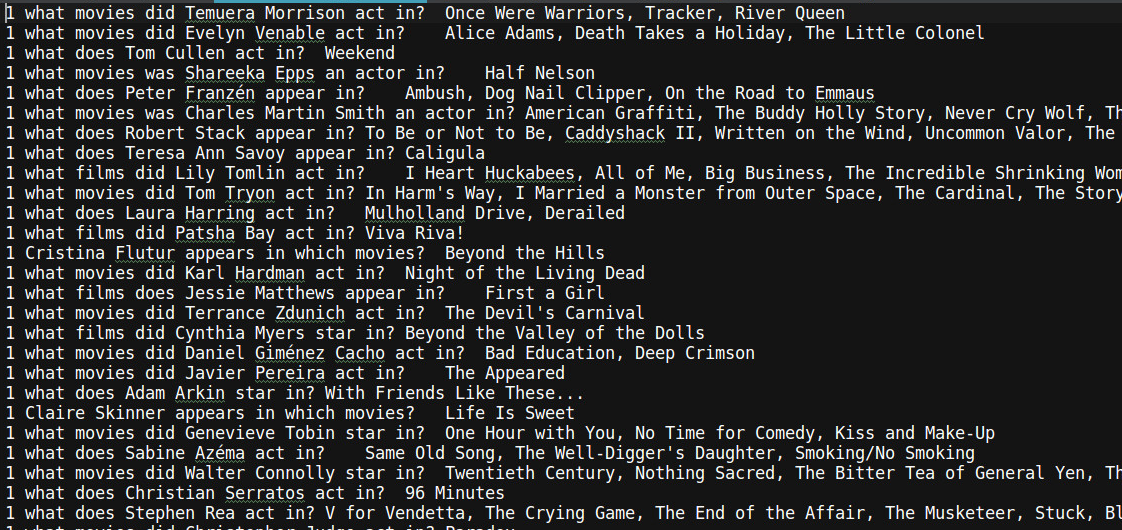
上图是训练集,给出问题,给出答案,测试集和验证集的格式相同。那么有kv对,有了训练集,需要构造什么样的训练样本呢?构建结果如下图所示:
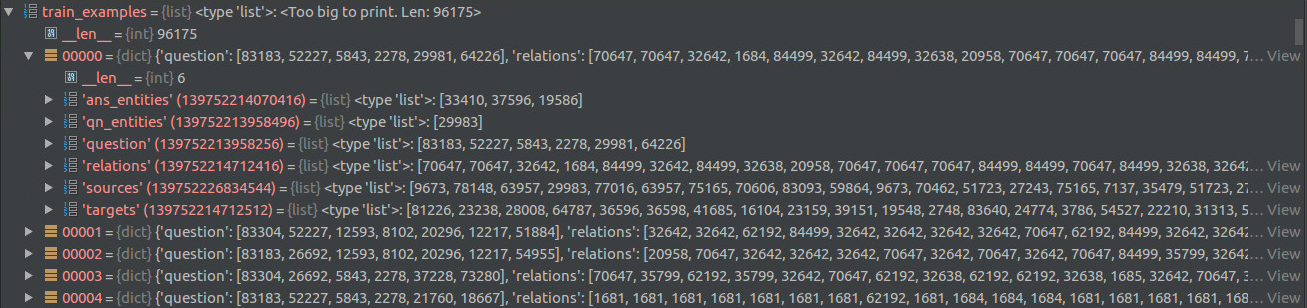
共有96175个训练样本,每一个样本都是一个字典,包含以下几个key ([]内为key对应的value的最大长度):
question [21]
qn_entities [1]
ans_entities [94]
sources [2048]
relations [2048]
targets [2048]
那么从原始的wiki-entities_qa_train.txt和wiki_entities_kb.txt如何构造出上图的结果呢?我总结出几个关键的步骤:
1、clean_entity.py:针对knowledge_source中的entities.txt文件
- 移除实体中标点符号
- 移除重复实体
- 全部转为小写
- 将实体按照字典顺序排列(使用sortedcontainers库)
2、clean_kb.py:针对wiki_entities_kb.txt文件
- 对wiki_entities_kb.txt中的字符串进行解析,即:
kismet directed_by william dieterle ->
kismet|directed_by|william dieterle
3、clean_qa.py:针对wiki-entities_qa_train.txt文件
- 对wiki-entities_qa_train.txt中的字符串进行解析,即:
what movies are about ginger rogers? top hat, kitty foyle, the barklays of broadway -> what movies are about ginger rogers top hat|kitty foyle|the barklays of broadway
4、gen_dictionary.py & gen_stopwords.py
- 生成停用词和字典。在处理数据集过程中共用到
word_id[50141个]
entity_id[40134个]
relation_id[20个]
将这三个idx合并到一个idx:
all_id[85524个],即代码中的idx。
5、gen_kv_data.py:
- 将训练集用图来表示,source和target为两个端点,relation为边,共有40134个。
- 筛选key-value slot,最大的slot个数为64,因此要在数万个kv对中寻找64个最相关的kv对,paper中使用倒排索引来筛选(代码中使用whoose和networkx实现)
具体的过程较为复杂,如果不想自己手动处理可以使用neural_kbqa代码中的处理好的数据。本文只大致介绍一下文本处理流程,具体代码还需要自行跑代码。
模型构建
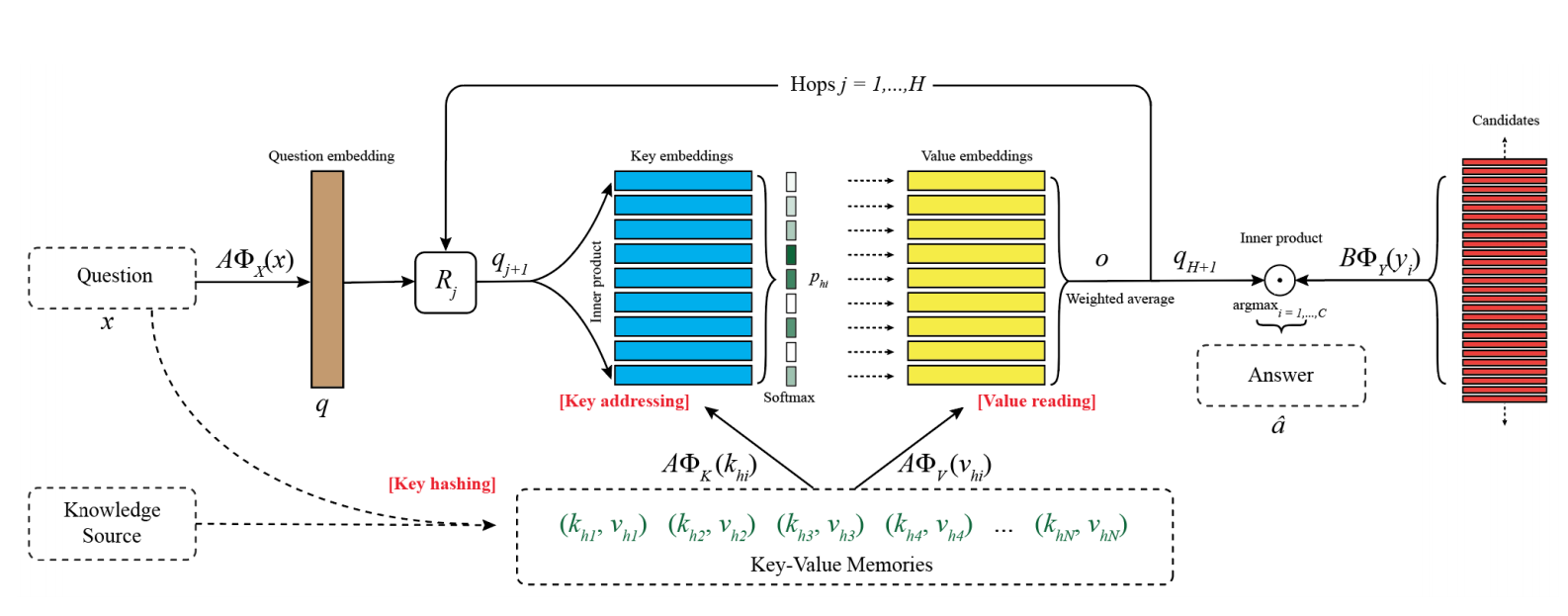
key-value的寻址和读取记忆的过程主要包含三步:
1、key-hashing:question用来从非常大的kv对中预筛选一个子集(memory slots),paper中使用倒排索引。多于memory slots size的kv对可以随机删除到memory slots size个,少于memory slots size的kv对将会被填充。
2、key-addressing:每一个候选记忆都被计算出一个概率:
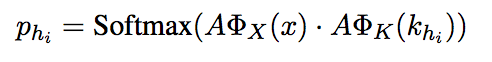
AϕX(x) A ϕ X ( x ) 代表问题的表示, AϕK(khi) A ϕ K ( k h i ) 代表每一个memory slot的表示,两者点乘然后softmax得到每个memory slot的概率。
3、value reading:最后将value与他们的概率相乘,得到输出:
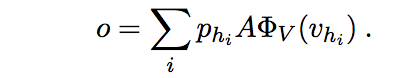
对于多层的key-value memory network,得到输出的O以后,将循环:

根据o更新q2, 通过迭代Key Addressing与Value Reading过程实现memory access process,最后第 H hop后得到qH+1, 计算所有可能答案的分数(这里的答案和key候选向量不是同一个映射):
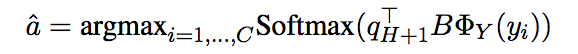
paper中提到,key-value-memory-networks是在end to end memory network的基础上进行的改造,目的是1、KB结构僵硬,如何构造一个直接读取文本的memory network。2、解决end to end memory network无法添加大规模先验知识的问题。所以模型构造和end to end memory network相似,这里不再赘述。
模型训练
模型训练是很重要的一部分,我们先看一下现在的训练样本的shape:
再来看一下key-value-memory-networks的placeholder的shape:
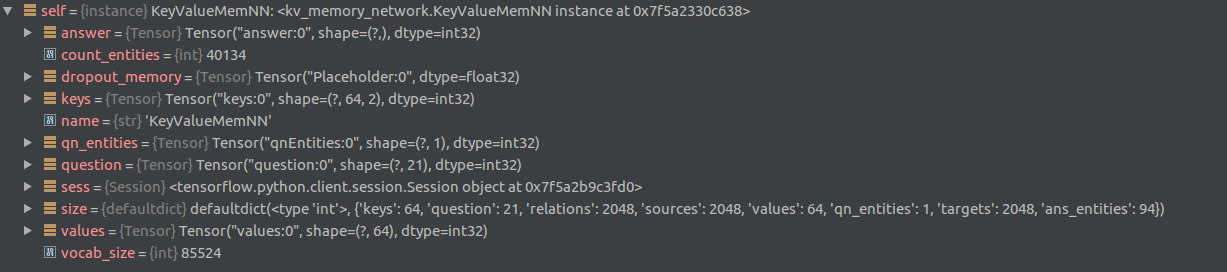
即,我们训练后的shape为:
question [21]
qn_entities [1]
ans_entities [94]
sources [2048]
relations [2048]
targets [2048]
而placeholder的shape为:
question [None, 21]
qn_entites [None, 1]
answer [None, ]
keys [None, 64, 2]
values [None, 64]
那么这是怎么feed dict呢?
按照data -> placeholder
question -> question
qn_entities -> qn_entities
ans_entities -> 不填充到[None, 94],而是有几个ans_entities就构建几个样本,比如question=a,ans_entities=b,c那么样本就变为两个[a,b]和[a,c]
keys -> 将sources和realtions合在一起作为keys
values -> 将targets作为values
本文通过直接阅读文档来回答问题,在直接阅读文档和使用人工设计的KB体系中间找到一个trade-off,使用key-value memory network来填补这个gap。在wikimovies和wikiqa两个数据集上超越了其他几种方法,包括:
- Question answering with subgraph embeddings.
- Evaluating prerequisite qualities for learning endto-end dialog systems.
- Memory Network
其他
本文还提出了多种可能key-value memories的形式:
- KB Triple
“subject relation object”
key考虑为subject+relation,value为object,逆关系也考虑进去:
“Blade Runner directed_by Ridley Scott” v.s. “Ridley Scott !directed_by Blade Runner”
- Sentence Level
将文档按句子分割,每句话以bag-of-words编码作为key-value pair, 而且同一key-value pair的key和value是完全相同的。
- Window Level
将实体词作为中心词,视为value,以该词为中心取固定的窗口中的词作为key.
Window + Center Encoding
Window + Title














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









