






1 引言
1.1 编写目的
基于jtag的ecos多任务调试设计,希望借鉴gdb现已有的对Linux多线程调试的考察,预期从设计实现、软件层次设计等方面借鉴。
本文首先对linux多线程调试设计框架进行分析;然后,具体分析linux多线程调试的实现机制;最后,从实现原理与整体设计框架上进行总结,得出CSKY的多任务调试的总体设计方案。
1.2 概述
Gdb提供了一组多线程调试命令,如表1-1所示。
表格1‑1 gdb多线程命令列表
| 命令 | 说明 |
| Info threads | 显示当前可调式的所有线程(处于stop状态) |
| Thread ID | 切换当前线程为指定ID的线程 |
| Thread apply ID1 ID2 command | 让一个或者多个线程执行command命令 |
| Thread apply all command | 让所有线程执行command命令 |
| Set scheduler-locking off|on|step | 设置locking schedule的模式: On——只有当前线程会运行; Off——所有线程都会运行; Step——当执行step操作的时候只有当前线程会运行,执行continue操作的时候所有线程都会运行。 |
多线程调试的主要任务是准确及时地捕捉引起被调试程序线程状态的变化的事件,并且GDB针对根据捕捉到的事件做出相应的操作。最终的结果就是维护一个正确的thread list。表1-1中的调试命令都是基于thread list实现的。
2 代码框架分析
2.1 总体分析
Gdb的linux多线程调试的实现主要依赖下面三个文件,如表2-1所示。
| 文件名 | 说明 |
| Thread.c | 多线程调试命令子集的实现 |
| Linux-nat.c | Linux应用程序调试的实现 |
| Linux-thread-db.c | 基于pthread库的多线程部分的实现 |
Libpthread库用来管理用户态线程的,用户线程的创建和消除都需要libpthread库的支持,gdb基于此维护好用户线程的thread_list。Gdb的多线程调试命令基于thread_list实现对用户态进程的操作。而不同的系统对于用户线程的实现方式不一样,有些系统用户态线程完全是线程库实现,在内核看来只有一个调度单元,这种可以看做是用户线程与内核线程多对一;而linux内核中,采用的是内核线程与用户线程一对一的方式,一个用户线程对内核来说是一个单独的调度单元。
用户态线程的信息光光靠libpthread库中的一些信息是不够的,对于内核相关的一些信息,比如线程状态、线程的信号等。必须找到用户态线程对应的内核线程,从中获取这些信息。
Gdb中使用structptid{pid,lwp,tid}来描述一个线程,这三个域分别表示:进程id、内核线程id、用户线程id。对于linux,内核线程和用户态线程是一对一的关系,所以lwp和tid是一样的。
下面简单介绍一下gdb中linux多线程应用程序本地调试主要的三个文件:
thread.c函数非常简单,它的任务非常简单,就是多线程调试命令子集的实现,比如info threads。当用户在gdb命令行敲入多线程调试命令子集中的命令时,就会调用thread.c中对应的函数。Thread.c中的实现都是基于thread list的。而gdb对于thread list的维护工作主要在另外两个文件中实现。
Linux-nat.c可以类比于CSKYjtag调试方式下的remote-csky.c文件。它实现了通常的调试功能,比如读写寄存器、读写内存、resume程序、wait程序、attach、detach等功能。更重要的是,在linux-nat.c中会维护一个lwp_list链表,表示当前进程所有的内核线程。
而linux-thread-db.c则是基于thread_db库(libpthread是linux的多线程库,而libthread_db是和libpthread一起提供的,二者必须配套使用。Libthread_db将thread library的internals暴露给gdb)的一组功能函数。这么一组函数数量不多,可以分为两类:一类是对linux-nat.c已经实现的函数基础上套了一层,在原先的基础上增加一些libthread_db相关的操作,比如resume、wait等函数;另外一类是基于libthread_db库,增加linux-nat.c中没有实现的,仅仅用在多线程调试环境下的函数,比如to_get_thread_local_address。这些函数的任务就是获取用户态线程的产生、消亡事件,已经获取用户态线程相关的数据。Linux-thread-db.c获取用户线程的发生的事件和获取的信息、结合linux-nat.c中维护的lwp_list内核线程链表中提供的信息,以此维护一个完整的thread_list。里面包含gdb感兴趣的,关于线程所有的信息。
对于软件的结构,通常逻辑上都不直接以文件为单位进行分析,gdb中也一样。Gdb中对后端函数使用struct target_ops数据结构来组织。不同功能的函数集抽象成不同的target_ops。比如专门用于操作可执行文件的”exec”target_ops,用于处理coredump文件的”core” target_ops,以及我们熟悉的jtag调试方式的”csky”target_ops(一下称为linux_ops)。而linux-nat.c中实现的linux应用程序本地调试功能也抽象成一个ops”child” target_ops,linux-thread-db.c中实现的基于libpthread库的调试功能抽象成”multi-thread”target_ops。
整个linux多线程应用程序本地调试的结构框架如图2-1所示。
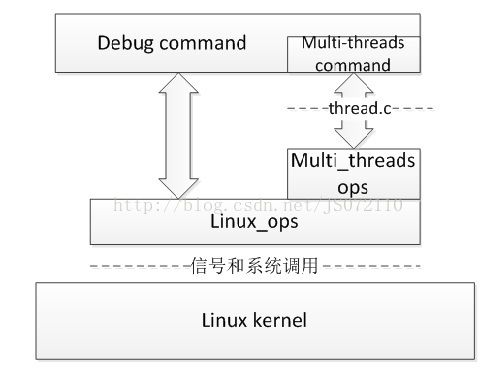
2.2 模块分析
Thread.c中的调试命令的实现,在此不作赘述。linux-nat.c中实现的linux_ops实现的是基本的linux应用程序本地调试的功能函数,本文着重分析多线程,故在本节模块分析中只分析linux-thread-db.c中实现的thread_db_ops。
Multi-threads ops中的函数和数据分析如表2-2所示。
| 成员名 | 说明 | 值 | 是否在linux_ops中有实现 |
| To_shortname | 名称 | Multi-thread | \ |
| To_stratum | 该ops所属的层次 | Thread_stratum | \ |
| To_detach | Detach一个进程 | Thread_db_detach | Y |
| To_wait | 等待进程 | Thread_db_wait | Y |
| To_resume | Resume进程 | Thread_db_resume | Y |
| To_mourn_inferior |
| Thread_db_mourn_inferior | Y |
| To_pid_to_str | 将pid转换成字符串 | Thread_db_pid_to_str | Y |
| To_has_thread_control |
| Tc_shecdlock | Y |
| To_get_thread_local_address | 找到该线程的tls的地址 | Thread_db_get_thread_local_address | N |
| To_extra_thread_info |
| Thread_db_extra_thread_info | N |
| To_get_ada_task_ptid |
| Thread_db_get_ada_task_ptid | N |
| To_find_new_thread | 通过pthread库,查找新的用户空间线程 | Thread_db_find_new_thread | N |
当被调试程序是linux多线程程序时,就会使用thread_db_ops中的相应的函数。那么问题来了,对于resume和wait这些Linux_ops中也实现的函数,会调用哪个呢?为什么呢?Gdb中实现了很多的target_ops,有功能相近的比如linux_ops和csky_ops,也有完全不同功能的,比如linux_ops和file_ops。那么对于功能相近的target_ops怎样使用呢?功能不同的target_ops之间又有怎样的关系呢?这些问题gdb的target_ops的stratum分层机制能解释这些问题。
Gdb中把target_ops分为了7层,每一层负责不同的功能。如图所示。

Gdb中有一个structtarget_ops类型的全局数组target_stack[],该数组的大小是7,对应7个stratum的target_ops。Arch_stratum在最顶端,dummy_stratum在最底端通过push_target()函数将target_ops添加到该数组中。一个stratum的target_ops只能有1个。如果push_target()调用时发现该stratum的target_ops已存在,那么就覆盖它。
当gdb中要调用target_ops中的某个功能函数时,会从target_stack的最顶端开始查询,如果该stratum的target_ops中实现了该函数的话,那么调用它,否则查询下一个stratum。由此可见,如果同一个函数在较顶层和较底层的target_ops中都实现的话,那么会调用较顶层的函数。那么,现在回到linux_ops和thread_db_ops的问题,linux_ops是process_stratum,而thread_db_ops是thread_stratum,所以对于二者中都实现的函数,会调用thread_db_ops中的函数。
需要注意的是gdb一开始并不会将所有的stratum的target_ops都push到target_stack中。因为一开始并不能确定某层次的stratum应该使用哪个target_ops,要根据具体使用到的时候才能确定。比如,当gdb通过file命令添加elf文件时,那么这时候需要一个处理elf文件格式的file_stratum,这时候就把”exec”target_ops通过push_target()函数push到target_stack中。那么”multi-thread” target_ops是什么时候push进来的呢?
要push”multi-thread”target_ops,那么我们就必须确定我们调试的是多线程程序。那么怎样才能确定这件事情呢?gdb是通过被调试程序是否状态libpthread库来判断的。也就是一旦被调试程序装在libpthread库,我们就应该将”multi-thread” target_ops push进来。Gdb需要一定的机制来捕捉装载libpthread库这个事件,这个机制叫做observer-notify机制:gdb采用一种事件的observer机制,在gdb中对不同的事件都有相应care的observer_list,在observer_list中各个observer注册了对改事件的处理函数notify(),当该事件发生时,就会遍历这个observer_list,依次调用各个observer的notify()处理函数。Gdb内部的事件由很多种,包括:线程的创建、objfile的添加。而这里我们multi-thread ops的添加利用的就是,Objfile(包括main file和so file)添加事件。这里添加new objfile事件在gdb中有一个对应的observer_list叫new_objfile_subject。在observer_notify_new_objfile(objfile)函数相当于这么一个new objfile的入口函数,在该函数中遍历new_objfile_subject依次执行各个notify()处理函数,其中有个notify()函数便是thread_db_new_file(objfile)。而thread_db_new_file(objfile)就会将”multi-thread”target_ops push到target_stack中。
3 Linux多线程调试机制分析
本节主要分析linux多线程程序本地调试实现的机制。包括:如何建立被调试进程并且使其进入调试模式、如何维护内核线程列表lwp_list、如何维护用户线程列表thread_list。
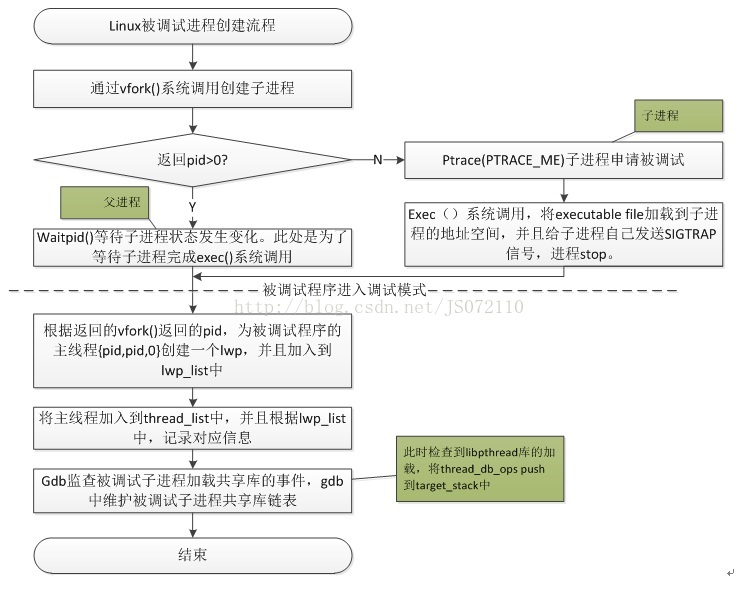
3.1 调试进程建立
Gdb在调试linux应用程序时,必须以run命令开始,因为gdb为被调试程序创建进程的过程就在run命令中完成。具体的流程如图3-1所示。
3.2 Lwp_list的维护
被调试进程创建线程最终是通过clone()系统调用实现的。要维护内核线程就是要捕捉子线程的创建和死亡事件,以此来维护被调试进程的内核线程。这个捕捉事件由ptrace提供的机制实现。具体机制如图3-2所示。
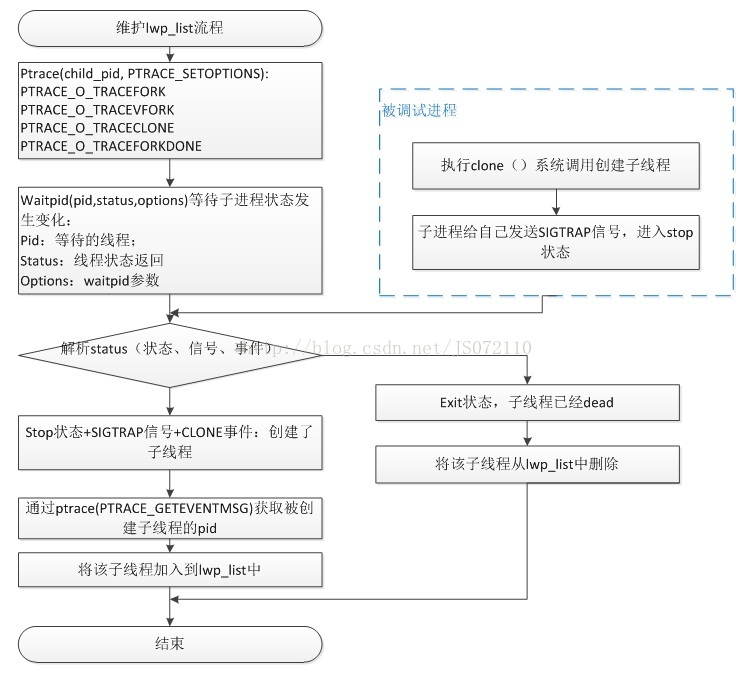
在3.1节中创建好被调试进程之后,gdb通过ptrace(PTRACE_SETOPTIONS)设置gdb会对被调试进程的哪些事情感兴趣。这里设置PTRACE_O_TRACEFORK、
PTRACE_O_TRACEVFORK、PTRACE_O_TRACECLONE、PTRACE_O_TRACEFORKDONE。设置过后,当被调试进程创建线程的时候,就会给自己发送一个SIGTRAP信号,让被调试进程进入stop状态,使得gdb能够捕捉到这些事件。
用户可能会疑问,从来没有见过gdb捕捉子线程创建事件,维护lwp_list过程。这是因为,Gdb对于这些事件的处理用户是不可见的,相当于是后台进行的。当完成lwp_list添加后,gdb会让程序继续运行,直到被调试程序发生一些需要通知gdb用户的事件,比如触发了用户设置的断点。
3.3 Thread_list维护
Thread_list是structthread_info类型的一个链表,记录的是被调试进程的所有线程的信息。是最终呈现给用户的信息,里面包含线程用户态和内核态的一些信息。线程用户态信息的捕获基于libpthread库实现。但是libpthread库并没有提供调试接口。对应的有一个libthread_db库,该库和libpthread一样,只不过提供了一组调试接口。这么一组libpthread_db调试接口在gdb中使用struct thread_db_info进行管理。
该数据结构的具体信息如下表3-2所示。
| 数据项 | 说明 |
| Int pid | 该数据结构描述的process id |
| Void *handle | Libpthread.so的dlopen的handle |
| Struct ps_prochandle proc_handle | 该数据结构用来identify用来的<proc_service.h> interface的child process |
| Td_thragent_t *thread_agent | Connection to the libthread_db library |
| Int need_stale_parent_threads_check |
|
| CORE_ADDR td_create_bp_addr | Thread creation event breakpoint的位置,该地址处的代码在thread被创建时,一定会被pthread库函数调用。Gdb通过在这个地方设置断点,这样gdb就能捕获thread的创建。 |
| CORE_ADDR td_death_bp_addr | Thread death event breakpoint的地址,同上。 |
| 一组指向libthread_db 函数的函数指针 | |
| Td_err_e(*td_init_p) | 初始化函数 |
| Td_err_e(*td_ta_new_p) |
|
| Td_err_e(*td_ta_map_id2thr_p) | 根据pid找到对应用户态线程 |
| Td_err_e(*td_ta_map_lwp2thr_p) | 根据lwp找到对应用户态线程 |
| Td_err_e(*td_ta_thr_iter_p) | 枚举所有的用户态线程 |
| Td_err_e(*td_ta_event_addr_p) | 获取线程发生event的地址 |
| Td_err_e(*td_ta_set_event_p) | 设置care的线程事件 |
| Td_err_e(*td_ta_event_getmsg_p) | 获取发生上一个event的用户态线程id |
| Td_err_e(*td_thr_validate_p) | 判断某用户态线程是否alive |
| Td_err_e(*td_thr_get_info_p) | 获取用户态线程的信息 |
| Td_err_e(*td_thr_event_enable_p) | 使能用户态线程的事件监测 |
| Td_err_e(*td_thr_tls_get_addr_p) | 获取线程的tls的地址 |
在被调试进程加载libpthread库时,会为该进程创建这么一个struct thread_db_info记录该进程要使用到的libthread_db提供的调试接口。其中比较重要的是:
(1) CORE_ADDR td_create_bp_addr和CORE_ADDRtd_death_bp_addr。这两个地址是对应libpthread库中的某个位置。当调用libpthread库创建线程或者线程死亡时,一定会分别调用这么两个addr处的代码。Gdb通过在这两个位置设置断点来捕获libpthread库的线程创建和死亡事件。
(2) 一组函数指针。这么一组函数指针对应libpthread库中的相关函数。Gdb使用dlopen()打开libthread_db库以后,以此通过dlsym()方式找到对应函数符号在libthread_db中的位置(也就是在libpthread库中的位置),然后赋值给struct thread_db_info中相应的指针。这样gdb在要调用libpthread库中的函数来获取用户态的线程信息的时候直接调用struct thread_db_info中的函数指针即可。
对于用户线程create和death事件的捕获非常简单:
I. gdb在CORE_ADDRtd_create_bp_addr和CORE_ADDR td_death_bp_addr设置断点。断点的类型为特殊类型bp_thread_event.
II. 被调试程序创建子进程或者子进程死亡,会执行到libpthread库的CORE_ADDR td_create_bp_addr或CORE_ADDRtd_death_bp_addr地址处,触发断点。线程进入stop状态
III. gdb 通过waitpid()监测到被调试进程的状态改变,分析子进程发生的事件,判断为bp_thread_event的断点触发。如果是create,获取新创建线程struct thread_info的相关的信息,并且加入到thread_list中;如果是death,从thread_list中删除该线程。
4 Ecos多任务调试机制分析
eCos(EmbeddedConfigurable Operation System)是一款开源的实时操作系统。相对linux系统,ecos更精简,可配置。Ecos像linux一样支持多任务,具有任务调度的功能,但是ecos和linux的区别在于ecos系统的多任务并不支持独立的进程空间,也没有内核态和用户态的概念。Ecos内核和多任务代码编译在一起,共享内存空间,合起来组成一个程序。
Ecos多任务调试即基于任务调度功能,获取任务(以下称为线程)的状态。Ecos中使用Cyg_Thread来描述一个线程。里面包含的信息有:
| 数据域 | 说明 |
| State | 线程状态 |
| Suspend_count | 挂起次数 |
| Wakeup_count | 唤醒次数 |
| Wait_info | 等待的原因 |
| Unique_id | 线程的id |
| Stack_base | 栈的基址 |
| Stack_size | 栈的大小 |
| Stack_ptr | 当前栈针 |
| Entry_point | 线程入口地址 |
| Entry_argument | 线程参数 |
| Name | 线程的名称 |
| HAL_SavedRegisters*saved_context | 寄存器(包括pc) |
| List_next | 下一个线程 |
该类还有一个重要的静态成员staticCyg_Thread *thread_list。该指针指向ecos的线程链表。所以我们主要获取该thread_list指针,就能找到线程链表,再通过读内存的方式,以此获取每个线程的线程信息。
现在关键是要找到staticCyg_Thread *thread_list这个指针。这就要借助最终编译出来的elf文件的符号信息,通过查找符号表中Cyg_Thread ::thread_list符号的地址,就ok了。
有时候不仅要知道整个线程链表,要明确current_thread也很重要。Ecos中有个类class Cyg_Scheduler_Base,它提供了一个static方法current_thread()返回当前线程,那么同样通过elf文件的符号表找到符号Cyg_Scheduler_Base::current_thread所在的地址,即可获得当前线程的class Cyg_Thread的对象。
在jtag调试方式下,当触发断点后,cpu进入调试模式,gdb此时通过读内存的方式能够获取当前线程、线程列表。然后执行多线程命令。
5 Ecos多线程调试设计
5.1 框架设计
本设计基于jtag调试方式,gdb通过在线仿真器和cpu的had调试模块,实现调试功能。参照linux多线程调试实现。
(1) Thread.c文件仍然作为多线程调试的命令的实现文件;
(2) 相对linux-nat.c,我们基于现有的jtag调试方式的实现xxx-remote.c文件,里面实现一个process_stratum的target_ops;
(3) 相对linux-thread-db.c,我们设计一个ecos-thread-db.c,实现一个ecos_thread_db ops。
这样的框架设计的好处在于,ecos_thread_dbops和process_stratum target_ops分开,这样要实现其它实时系统比如ucos的多线程调试的时候只需要增加一个ucos-thread-db.c即可。
5.2 线程列表维护
对于线程列表的维护,现在有两个方案:
(1) 程序每次进入调试模式时,都扫描一遍ecos的thread_list,使得gdb中的thread_list和它同步。
(2) 能够像linux多线程事件捕捉一样,能不能通过信号或者断点的方式,gdb后台捕捉ecos的线程创建和线程死亡事件,以此维护thread_list(有待对ecos系统进行进一步考察)。














 774
774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









