







SONG FROM PI: A MUSICALLY PLAUSIBLE NETWORK
FOR POP MUSIC GENERATION
论文原文:Song from pi
生成的音乐:www.cs.toronto.edu/songfrompi
摘要
我们使用深度网络结合音乐的知识来生成音乐,具体来说,网络下面的层用来生成Melody(歌曲的旋律),上面的层用来生成Drums(节拍)与Chords(和弦)。我们将此方法和Google的方法进行了对比,此外还设计了两个新奇的应用。
绪论
(首先从宏观来说——深度学习在艺术上的成就)
不仅是在图像和音频领域,深度学习在艺术领域也有所建树。例如:梵高的画、通过图像生成故事、学习莎士比亚的写作风格、给出对于时尚的建议等。
(然后具体到本论文的主题——音乐生成)
按时间顺序对这个领域的论文进行了一个综
……
(之后说我们灵感的来源、我们的动机)
我们的动机来源于Song From PI,它给我们的启示是:任意一段随机的数字都可能是Pi的一部分,也就是说,其实杂乱无章的数字也可以生成很优美的音乐。受到这个的启发,我们决定尝试使用深度网络去生成音乐。
(介绍方法)
我们使用RNN去生成音乐,使用网络下面的层生成Melody,同时使用上面的层生成Chords和Drums,为的是让Drums和Chords能够和Melody配合(因为上面的层使用了下面层的输出,也就是Chords和Drums获得了Melody的信息,因此可以配合)。
(实验)
我们在100小时的midi音乐上(包括流行音乐和游戏音乐)训练了我们的模型,我们将Google的方法作为BaseLine,和其对比也证实了我们的方法比Google 的要好。同时我们也展示了两个应用——neural dancing & karaoke和 neural story singing。在第一个应用中,实验里的小人可以随着音乐起舞并唱卡拉OK,第二应用里面我们做了和Kiros一样的工作,使用一张图片生成一个故事,但不同的是,我们实验可以将这个故事唱出来。
相关研究
关于音乐生成的应用有很多,先综了一些
……
然后开始述:
以前的方法常常是将音符的结合方式嵌入到生成系统中去生成音乐,例如……,另一方面,神经网络在八十年代就被用于生成音乐,列举了从89年到96年再到01、02年的一些文章。并且在1996年就有人用循环神经网络去做音乐生成。LSTM也在2002年被使用到这个问题中,并且和RNN相比,LSTM更好的学习到了音乐的整体结构。
和我们方法的很像,Kang在2012年尝试将Melody和Drums结合去生成音乐,然而,在他们的工作中,音阶类型被强化了,而且也没有模型的详细信息,因此无法比较。Boulanger-lewandowski在2012年尝试学习复杂的多韵律变换的音乐结构,其中有很多的音符,并行演奏,但这个模型是单轨(single track)的,只生成了Melody,而我们的工作是多轨(multi track)的,同时生成Melody和Chords、Drums。最近,huang在2016年提出了一种两层的LSTM,就像Boulanger-lewandowski一样,生成了更加复杂的单轨音乐,同时也使用了Chords。
我们的主要创新在于:我们使用了一个分层的模型,并将音乐理论的知识结合到这个模型中,并生成了多轨(Melody、Chords、Drums)的流行音乐,同时我们还有两个非常Novel的应用。
音乐理论
从最简单的音乐记号和定义开始:
Note音符:
音符定义了一个基本的用于组成音乐的单元,西方音乐采用的是十二音阶。(十二音技法音乐是现代西方作曲技巧之一,亦称十二音体系,CDEFGAB就是音阶)12就是循环周期。这12个音就是:
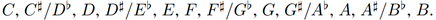
其中一个bar,就是一个小的时间片段,这个时间片段里面有一个固定数目的音符,(图1-1中竖线中的那一段,每一个bar里有8个音符)不同的bar用一个竖线隔开。

图 11 寂静之声乐谱
Scale音阶:
音阶是音符的一个子集,常用的音阶有四种,分别是:Major Scale(大调音阶)或Minor Scale(小调音阶)、Harmonic Minor Scale(和声小调音阶)、Melodic Minor Scale(旋律小调音阶)、Blues scale(布鲁斯音阶)(给个简单的说法,好记的:C大调,就是从C音作1开始 ;c小调,就是从C音作6开始)。每一个音阶指定了一系列相对的间隔,这些间隔和起始音符相关。例如:大调音阶(Major)的序列是:2—2—1—2—2—1,C大调指定的起始音符是C,结合大调音阶的间隔序列,结果就是C Major(C大调)。 因此C大调指定的音符子集就是:CDEFGAB(7个音符)。所有的音阶都有一个7个音符的子集,除了布鲁斯,它有六个。总共有48个不同的音阶,也就是四种音阶,每个音阶都可能从12个音符中的任意一个开始(4*12)。我们将Major和Minor看成是同一种,因为对于任意一个Major,都有一个Minor和它使用同一组音符,这叫关系小调。
Chords和弦:
和弦是一组听起来不错的音符,和音阶相同,每一个和弦都有一个起始音符和一组定义间隔的序列组成,三和弦(三和弦是由三个音组成)主要有6种,他们是Major Chords, Minor Chords, Augmented Chords, Diminished Chords, Suspended 2nd Chords, and Suspended 4th Chords。(来自百度百科的解释:如果按照和弦组成音之间的音程结构来分类,又可分为大和弦major Chords、小和弦minor Chords、增和弦augmented Chords、减和弦diminished Chords四种形态,挂留和弦suspended Chords最常见的做法是将三和弦的3音升高半音或全音,使之距根音为纯4度所形成的和弦sus4 Chords。挂留和弦会带来紧张的感觉,所以在和弦的弹奏上,常搭配原来的三度音程,以缓和紧促之感)
The Circle of Fifths:
The Circle of Fifths经常被用于产生一个和弦的progression,它将12和弦的开始音符连接成一个圆,当需要从一个和弦转到另一个和弦的时候,转到在这个圆中相近的和弦是最好的,这样比较和谐,有很强的和弦过渡。
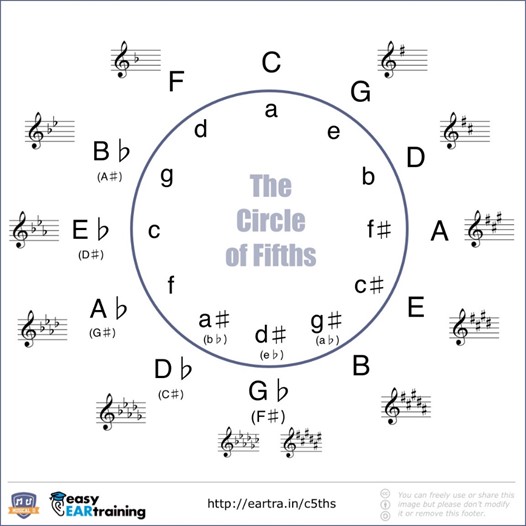
图12 The Circle of Fifths
层叠循环神经网络用于音乐生成
我们使用Song From Pi的思想(主要是将Melody、Chords、Drums三者分开)去构造我们的网络,我们使用层级的循环神经网络去生成流行音乐,这个网络将我们前面所提到的音乐理论编码进去,下面,我们首先从整体上介绍了我们的模型,之后介绍其中的一些细节和证明。
我们通过音阶来区分所不同的音乐,这帮助模型去根据流行音乐选择规则。对于每一个时间片(原文为Time Step,可以理解为RNN或者LSTM中的一个时刻t),我们使用两个随机的变量去编码Melody,第一个变量分别代表哪一个琴键被按下(Key 层),第二个变量代表这个琴键被按下的时长(Press 层)。Melody是以音阶为条件产生的,在一首音乐中音阶是不会变的,这也是普通流行音乐所遵循的规律。我们认为节拍(Drums)与和弦(Chords)和Melody是独立的,因此我们的网络根据Melody,在每一个时间片中来生成和弦(Chords层)和节拍(Drums 层),所有层的输出构成了整个歌曲,图1-3展示了我们的网络结构:
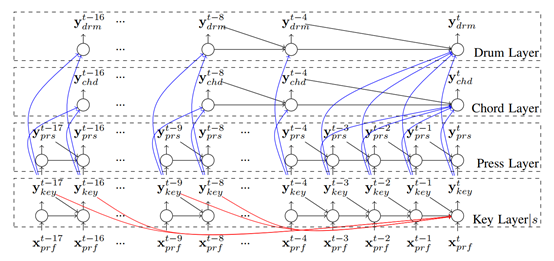
图13 网络结构(只画出了t时刻的Skip Connection,图中带颜色的线)
音阶的作用
在乐理里面,一首歌是由12个音符组成的,但实际上一般是由6个(布鲁斯)或者7个音符组成的,这6个或者7个音符是12个音的子集。我们发现,如果以音阶为条件去生成音乐,模型能够更好的抓住这些规则,但是我们并没有(像Kang一样)对某些音符进行加强。
为了证实上面的假设,我们分析了100小时的流行音乐,数据来自midi_man数据集。由于音阶是由第一个音符所定义的,为了降低不同音阶的影响,并完成归一化,我们将所有的音乐都归一到同一个音阶上。为了确定一个乐曲的音阶,我们对12个音的乐曲进行了直方图分析,然后把它对应到上面所说的48音、4种音阶、还有12个不同起始音符的音乐上。然后我们通过一个统一的平移(对应位置关系不变,整体平移)将音乐归一化到起始音符是C的音阶。这样我们就能够将所有的音乐归一到4个音阶(实际上,每个音阶是可以从12个音中的任意一个开始的,因此有12*4=48个,但是经过这样的归一化,我们让它全部从C开始,这样就剩下4个音阶了)。由于这个平移是对所有音符统一进行的,因此音乐的和谐性并没有改变,只是音调高低变了。我们的分析显示:大调音阶中94.66%的音符都有匹配,对于声小调、旋律小调和布鲁斯(Harmonic Minor, Melodic Minor, and Blues),这个比例是87.16%、85.11%和90.93%,结果如图1-4所示,图1-4中的x轴表示一首歌中音符在这个音阶中的比例,y轴表示对于这个比例,在这个数据集中共有多少比例的乐曲(这个主要是说,我们这样选是有原因的,这样的话,大部分的乐曲其实没多少变换)。值得注意的是,大部分的音符遵循音阶的规则,此外,不同的音阶类型有不同的内围分布。因此我们用一个随机变量s{1、2、3、4}来表示不同的音阶,这个表示音阶的随机变量,对于整首乐曲都是一样的,网络模型也是以它为条件的(网络模型图1-3右下角)。
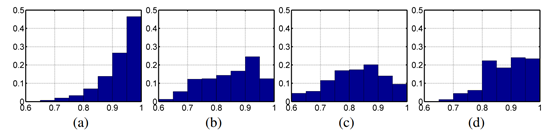
图 14 四种不同音阶在此归一化音阶中的比例
两层的RNN
对于每一个时间片,我们用两个随机变量来表示Melody,这两个随机变量分别表示:哪个琴键被按下、按下的时间是多长。首先,我们根据不同的音阶用一个循环网络来生成哪个琴键被按下(Key layer),然后根据这个RNN网络的输出,也就是第一个变量,我们用另一个RNN去生成按下的时间是多长(Press Layer)。这篇论文中,我们借助了LSTM的优势,同时使用的也是最基本的LSTM(单层的),这种LSTM的功能是计算一个输入xt的隐含状态ht,具体过程如下:
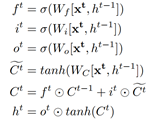
其中参数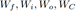
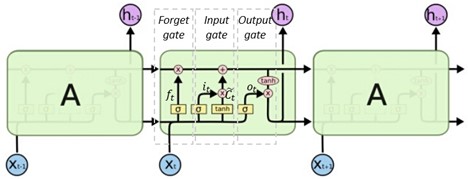
图15 LSTM的基本结构
具体来说,我们的Key layer(那个琴键被按下的层)是由一个两层的LSTM组成的,这个网络包含512维的隐含状态(hidden state)。在每个时间片中,这个网络会输出一个音符(代表哪个琴键被按下),由于我们是基于音阶s(前面的参数s)来生成的,因此不同的音阶会有不同的值。我们让生成的音符处于C3和C6之间,主要是因为其他的音符通常来说太高或者太低了。要提醒读者的是:对于一个给定的音阶,从统计意义上说,7个音符(对于布鲁斯是6个)的音乐听起来是比较优美的,但是我们让模型从整个12个音符里面选,而不是7或6个,这样的话,网络的输出就是37维,(3个八度音阶,每个有12个音符,加上一个silence(没有声音,应该是0,休止符))
我们用htKey来表示第t时刻的第二个Key decoder的隐含状态(hidden state),然后使用softmax来计算每一个音符被使用的概率:
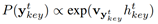
其中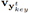
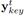
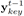
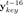
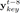
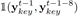
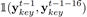
此外,我们用了一个新的Feature,我们把它称作Melody profile(音乐的整体结构)。直观的讲,这个特征从更高的层面上表示了音乐,为了获得这个特征,我们计算当前时间片周围两个bar范围内的音符直方图。并使用K-means对这些局部直方图进行了10个类的聚类。我们首先对直方图内部进行求平均,然后用这个平均值对直方图进行排序,从1到10,同时对聚类ID使用移动平均数来使局部音乐的过渡更加平滑。这样的话,我们就得到了一个10维的one-hot编码,这个编码表示对于每一个时间片的聚类ID。这个附加的信息可以让使用者设置音乐的起伏。
仅仅有琴键的信息是不足以表示整个音乐的,我们还需要知道这个琴键被按下的时间是多长。为了生成这个时间长度,我们根据Melody的信息,使用一个两层的,包含512维隐含状态的LSTM去生成每个琴键被按下的时间。我们使用一个正向计数的序列来表示按下的时间,当网络输出1的时候,表示琴键被按下,如果网络继续输出2、3、4就表示琴键一直被按下。当琴键被抬起时,这个数字恢复为1。和Waite等人使用事件开关的方法对比起来,我们的方法能够学习音乐的流淌模式,并且能够知道如何单独按键,这个很重要,由于Waite使用了上面的那种方法(Introduction中的),它使琴键按下时间的分布严重不平衡(主要是被重复和保持事件所占据)。我们将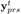
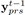
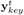
Chords和Drums 层
我们研究了那100小时音乐中所有的和弦Chords,尽管理论上一个和弦可以是由任意的一些音符随机组成,但我们发现,在实际的音乐中,99%以上的音乐所使用的和弦是72种(6种*12个起始音符)和弦之一。图1-6显示了Melody的音调和和弦的起始音符之间的关系。从结果中我们可以看出,和弦和Melody的关系是非常强的。这两项发现给我们模型的设计带来了很大的启发。因此我们将表示和弦的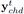
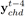
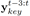

图16 主旋律起始音符与和弦起始音符的关系
我们从数据集中发现,所有Drums的模式是持续半个bar(一个bar是8个音符)。之后我们又统计了所有模式的直方图,他们形成了一个长尾的分布,有94.6%的Drums都使用的是前100种常用的Drums。我们根据Key layer,使用了一个两层的包含512个隐藏状态的LSTM去生成Drums。Drums表示为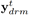
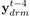
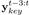
训练
我们使用交叉熵损失去训练每一层,并使用了典型的训练策略,即:在每一层的每一个时间片中都做出预测,但将最可信的结果送到下一个环节。这样明显的分解了模型的训练,同时也允许并行地训练所有的层。我们使用了Adam,学习速率是2*e-3,并且在前10个epoch中,每次都做了0.99的学习率降低。
音乐合成
在合成音乐的时候,首先我们随机的选择一个音阶和一个profile(Melody的一个全局信息)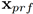
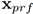
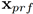
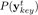
在将所有层的输出结合起来之前,首先我们要进一步对生成的序列在bar级别上的调整,对于Melody来说,我们首先检查每一个bar,看其第一个时间片是不是与前面的时间片具有连续性,或者是一个silence(休止符)。如果是silence,我们找到在这个bar中的之后被最先按下的音符,并且把它移动到bar的开头。我们对不同大小的窗口范围(两个half-bar、四个quarter-bars)都做了这样的操作,这样可以使Melody更加合拍、听起来也更加优美,在实验中我们对此进行了验证。
对于Chords,每半个bar的时间,我们生成一个Chords,这也是大部分单步和弦生成的情况。此外,我们将Circle of fifths的规则结合了进来,作为和弦之间的平滑项。最终的和弦是通过动态编程(dynamic programming)计算出来的。对于Drums,我们在每半个bar的时候生成一个Drums。
我们的模型所生成的音乐是以C为音阶的,然后使用平移来生成以其他音符开始的音乐,除了音阶,使用哪种乐器也是可以进行设置的。然而我们简单的使用了钢琴,其中一部分原因是,不同乐器结合的效果以及其对音乐的意义不在本文的讨论范围之内。
实验
比较简单,此处省略。
结论
我们提出了一种层叠的LSTM来生成流行音乐,在模型结构的设计中,结合了乐理。和前辈们的工作相比,我们的方法可以生成多轨的音乐,Human Study实验证明了我们的方法优于Google的BaseLine方法。此外,我们设计了两个新的应用:neural dancing & karaoke和 neural story singing。最后我们讨论了此方法局限和未来的研究方向——现在大多数音乐生成方法的目标都是生成音符级别的旋律,但这对于真正的音乐是不合适的,毕竟真正的音乐是那么的多变,且在其谱曲过程中是故意另其不可预测的。生成真正的音乐需要对乐理更深的研究,在这篇文章里面,我们只是触碰到了表面。
音乐术语
和弦 chords
和声 harmony
旋律 (melody)
十二音(Twelve-tone)
音阶 (scale)
单音(single note)
单轨、多轨(multi-track)
音符(note)













 2680
2680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









