







odps官方文档之给出了jdbc最原始的查询。我们当然不会直接用jdbc,不然工作量太大。
因为查询出来的都是列,需要自己封装成对象。
因此考虑到odps本身也是数据库,那么我们依旧可以使用mybatis来查询odps。
唯一需要更改的就是DataSource。
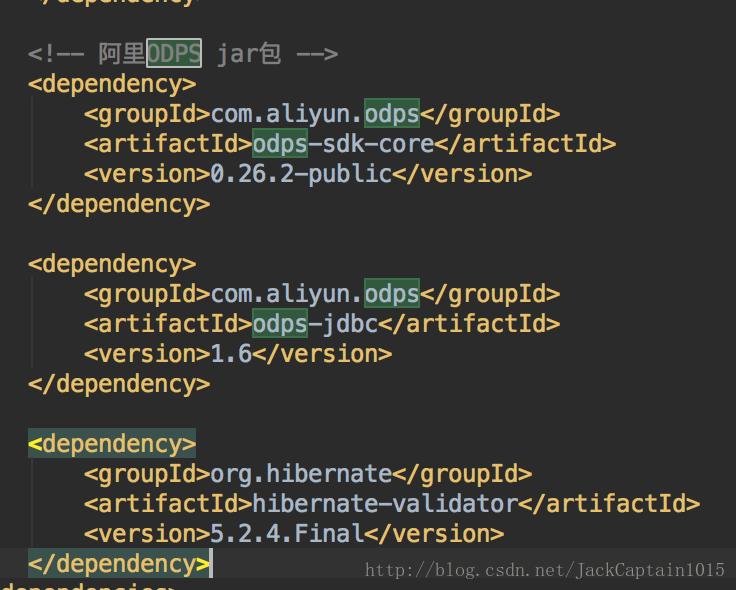
odps需要jar包:
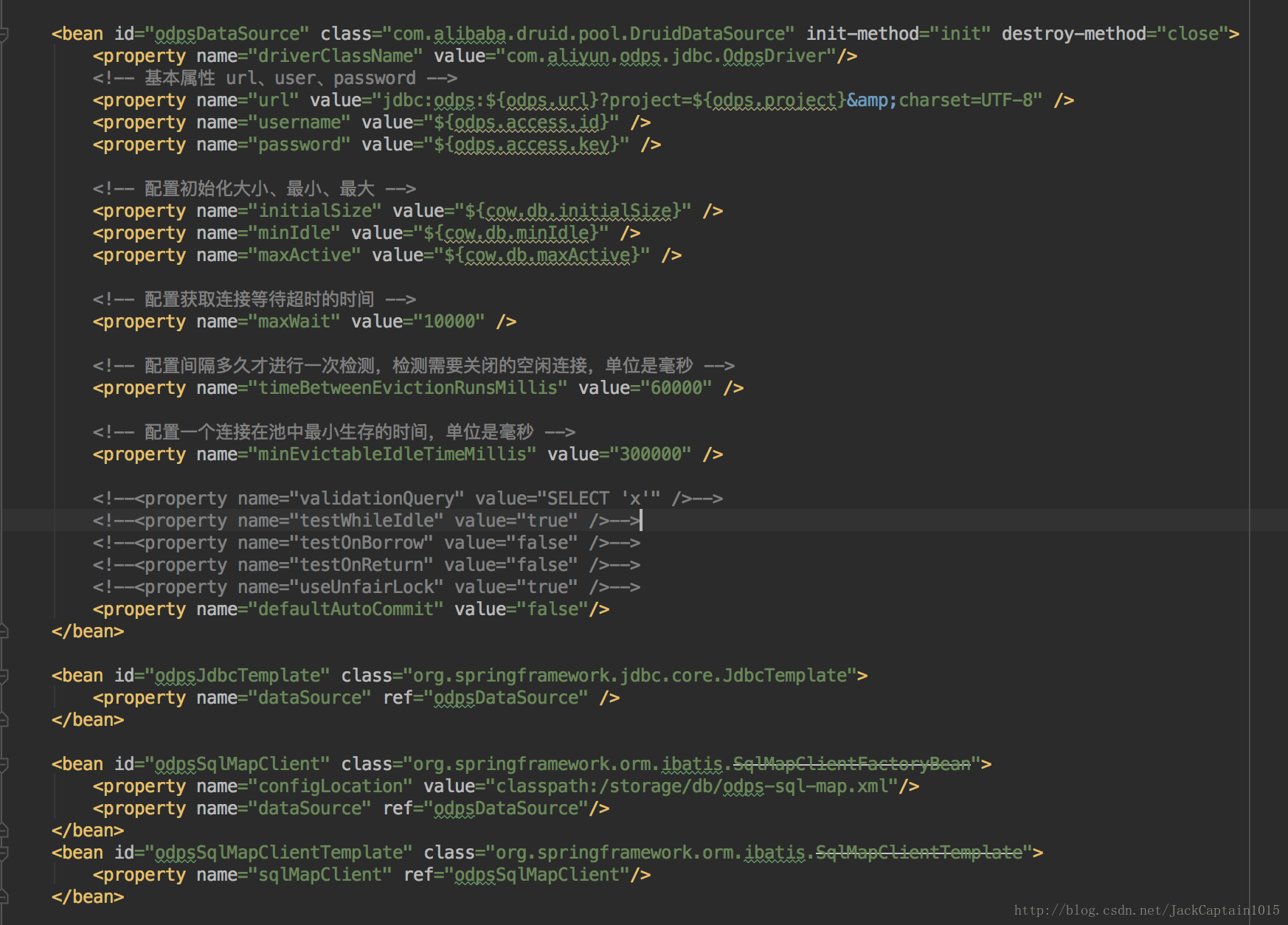
odps_datasource.xml:(这里使用的DruidDataSource,换成C3P0也行)
因为odps不支持事务,所以OdpsConnection.java中

而Odps与DataSource结合,每次执行odps搜索,虽然依旧会运行成功,但每次都会报
SQLFeatureNotSupportedException(运行时异常)。
解决方法:
建立自己的maven私有仓库。然后下载github上面的OdpsJdbc源码(https://github.com/aliyun/aliyun-odps-jdbc)
自己修改OdpsConnection中的rollback()等方法,然后发布到自己的nexus。














 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









