






众所周知,大数据这个概念已经热炒了3年多,现在终于慢慢冷静下来也成熟起来,也意味着真正进入应用阶段。任何系统、任何公司的核心都是数据。目前社会最具发展前景的行业,现在流行hadoop,Hadoop是Apache软件基金会管理的开源软件平台,但Hadoop到底是什么呢?简单来说,Hadoop是在分布式服务器集群上存储海量数据并运行分布式分析应用的一种方法。
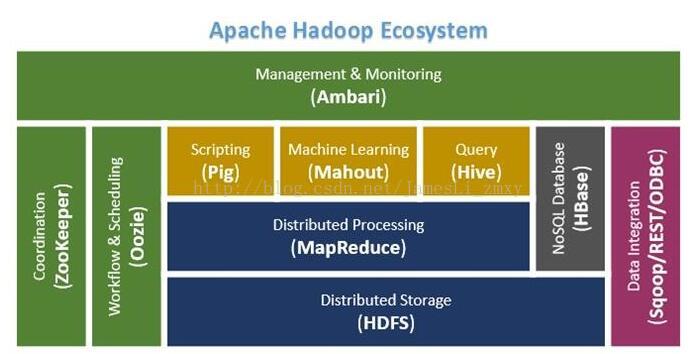
以下是Apache的正式定义:
Apache Hadoop软件库是一个框架,允许在集群服务器上使用简单的编程模型对大数据集进行分布式处理。Hadoop被设计成能够从单台服务器扩展到数以千计的服务器,每台服务器都有本地的计算和存储资源。Hadoop的高可用性并不依赖硬件,其代码库自身就能在应用层侦测并处理硬件故障,因此能基于服务器集群提供高可用性的服务。
如果更深入地分析,我们发现Hadoop还有更加精彩的特性。首先,Hadoop几乎完全是模块化的,这意味着你们能用其他软件工具抽换掉Hadoop的模块。这使得Hadoop的架构异常灵活,同时又不牺牲其可靠性和高效率。
Hadoop分布式文件系统(HDFS)
如果提起Hadoop你的大脑一片空白,那么请牢记住这一点:Hadoop有两个主要部分:一个数据处理框架和一个分布式数据存储文件系统(HDFS)。
HDFS就像Hadoop系统的篮子,你把数据整整齐齐码放在里面等待数据分析大厨出手变成性感的大餐端到CEO的桌面上。当然,你可以在Hadoop进行数据分析,也可以见gHadoop中的数据“抽取转换加载”到其他的工具中进行分析。
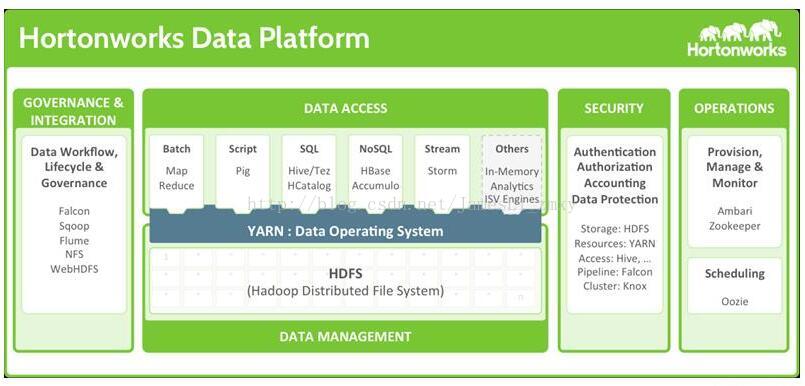
数据处理框架和MapReduce
顾名思义,数据处理框架是处理数据的工具。具体来说Hadoop的数据处理框架是基于Jave的系统——MapReduce,你听到MapReduce的次数会比HDFS还要多,这是因为:
1.MapReduce是真正完成数据处理任务的工具
2.MapReduce往往会把它的用户逼疯
在常规意义上的关系型数据库中,数据通过SQL(结构化查询语言)被找到并分析,非关系型数据库也使用查询语句,只是不局限于SQL而已,于是有了一个新名词NoSQL。
有一点容易搞混的是,Hadoop并不是一个真正意义上的数据库:它能存储和抽取数据,但并没有查询语言介入。Hadoop更多是一个数据仓库系统,所以需要MapReduce这样的系统来进行真正的数据处理。
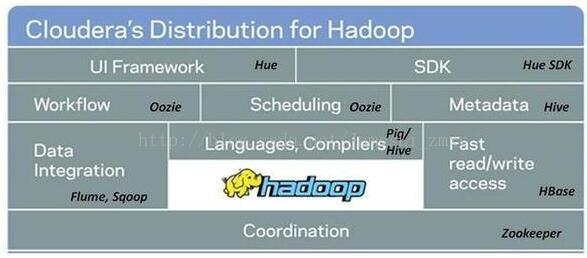
MapRduce运行一系列任务,其中每项任务都是单独的Java应用,能够访问数据并抽取有用信息。使用MapReduce而不是查询语言让Hadoop数据分析的功能更加强大和灵活,但同时也导致技术复杂性大幅增加。
目前有很多工具能够让Hadoop更容易使用,例如Hive,可以将查询语句转换成MapReduce任务。但是MapReduce的复杂性和局限性(单任务批处理)使得Hadoop在更多情况下都被作为数据仓库使用而非数据分析工具。
Hadoop的另外一个独特之处是:所有的功能都是分布式的,而不是传统数据库的集中式系统。














 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









